
1:42 a.m.
Hey,
tl;dr: we need to investigate heap usage - especially in the case of
compression
kicking in - it looks like there could be a memory leak. Compression
timing seems
mostly ok.
I originally wanted to see how more feeds influence the metrics
compression timing.
So I started the server with -Xmx512m as I did in all the weeks before
and pointed a
few feeds at the server - to see it crash with OOME shortly after the
compression started.
Now I restarted the server with -Xmx1024m and also
-XX:MaxMetaspaceSize=512m (up from 256m before) and am running the
server now with 1 feed for a day.
To be continued below ...
( Time is in GMT, which is 2h off of my local time)
hawkular_1 | 15:00:44,764 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 15:00:45,452 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
687 ms
hawkular_1 | 17:00:44,757 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 17:00:46,796 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
2039 ms
hawkular_1 | 19:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 19:00:47,293 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
2541 ms
hawkular_1 | 21:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 21:00:46,267 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1517 ms
hawkular_1 | 23:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 23:00:45,472 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
722 ms
hawkular_1 | 01:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 01:00:46,241 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1492 ms
hawkular_1 | 03:00:44,747 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 03:00:45,780 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1033 ms
hawkular_1 | 05:00:44,746 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 05:00:45,781 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1034 ms
hawkular_1 | 07:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 07:00:46,386 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1636 ms
hawkular_1 | 09:00:44,748 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 09:00:45,682 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
934 ms
hawkular_1 | 11:00:44,750 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 11:00:46,339 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1589 ms
hawkular_1 | 13:00:44,748 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 13:00:45,880 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
1132 ms
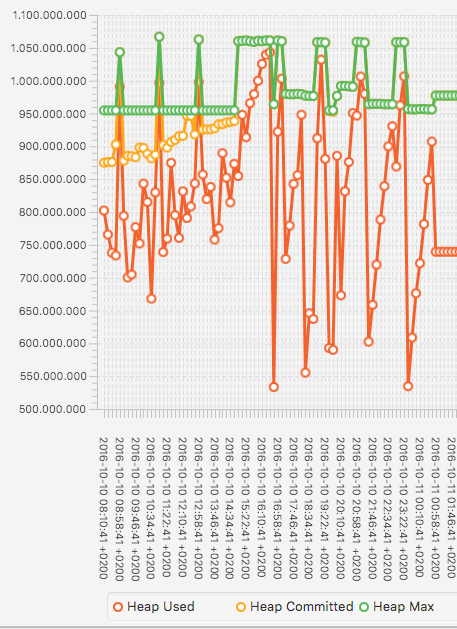
Looking at the memory usage I see the memory usage there is often a peak
in heap usage around and after the compression - looking at the
accumulated GC-time also shows heavy GC activity. I guess the peak in
heap usage (and thus committed heap) comes from promoting objects from
young generation into old during the compression and then later after
compression is over, they are garbage collected, so that heap usage goes
down and the system is able to free some memory.
Starting at around 4:10pm (2pm in the above output) I am running with 10
extra feeds (hawkfly on an external box)
While it looks like there is a slowly growing non-heap, it was growing a
lot when the 10 extra feeds connected.
Also it looks like it is growing a bit more each time compression kicks
in ("non-heap")
The first compression run with 11 feeds did not take too long, the next
was
hawkular_1 | 17:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 17:00:50,277 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
5528 ms
Which used a lot more memory than before. Non-heap was able to reclaim
some memory though.
