Re: [Hawkular-dev] Availability

On 20 Mar 2015, at 17:42, John Sanda wrote:
Great point about multiple resources. I have to therefore slightly
refine my previous statement. I think that the functionality belongs
on the agent. As I said in the agent discussions, I think that there
are use cases for different types of agents - embedded, c-located, and
remote. For the example of monitoring availability for a resource (or
resources) spanning several machines, I think it should be the job of
a remote agent. Maybe that remote agent is running inside the hawkular
server. I am not sure. They key though is that the approach is
consistent in terms of who is applying that availability function.
I have been talking about "cheap alert pre-computation" on the
agent in the past, and this certainly makes sense. But it also
opens a can of worms^w complexity, that we should not tackle
in the first place.
The other question is what do we do with raw-avail-data-sources,
that are not delivered by an agent we write, but e.g. via curl?
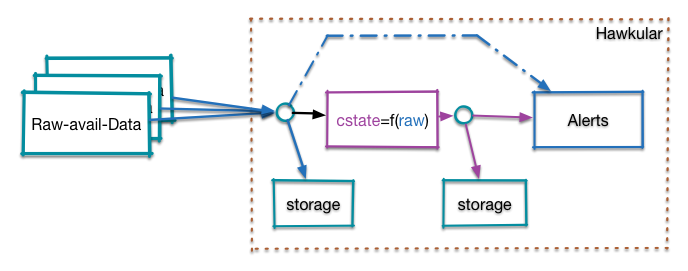
For now I propose to do the computation on the server side.
Attached image illustrates this. All incoming "raw" data (that should
be used for alerting / computed resource state) is
* stored in e.g. Hawkular-Metrics
* run through the function that e.g. determines that a http status code
500 means DOWN
or a duration > 300ms means WARN
* the result of the function is then also stored and forwarded to
alerting
and other users.
We would of course need to provide default-functions, but with the
possibility to
fine-tune them.
Attachments:
- avail_function.png (image/png — 60.7 KB)
{kind=link}