I will add the following to the discussion:
If past history with customers of JON/users of RHQ/salespeople is any indication, we will get requests to support collecting availability every second (if not every sub-second) even AFTER telling people, documenting, and shouting from the mountaintop that we are not a realtime profiler. So, do we have the throughput/infrastructure that can support one "UP" datapoint coming in every minute for N resources. Do we want to support this?
It seems like this should be a question of scale. Do we provide the scalability both in terms of storage and in terms of processing data to deal with those scenarios? Our strategy around scalability is a topic in its own right, but I do think it is relevant to some of the questions being raised in this thread.
Resource #1: 11:00:01 UPResource #1: 11:00:02 UPResource #1: 11:00:03 UPResource #1: 11:00:04 UP...56 datapoints later....Resource #1: 11:01:00 UPResource #1: 11:01:01 UPResource #1: 11:01:02 UP... and on ... and repeat for Resource #3, #5, etc (not every resource, but many of them).Perhaps we store data like this, but only quickly aggregate them (say, every hour, aggregate this data into a tuple like "UP, 11:00:01, 11:01:02" where that is "avail state, begin time, end time").I also find the pattern of the typical avail state of resources should be considered when designing the best storage schema for availability data (i.e. changes are very infrequent in between large amounts of time where the avail state is the same - "UP UP UP UP UP ... UP DOWN DOWN DOWN DOWN ..." - what's the best way to store that?). Storing just state changes has problems as we know (e.g. with alerts - we can only alert on state changes, like "Going UP" or "Going DOWN" not to mention what about admin states like "maintenance".----- Original Message -----
I think this comes down more to what we *can* record. As we discussed a
little bit in the past [1], the Hawkular model is not the RHQ model, meaning
there is no heavy external agent performing scheduled avail checks and
maintaining avail state for all of the resources. There may optionally be a
lightweight agent checking a subset of resources for live-ness, the basic
approach will be a push model, with feeds sending avail info as they see
fit, for only the resources they see fit. And we have H Metrics doing the
storage, which means no updates of current state, instead, just write values
as they stream in. This results in Avail storage that will likely be more of
what Micke is talking about, a lot of data points (most likely a lot of UP),
very likely not just at the times of avail change.
We can do a couple of things with this data. It could be aggregated and
stored as change intervals in the persistence layer (as a feature of H
Metrics perhaps), and lose the individual data points. It can, at query time
for an interval, be aggregated into change intervals, and also maintain the
collection granularity.
Th decisions made here have a lot of impact on alerting, because at the
moment the basic avail alerting use cases are not actually covered. Take
Catherine's "basic" use-cases:
1. As an administrator of a website, I would like to configure Hawkular
so an alert is sent to me every time the system goes down.
2. As an administrator of a website, I would like to configure Hawkular
so an alert is only sent to me after the system is down for a certain
length of time, so I'm not alerted if there is a very minor downtime
event.
Case-1 is more subtle than it looks. This, I think, does not mean that the
admin wants to be alerted every time the system is *reported* down, but
rather when it goes down. This sort of alerting was easy in RHQ because we
were only notified of changes in availability. "Goes DOWN" as opposed to "Is
DOWN". In Hawkular we are likely talking about "Is DOWN", or possibly even
the lack of "Is UP" reports. It's unclear yet, but we may need to somehow
infer that something is down if it does not report "Is UP" for some period.
In a push-oriented feed (like a ping), if something goes physically down it
won't be able to report at all. Case-2 can't really be definitively solved
until case-1 is well-defined.
At the moment alerting can fire an alert on every "Goes DOWN" report, or
apply various dampening to those events. It can not guarantee a single alert
for a specific down event unless the feed itself reports only changes in
avail. Although, it can actually Having said that, we will shortly be
looking at how to replace the "recovery-alert" logic of RHQ.
[1] https://developer.jboss.org/message/915970?et=watches.email.thread#915970
On 2/16/2015 4:49 AM, Thomas Heute wrote:
On 02/13/2015 11:18 PM, Michael Burman wrote:
Hi,
I disagree, seeing this pattern first hand in resulting large penalty
payment on one case (inability to prove that monitoring reported up on
certain time when it wasn't responsive). If there's a need to monitor
availability, there must be recorded event flow, eg:
Up 11:00
Up 11:05
Up 11:10
Down 11:15
Down 11:20
Up 11:25
And why? If we only record:
Up 11:00 - 11:10
Down 11:15 - 11:20
Up 11:25 - ..
There's a difference. Did the monitoring system report 11:05 or was the
monitoring system down 11:05? In many cases a need to prove that system
was in certain state in certain times. Especially when there are SLA
disagreements. Even more importantly, what happened between 11:10 -
11:15 and 11:20 - 11:25?
Recording all datapoints doesn't give you more information on what
happened between 2 recordings though.
But I get your point on the "inability to prove that monitoring reported
up on certain time when it wasn't responsive".
I didn't see availability recording as SLA proofs though.
The SLA behaviour requires that some system noticed something happening
at certain point of time. And if there's issues with system
responsibility say at 11:05, there needs to be a event showing that the
system really did report up.
You can't prove that system is up and running at a special point in
time, you can only prove over a period of time if you made enough checks
(interval lesser than the period of time of the SLA).
Thomas
- Micke
On 13.02.2015 14:01, Thomas Heute wrote:
Getting back to availability discussion...
