
7:36 a.m.
Folks,
I’ve recently been looking at WildFly container deployments on OpenShift V3. The following
setup is documented here
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/fabri...
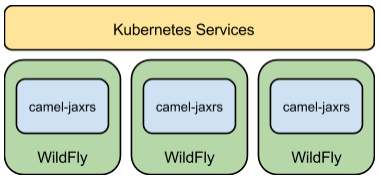
The example architecture consists of a set of three high available (HA) servers running
REST endpoints.
For server replication and failover we use Kubernetes. Each server runs in a dedicated Pod
that we access via Services.
This approach comes with a number of benefits, which are sufficiently explained in various
OpenShift
<https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernet...;,
Kubernetes <https://github.com/GoogleCloudPlatform/kubernetes/blob/master/README.md>
and Docker <https://docs.docker.com/> materials, but also with a number of
challenges. Lets look at those in more detail …
In the example above Kubernetes replicates a number of standalone containers and isolates
them in a Pod each with limited access from the outside world.
* The management interfaces are not accessible
* The management consoles are not visible
With WildFly-Camel we have a Hawt.io
<http://wildflyext.gitbooks.io/wildfly-camel/content/features/hawtio.html> console
that allows us to manage Camel Routes configured or deployed to the WildFly runtime.
The WildFly console manages aspects of the appserver.
In a more general sense, I was wondering how the WildFly domain model maps to the
Kubernetes runtime environment and how these server instances are managed and information
about them relayed back to the sysadmin
a) Should these individual wildfly instances somehow be connected to each other (i.e.
notion of domain)?
b) How would an HA singleton service work?
c) What level of management should be exposed to the outside?
d) Should it be possible to modify runtime behaviour of these servers (i.e. write access
to config)?
e) Should deployment be supported at all?
f) How can a server be detected that has gone bad?
g) Should logs be aggregated?
h) Should there be a common management view (i.e. console) for these servers?
i) etc …
Are these concerns already being addressed for WildFly?
Is there perhaps even an already existing design that I could look at?
Can such an effort be connected to the work that is going on in Fabric8?
cheers
—thomas
PS: it would be area that we @ wildfly-camel were interested to work on
{kind=link}

1 p.m.
On 12/5/14, 7:36 AM, Thomas Diesler wrote:
Folks,
I’ve recently been looking at WildFly container deployments on OpenShift
V3. The following setup is documented here
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/fabri...
The example architecture consists of a set of three high available
(HA) servers running REST endpoints.
For server replication and failover we use Kubernetes. Each server
runs in a dedicated Pod that we access via Services.
This approach comes with a number of benefits, which are sufficiently
explained in various OpenShift
<https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernet...;,
Kubernetes
<https://github.com/GoogleCloudPlatform/kubernetes/blob/master/README.md> and
Docker <https://docs.docker.com/> materials, but also with a number of
challenges. Lets look at those in more detail …
In the example above Kubernetes replicates a number of standalone
containers and isolates them in a Pod each with limited access from the
outside world.
* The management interfaces are not accessible
* The management consoles are not visible
With WildFly-Camel we have a Hawt.io
<http://wildflyext.gitbooks.io/wildfly-camel/content/features/hawtio.html> console
that allows us to manage Camel Routes configured or deployed to the
WildFly runtime.
The WildFly console manages aspects of the appserver.
In a more general sense, I was wondering how the WildFly domain model
maps to the Kubernetes runtime environment and how these server
instances are managed and information about them relayed back to the
sysadmin
Your questions below mostly relate (correctly) to what *should* be done
but I'll preface by discussing what *could* be done. Please forgive noob
mistakes as I'm an admitted Kubernetes noob.
AIUI a Kubernetes services exposes a single endpoint to outside callers,
but the containers in the pods can open an arbitrary number of client
connections to other services.
This should work fine with WildFly domain management, as there can be a
Service for the Domain Controller, which is the management interaction
point for the sysadmin. And then the WildFly instance in the container
for any other Service can connect and register with that Domain
Controller service. The address/port those other containers use can be
the same one that sysadmins use.
a) Should these individual wildfly instances somehow be connected to
each other (i.e. notion of domain)?