hawkular_1 | 19:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 19:00:50,093 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
5341 ms
hawkular_1 | 21:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 21:00:49,465 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
4714 ms
hawkular_1 | 23:00:44,753 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 23:00:48,925 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
4171 ms
hawkular_1 | 01:00:44,750 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 01:00:48,554 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
3803 ms
hawkular_1 | 03:00:44,761 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 03:00:48,659 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
3898 ms
hawkular_1 | 05:00:44,748 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 05:00:49,134 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
4385 ms
hawkular_1 | 07:00:44,755 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 07:00:49,831 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
5076 ms
hawkular_1 | 09:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 09:00:49,508 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
4757 ms
Now at 11:20 (9:20 for above logs) I started 5 more feeds (with a 2min
sleep between starts)
hawkular_1 | 11:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 11:00:49,751 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
5002 ms
hawkular_1 | 13:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 13:00:56,594 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
11845 ms
hawkular_1 | 15:00:44,754 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 15:00:53,985 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
9231 ms
And another 5 starting at 17:12 (15:00 in above logs timezone)
hawkular_1 | 17:00:44,768 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 17:00:57,824 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
13056 ms
And another 5 starting at 19:57 (17:57 in above log timezone )
hawkular_1 | 19:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 19:01:24,401 WARN org.apache.activemq.artemis.ra AMQ152007:
Thread Thread[TearDown/ActiveMQActivation,5,] could not be finished
hawkular_1 | 19:01:40,918 WARN org.apache.activemq.artemis.ra AMQ152007:
Thread Thread[TearDown/ActiveMQActivation,5,default-threads] could not
be finished
hawkular_1 | 19:02:04,619 WARN org.apache.activemq.artemis.ra AMQ152007:
Thread Thread[TearDown/ActiveMQActivation,5,default-threads] could not
be finished
hawkular_1 | 19:02:22,423 WARN org.apache.activemq.artemis.ra AMQ152007:
Thread Thread[TearDown/ActiveMQActivation,5,default-threads] could not
be finished
hawkular_1 | 19:02:30,247 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data in
105495 ms
This took almost 2 minutes, where the server was non-responsive
21:00:44,753 INFO org.hawkular.metrics.core.jobs.CompressData Starting
execution
21:01:06,520 INFO org.hawkular.metrics.core.jobs.CompressData Finished
compressing data in 21767 ms
23:00:44,751 INFO org.hawkular.metrics.core.jobs.CompressData Starting
execution
And here it went south and the server more or less died with OOME
exceptions (it is still responding to queries, and potentially even
ingesting new data, but the scheduler seems not to run anymore.
I can imagine that once the OOME happened, the scheduler thread died,
freeing up memory that the compression job held and which then allowed
the server itself to continue. But it certainly is in an unusable state.
This is the final "one day" with "max" values plotted:

The peaks at compression time for heap-max (green line) are clearly
visible.
{kind=link}

5:57 a.m.
Hi,
There's on going discussions and more data coming from Heiko, but since
not everyone might be online, I'll fill in here as well..
Testing with the Hawkular-Metrics (not services), I can't repeat these.
I started by testing just the compression library and after compressing
some 9 billion datapoints, I was still running constant ~10MB heap usage.
So I started HWKMETRICS in Wildfly 10.0.0.Final and ran with our
load-test, gatling and clients=20, metrics=1000 and loops enough to keep
it running forever. The instance was modified to run with 20 minutes
interval of compression.
Monitoring with jconsole, I can't see any difference in memory usage
from first 5 minutes to the last 5 minutes (running for two hours now).
It's running between 147MB of memory and 400MB.
Requires more investigation then..
- Micke
On 10/11/2016 09:42 AM, Heiko W.Rupp wrote:
Hey,
tl;dr: we need to investigate heap usage - especially in the case of
compression
kicking in - it looks like there could be a memory leak. Compression
timing seems
mostly ok.
I originally wanted to see how more feeds influence the metrics
compression timing.
So I started the server with -Xmx512m as I did in all the weeks before
and pointed a
few feeds at the server - to see it crash with OOME shortly after the
compression started.
Now I restarted the server with -Xmx1024m and also
-XX:MaxMetaspaceSize=512m (up from 256m before) and am running the
server now with 1 feed for a day.
To be continued below ...
( Time is in GMT, which is 2h off of my local time)
hawkular_1 | 15:00:44,764 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 15:00:45,452 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 687 ms
hawkular_1 | 17:00:44,757 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 17:00:46,796 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 2039 ms
hawkular_1 | 19:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 19:00:47,293 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 2541 ms
hawkular_1 | 21:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 21:00:46,267 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1517 ms
hawkular_1 | 23:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 23:00:45,472 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 722 ms
hawkular_1 | 01:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 01:00:46,241 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1492 ms
hawkular_1 | 03:00:44,747 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 03:00:45,780 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1033 ms
hawkular_1 | 05:00:44,746 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 05:00:45,781 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1034 ms
hawkular_1 | 07:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 07:00:46,386 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1636 ms
hawkular_1 | 09:00:44,748 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 09:00:45,682 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 934 ms
hawkular_1 | 11:00:44,750 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 11:00:46,339 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1589 ms
hawkular_1 | 13:00:44,748 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 13:00:45,880 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 1132 ms
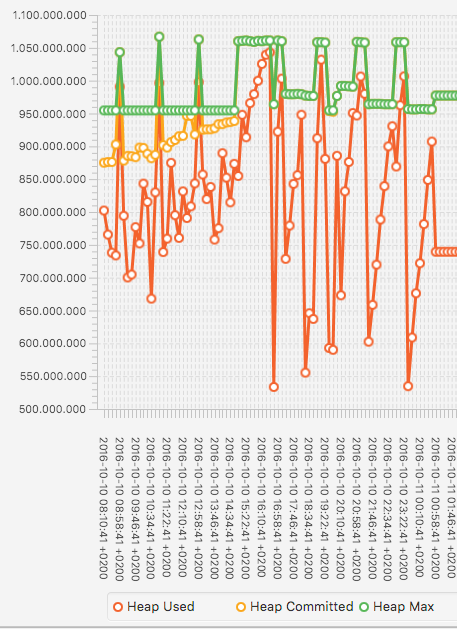
Looking at the memory usage I see the memory usage there is often a
peak in heap usage around and after the compression - looking at the
accumulated GC-time also shows heavy GC activity. I guess the peak in
heap usage (and thus committed heap) comes from promoting objects from
young generation into old during the compression and then later after
compression is over, they are garbage collected, so that heap usage
goes down and the system is able to free some memory.