To me availability is a set of periods, not so much "time series" and
we should just record change of status (closing the previous event and
opening a new one).
- Server is up from 8:00am to 11:30am
- Server is down from 11:30am to 11:32am
- Server is unknown from 11:32am to 12:00pm (an agent running on a
machine can tell if a server is up or down, if the agent dies then we
don't know if the server is up or down)
- Server is in erratic state from 12:00pm to 12:30pm (agent
reports down every few requests)
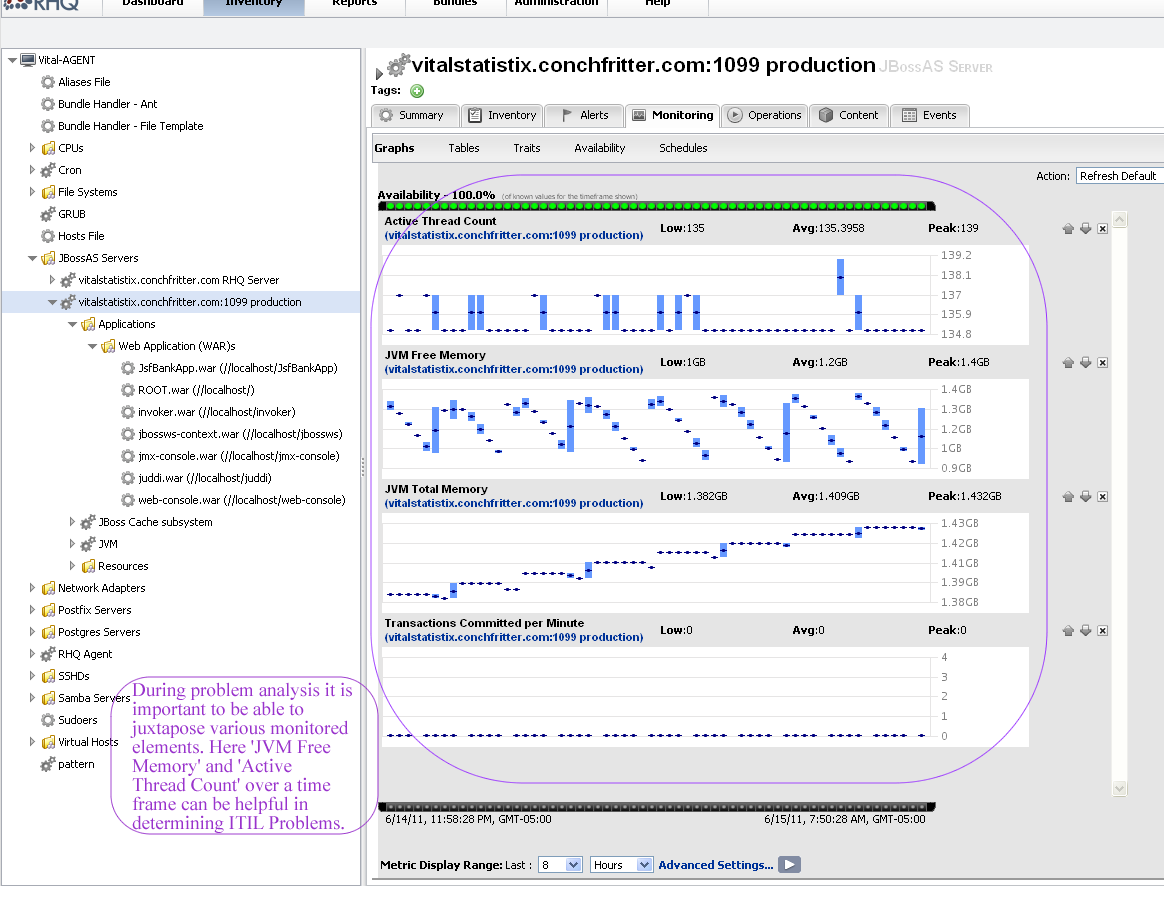
We were discussing the best way to represent availability over time in
a graph, representation in RHQ [1] is very decent IMO, can be extended
with more colors to reflect how often/long the website was down for
each "brick" (if the line represent a year with 52 blocks, 1 block can
be more or less red depending on how long it was done during the week).
But thinking of it more, availability graph is not that interesting by
itself IMO and more interesting in the context of other values.
I attached a mockup of what I meant, a red area is displayed on
response time graph, that means that the system is down, obviously
there is no response time reported anymore in that period. Earlier
there is an erratic area, seems related to higher response time ;)
Rest of the time the system is just up and running...
Additionally I would want to see reports of availability:
- overall availability over a period of time (a day, a month, a
year...). "99.99% available in the past month"
- lists of the down periods with start dates and duration for a
particular resource or set of resources (filtering options)
Thoughts ?
[1]
http://3.bp.blogspot.com/-0MsmG5h5i5E/TfjTMZlvx3I/AAAAAAAAABU/6PKDs0RlzuI/s1600/ProblemManagement-RHQ.png
Thomas
_______________________________________________
hawkular-dev mailing list hawkular-dev@lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
_______________________________________________
hawkular-dev mailing list hawkular-dev@lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
_______________________________________________
hawkular-dev mailing list hawkular-dev@lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
_______________________________________________
hawkular-dev mailing list
hawkular-dev@lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
_______________________________________________hawkular-dev mailing listhawkular-dev@lists.jboss.orghttps://lists.jboss.org/mailman/listinfo/hawkular-dev
{kind=link}