Depends on the use case, but I expect certainly some users will
centralized management, even if it's just for monitoring.
b) How would an HA singleton service work?
WildFly *domain management* itself does not have an HA singleton notion, but
i) Kubernetes replication controllers themselves provide a form of this,
but I assume with a period of downtime while a new pod is spun up.
ii) WildFly clustering has an HA singleton service concept that can be
used. There are different mechanisms JGroups supports for group
communication, but one involves each peer in the group connecting to a
central coordination process. So presumably that coordination process
could be deployed as a Kubernetes Service.
c) What level of management should be exposed to the outside?
As much as possible this should be a user choice. Architecturally, I
believe we can expose everything. I'm not real keen on trying to disable
things in Kubernetes-specific ways. But I'm quite open to features to
disable things that work in any deployment environment.
d) Should it be possible to modify runtime behaviour of these
servers
(i.e. write access to config)?
See c). We don't have a true read-only mode, athough I think it would be
fairly straightforward to add such a thing if it were a requirement.
e) Should deployment be supported at all?
See c). Making removing deployment capability configurable is also
doable, although it's likely more work than a simple read-only mode.
f) How can a server be detected that has gone bad?
I'll need to get a better understanding of Kubernetes to say anything
useful about this.
g) Should logs be aggregated?
This sounds like something that belongs at a higher layer, or as a
general purpose WildFly feature unrelated to Kubernetes.
h) Should there be a common management view (i.e. console) for these
servers?
I don't see why not. I think some users will want that, others won't,
and others will want a console that spans things beyond WildFly servers.
i) etc …
Are these concerns already being addressed for WildFly?
Somewhat. As you can see from the above, a fair bit of stuff could just
work. I know Heiko Braun has been thinking a bit about Kubernetes use
cases too, or at least wanting to do so. ;)
Is there perhaps even an already existing design that I could look
at?
Kubernetes specific stuff? No.
Can such an effort be connected to the work that is going on in
Fabric8?
The primary Fabric8-related thing we (aka Alexey Loubyansky) are doing
currently is working to support non-xml based persistence of our config
files and a mechanism to support server detection of changes to the
filesystem, triggering updates to the runtime. Goal being to integrate
with the git-based mechanisms Fabric8 uses for configuration.
https://developer.jboss.org/docs/DOC-52773
https://issues.jboss.org/browse/WFCORE-294
https://issues.jboss.org/browse/WFCORE-433
cheers
—thomas
PS: it would be area that we @ wildfly-camel were interested to work on
Great! :)
--
Brian Stansberry
Senior Principal Software Engineer
JBoss by Red Hat
3:08 a.m.
Thank Brian, I’d like to do a little more research with wildfly domain mode
<https://github.com/wildfly-extras/wildfly-camel/issues/93> in openshift before
responding. Won’t be long ...
On 5 Dec 2014, at 20:00, Brian Stansberry
<brian.stansberry(a)redhat.com> wrote:
On 12/5/14, 7:36 AM, Thomas Diesler wrote:
> Folks,
>
> I’ve recently been looking at WildFly container deployments on OpenShift
> V3. The following setup is documented here
>
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/fabri...
>
>
> The example architecture consists of a set of three high available
> (HA) servers running REST endpoints.
> For server replication and failover we use Kubernetes. Each server
> runs in a dedicated Pod that we access via Services.
>
> This approach comes with a number of benefits, which are sufficiently
> explained in various OpenShift
>
<https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernet...;,
> Kubernetes
> <https://github.com/GoogleCloudPlatform/kubernetes/blob/master/README.md> and
> Docker <https://docs.docker.com/> materials, but also with a number of
> challenges. Lets look at those in more detail …
>
> In the example above Kubernetes replicates a number of standalone
> containers and isolates them in a Pod each with limited access from the
> outside world.
>
> * The management interfaces are not accessible
> * The management consoles are not visible
>
> With WildFly-Camel we have a Hawt.io
> <http://wildflyext.gitbooks.io/wildfly-camel/content/features/hawtio.html>
console
> that allows us to manage Camel Routes configured or deployed to the
> WildFly runtime.