Starting at around 4:10pm (2pm in the above output) I am running with
10 extra feeds (hawkfly on an external box)
While it looks like there is a slowly growing non-heap, it was growing
a lot when the 10 extra feeds connected.
Also it looks like it is growing a bit more each time compression
kicks in ("non-heap")
The first compression run with 11 feeds did not take too long, the
next was
hawkular_1 | 17:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 17:00:50,277 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 5528 ms
Which used a lot more memory than before. Non-heap was able to reclaim
some memory though.
hawkular_1 | 19:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 19:00:50,093 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 5341 ms
hawkular_1 | 21:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 21:00:49,465 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 4714 ms
hawkular_1 | 23:00:44,753 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 23:00:48,925 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 4171 ms
hawkular_1 | 01:00:44,750 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 01:00:48,554 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 3803 ms
hawkular_1 | 03:00:44,761 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 03:00:48,659 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 3898 ms
hawkular_1 | 05:00:44,748 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 05:00:49,134 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 4385 ms
hawkular_1 | 07:00:44,755 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 07:00:49,831 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 5076 ms
hawkular_1 | 09:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 09:00:49,508 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 4757 ms
Now at 11:20 (9:20 for above logs) I started 5 more feeds (with a 2min
sleep between starts)
hawkular_1 | 11:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 11:00:49,751 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 5002 ms
hawkular_1 | 13:00:44,749 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 13:00:56,594 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 11845 ms
hawkular_1 | 15:00:44,754 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 15:00:53,985 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 9231 ms
And another 5 starting at 17:12 (15:00 in above logs timezone)
hawkular_1 | 17:00:44,768 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 17:00:57,824 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 13056 ms
And another 5 starting at 19:57 (17:57 in above log timezone )
hawkular_1 | 19:00:44,751 INFO
org.hawkular.metrics.core.jobs.CompressData Starting execution
hawkular_1 | 19:01:24,401 WARN org.apache.activemq.artemis.ra
AMQ152007: Thread Thread[TearDown/ActiveMQActivation,5,] could not be
finished
hawkular_1 | 19:01:40,918 WARN org.apache.activemq.artemis.ra
AMQ152007: Thread
Thread[TearDown/ActiveMQActivation,5,default-threads] could not be
finished
hawkular_1 | 19:02:04,619 WARN org.apache.activemq.artemis.ra
AMQ152007: Thread
Thread[TearDown/ActiveMQActivation,5,default-threads] could not be
finished
hawkular_1 | 19:02:22,423 WARN org.apache.activemq.artemis.ra
AMQ152007: Thread
Thread[TearDown/ActiveMQActivation,5,default-threads] could not be
finished
hawkular_1 | 19:02:30,247 INFO
org.hawkular.metrics.core.jobs.CompressData Finished compressing data
in 105495 ms
This took almost 2 minutes, where the server was non-responsive
21:00:44,753 INFO org.hawkular.metrics.core.jobs.CompressData Starting
execution
21:01:06,520 INFO org.hawkular.metrics.core.jobs.CompressData Finished
compressing data in 21767 ms
23:00:44,751 INFO org.hawkular.metrics.core.jobs.CompressData Starting
execution
And here it went south and the server more or less died with OOME
exceptions (it is still responding to queries, and potentially even
ingesting new data, but the scheduler seems not to run anymore.
I can imagine that once the OOME happened, the scheduler thread died,
freeing up memory that the compression job held and which then allowed
the server itself to continue. But it certainly is in an unusable state.