> The WildFly console manages aspects of the appserver.
>
> In a more general sense, I was wondering how the WildFly domain model
> maps to the Kubernetes runtime environment and how these server
> instances are managed and information about them relayed back to the
> sysadmin
>
Your questions below mostly relate (correctly) to what *should* be done
but I'll preface by discussing what *could* be done. Please forgive noob
mistakes as I'm an admitted Kubernetes noob.
AIUI a Kubernetes services exposes a single endpoint to outside callers,
but the containers in the pods can open an arbitrary number of client
connections to other services.
This should work fine with WildFly domain management, as there can be a
Service for the Domain Controller, which is the management interaction
point for the sysadmin. And then the WildFly instance in the container
for any other Service can connect and register with that Domain
Controller service. The address/port those other containers use can be
the same one that sysadmins use.
> a) Should these individual wildfly instances somehow be connected to
> each other (i.e. notion of domain)?
Depends on the use case, but I expect certainly some users will
centralized management, even if it's just for monitoring.
> b) How would an HA singleton service work?
WildFly *domain management* itself does not have an HA singleton notion, but
i) Kubernetes replication controllers themselves provide a form of this,
but I assume with a period of downtime while a new pod is spun up.
ii) WildFly clustering has an HA singleton service concept that can be
used. There are different mechanisms JGroups supports for group
communication, but one involves each peer in the group connecting to a
central coordination process. So presumably that coordination process
could be deployed as a Kubernetes Service.
> c) What level of management should be exposed to the outside?
As much as possible this should be a user choice. Architecturally, I
believe we can expose everything. I'm not real keen on trying to disable
things in Kubernetes-specific ways. But I'm quite open to features to
disable things that work in any deployment environment.
> d) Should it be possible to modify runtime behaviour of these servers
> (i.e. write access to config)?
See c). We don't have a true read-only mode, athough I think it would be
fairly straightforward to add such a thing if it were a requirement.
> e) Should deployment be supported at all?
See c). Making removing deployment capability configurable is also
doable, although it's likely more work than a simple read-only mode.
> f) How can a server be detected that has gone bad?
I'll need to get a better understanding of Kubernetes to say anything
useful about this.
> g) Should logs be aggregated?
This sounds like something that belongs at a higher layer, or as a
general purpose WildFly feature unrelated to Kubernetes.
> h) Should there be a common management view (i.e. console) for these
> servers?
I don't see why not. I think some users will want that, others won't,
and others will want a console that spans things beyond WildFly servers.
> i) etc …
>
> Are these concerns already being addressed for WildFly?
>
Somewhat. As you can see from the above, a fair bit of stuff could just
work. I know Heiko Braun has been thinking a bit about Kubernetes use
cases too, or at least wanting to do so. ;)
> Is there perhaps even an already existing design that I could look at?
>
Kubernetes specific stuff? No.
> Can such an effort be connected to the work that is going on in Fabric8?
>
The primary Fabric8-related thing we (aka Alexey Loubyansky) are doing
currently is working to support non-xml based persistence of our config
files and a mechanism to support server detection of changes to the
filesystem, triggering updates to the runtime. Goal being to integrate
with the git-based mechanisms Fabric8 uses for configuration.
https://developer.jboss.org/docs/DOC-52773
https://issues.jboss.org/browse/WFCORE-294
https://issues.jboss.org/browse/WFCORE-433
> cheers
> —thomas
>
> PS: it would be area that we @ wildfly-camel were interested to work on
Great! :)
--
Brian Stansberry
Senior Principal Software Engineer
JBoss by Red Hat
_______________________________________________
wildfly-dev mailing list
wildfly-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/wildfly-dev
3:28 a.m.
New subject: WildFly domain on OpenShift Origin
Folks,
following up on this topic, I worked a little more on WildFly-Camel in
Kubernetes/OpenShift.
These doc pages are targeted for the upcoming 2.1.0 release (01-Feb-2015)
WildFly-Camel on Docker
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/docke...
WildFly-Camel on OpenShift
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/opens...
The setup looks like this
We can now manage these individual wildfly nodes. The domain controller (DC) is replicated
once, the host definition is replicated three times.