This is the final "one day" with "max" values plotted:
The peaks at compression time for heap-max (green line) are clearly
visible.
_______________________________________________
hawkular-dev mailing list
hawkular-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
{kind=link}
6:17 a.m.
Hi,
On 11 Oct 2016, at 12:57, Michael Burman wrote:
(running for two hours now). It's running between 147MB of memory
and
400MB.
That is a 250MB difference.
Can you try doing a full-gc right before compression start
and right after end to
and measure the heap usage at those points
(before start and at end before gc)
so that we get an idea how much memory
the compression really takes?
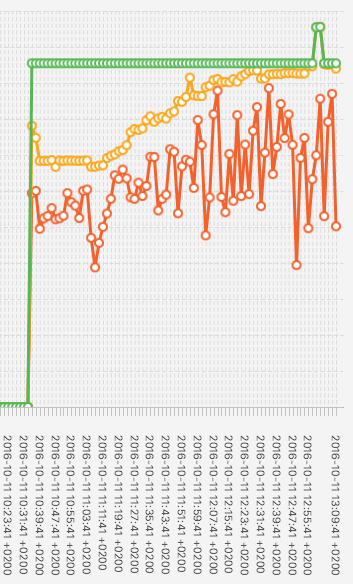
I started a 0.16 h-services at ~ 10:35, let it run until 11:13
(first compression happened at 11)
then added 25 feeds - one every 2 minutes.
The compression at 1pm went well, but the graph certainly
shows a much increased need for heap during that time.

We may perhaps try to spread out the compression over more time and thus
trade time for memory
to get rid of this large memory usage peak.
After the next crash, I will try to run with external DB for Inventory
to see how much this contributes
to the issue here.
{kind=link}
6:34 a.m.
Hi,
250MB is about the amount which the GC lets the heap live. And it grows
and shrinks all the time based on the load.
But in the end and start, the lowest point was the same.
And of course, heap requirement is increased when we do the compression,
as we load the rows from the database. That includes both the metricIds
to be compressed as well as the datapoints.
- Micke
On 10/11/2016 02:17 PM, Heiko W.Rupp wrote:
Hi,
On 11 Oct 2016, at 12:57, Michael Burman wrote:
(running for two hours now). It's running between 147MB of memory
and 400MB.
That is a 250MB difference.
Can you try doing a full-gc right before compression start
and right after end to
and measure the heap usage at those points
(before start and at end before gc)
so that we get an idea how much memory
the compression really takes?
I started a 0.16 h-services at ~ 10:35, let it run until 11:13
(first compression happened at 11)
then added 25 feeds - one every 2 minutes.
The compression at 1pm went well, but the graph certainly
shows a much increased need for heap during that time.
We may perhaps try to spread out the compression over more time and
thus trade time for memory
to get rid of this large memory usage peak.
After the next crash, I will try to run with external DB for Inventory
to see how much this contributes
to the issue here.
_______________________________________________
hawkular-dev mailing list
hawkular-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
4:55 a.m.
On 11 Oct 2016, at 8:42, Heiko W.Rupp wrote:
Hey,
tl;dr: we need to investigate heap usage - especially in the case of
compression
kicking in - it looks like there could be a memory leak. Compression
timing seems
mostly ok.
Looks like we are making some progress
- metric forwarding to alerts seems to do some memory-wise
heavy work, that can be reduced (hwkmetrics-507 and -508 and
hawkular-1130 iirc)
- internal hsqldb uses a lot of memory
- that is "only" a developer concern
- using postgres does not exhibit the memory usage for caching as does
hsqldb, but
- the postgres driver in inventory (v...1201) seems to use finalizers
too much
- we are investigating to use a newer driver that may perform
better
I just replaced in a local copy inventory 0.20 with 0.19.3 and this
seems to be
smoother sailing - a lot less finalizers that also hold less memory.
I did try to run with -XX:+UseStringDeduplication which requires
-XX:+UseG1GC, but
according to MAT it did not have an effect for me. We may want to look
into
string interning for the future like we did in JON.
12:56 a.m.
Hey,
I ran this over night with 24 feeds and the patch to
HAM wrt alert forwarding and it was stable. Had to
stop it now, but will try to pick up where I left today.
Anyway: good sign.
Thanks to all
On 14 Oct 2016, at 11:55, Heiko W.Rupp wrote:
On 11 Oct 2016, at 8:42, Heiko W.Rupp wrote:
> Hey,
>
> tl;dr: we need to investigate heap usage - especially in the case of
> compression
> kicking in - it looks like there could be a memory leak. Compression
> timing seems
> mostly ok.
Looks like we are making some progress
- metric forwarding to alerts seems to do some memory-wise
heavy work, that can be reduced (hwkmetrics-507 and -508 and
hawkular-1130 iirc)
- internal hsqldb uses a lot of memory
- that is "only" a developer concern
- using postgres does not exhibit the memory usage for caching as does
hsqldb, but
- the postgres driver in inventory (v...1201) seems to use
finalizers too much
- we are investigating to use a newer driver that may perform
better
I just replaced in a local copy inventory 0.20 with 0.19.3 and this
seems to be
smoother sailing - a lot less finalizers that also hold less memory.
I did try to run with -XX:+UseStringDeduplication which requires
-XX:+UseG1GC, but
according to MAT it did not have an effect for me. We may want to look
into
string interning for the future like we did in JON.
_______________________________________________
hawkular-dev mailing list
hawkular-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
--
Reg. Adresse: Red Hat GmbH, Technopark II, Haus C,
Werner-von-Siemens-Ring 14, D-85630 Grasbrunn
Handelsregister: Amtsgericht München HRB 153243
Geschäftsführer: Charles Cachera, Michael Cunningham, Michael O'Neill,
Eric Shander
2:38 a.m.
Update
[ tl;dr: good news ]
Lukas provided me with "connection properties" for hsqldb
that limit the memory usage and this seems stable. I have been
running h-services since Friday afternoon (~40h) with 33 HawkFly
feeds.
Two heap dumps taken yesterday afternoon and this morning
both show a stable heap size of 192M, so I think we are on the
safe side here (with hsqldb, see also below).
On top of just ingesting metrics, I have created poor mans Chaos
Monkey that randomly stops and restarts a container every 5 minutes
(parallel on 2 machines where my feeds live) to also stress the initial
sync when a feeds is (re) connecting.
I also had a (very small) number of alert triggers defined, that
were firing when heap on a hawkfly is > 60k, which happened quite
often.
This was running during the last 36h, so is included in above
heap metrics.
The MBeans for hawkular metrics show an insertion rate of around
33 metrics/s , so a HawkFly corresponds to 1metric/s.
About hsqldb: I am going to shut this down now and test with a
h2-based instance, as h2 is already in WildFly and EAP and
should be used instead of hsqldb.
Some time next week I will also try to instrument HawkFly in a away
that it automatically defines some alert triggers on startup.
2:48 a.m.
Update with h2
I only ran this for ~20h and with only 30 feeds but memory
usage was lower than with hsqldb as the h2 cache
was some 20MB smaller than with hsqldb.
This was stable during until I added at around 12h from
the start some more feeds in parallel. This needs
thus more investigation.
Heiko
On 23 Oct 2016, at 9:38, Heiko W.Rupp wrote:
Update
[ tl;dr: good news ]
Lukas provided me with "connection properties" for hsqldb
that limit the memory usage and this seems stable. I have been
running h-services since Friday afternoon (~40h) with 33 HawkFly
feeds.
Two heap dumps taken yesterday afternoon and this morning
both show a stable heap size of 192M, so I think we are on the
safe side here (with hsqldb, see also below).
On top of just ingesting metrics, I have created poor mans Chaos
Monkey that randomly stops and restarts a container every 5 minutes
(parallel on 2 machines where my feeds live) to also stress the
initial
sync when a feeds is (re) connecting.
I also had a (very small) number of alert triggers defined, that
were firing when heap on a hawkfly is > 60k, which happened quite
often.
This was running during the last 36h, so is included in above
heap metrics.
The MBeans for hawkular metrics show an insertion rate of around
33 metrics/s , so a HawkFly corresponds to 1metric/s.
About hsqldb: I am going to shut this down now and test with a
h2-based instance, as h2 is already in WildFly and EAP and
should be used instead of hsqldb.
Some time next week I will also try to instrument HawkFly in a away
that it automatically defines some alert triggers on startup.
_______________________________________________
hawkular-dev mailing list
hawkular-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hawkular-dev
--
Reg. Adresse: Red Hat GmbH, Technopark II, Haus C,
Werner-von-Siemens-Ring 14, D-85630 Grasbrunn
Handelsregister: Amtsgericht München HRB 153243
Geschäftsführer: Charles Cachera, Michael Cunningham, Michael O'Neill,
Eric Shander
3447
days inactive
3460
days old
7 comments
2 participants
participants (2)
-
 Heiko W.Rupp
Heiko W.Rupp -
 Michael Burman
Michael Burman