Theoretically, this means that there is no single point of failure with the domain
controller any more - kube would respawn the DC on failure
Here some ideas for improvement …
In a kube env we should be able to swap out containers based on some criteria. It should
be possible to define these criteria, emit events based on them create/remove/replace
containers automatically.
Additionally a human should be able to make qualified decisions through a console and
create/remove/replace containers easily.
Much of the needed information is in jmx. Heiko told me that there is a project that can
push events to influx db - something to look at.
If information display contained in jmx in a console has value (e.g in hawtio) that
information must be aggregated and visible for each node.
Currently, we have a round robin service on 8080 which would show a different hawtio
instance on every request - this is nonsense.
I can see a number of high level items:
#1 a thing that aggregates jmx content - possibly multiple MBeanServers in the DC VM that
delegate to respective MBeanServers on other hosts, so that a management client can pickup
the info from one service
#2 look at the existing inluxdb thing and research into how to automate the replacement of
containers
#3 from the usability perspective, there may need to be an openshift profile in the
console(s) because some operations may not make sense in that env
cheers
—thomas
PS: looking forward to an exiting ride in 2015
On 5 Dec 2014, at 14:36, Thomas Diesler <tdiesler(a)redhat.com>
wrote:
Folks,
I’ve recently been looking at WildFly container deployments on OpenShift V3. The
following setup is documented here
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/fabri...
<example-rest-design.png>
The example architecture consists of a set of three high available (HA) servers running
REST endpoints.
For server replication and failover we use Kubernetes. Each server runs in a dedicated
Pod that we access via Services.
This approach comes with a number of benefits, which are sufficiently explained in
various OpenShift
<https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernet...;,
Kubernetes <https://github.com/GoogleCloudPlatform/kubernetes/blob/master/README.md>
and Docker <https://docs.docker.com/> materials, but also with a number of
challenges. Lets look at those in more detail …
In the example above Kubernetes replicates a number of standalone containers and isolates
them in a Pod each with limited access from the outside world.
* The management interfaces are not accessible
* The management consoles are not visible
With WildFly-Camel we have a Hawt.io
<http://wildflyext.gitbooks.io/wildfly-camel/content/features/hawtio.html> console
that allows us to manage Camel Routes configured or deployed to the WildFly runtime.
The WildFly console manages aspects of the appserver.
In a more general sense, I was wondering how the WildFly domain model maps to the
Kubernetes runtime environment and how these server instances are managed and information
about them relayed back to the sysadmin
a) Should these individual wildfly instances somehow be connected to each other (i.e.
notion of domain)?
b) How would an HA singleton service work?
c) What level of management should be exposed to the outside?
d) Should it be possible to modify runtime behaviour of these servers (i.e. write access
to config)?
e) Should deployment be supported at all?
f) How can a server be detected that has gone bad?
g) Should logs be aggregated?
h) Should there be a common management view (i.e. console) for these servers?
i) etc …
Are these concerns already being addressed for WildFly?
Is there perhaps even an already existing design that I could look at?
Can such an effort be connected to the work that is going on in Fabric8?
cheers
—thomas
PS: it would be area that we @ wildfly-camel were interested to work on
_______________________________________________
wildfly-dev mailing list
wildfly-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/wildfly-dev
{kind=link}
8:42 a.m.
New subject: WildFly domain on OpenShift Origin
On 12/17/14, 3:28 AM, Thomas Diesler wrote:
Folks,
following up on this topic, I worked a little more on WildFly-Camel in
Kubernetes/OpenShift.
These doc pages are targeted for the upcoming 2.1.0 release (01-Feb-2015)
* WildFly-Camel on Docker
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/docke...
* WildFly-Camel on OpenShift
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/opens...
Great. :)
The setup looks like this
We can now manage these individual wildfly nodes. The domain controller
(DC) is replicated once, the host definition is replicated three times.
Theoretically, this means that there is no single point of failure with
the domain controller any more - kube would respawn the DC on failure
I'm heading on PTO tomorrow so likely won't be able to follow up on this
question for a while, but one concern I had with the Kubernetes respawn
approach was retaining any changes that had been made to the domain
configuration. Unless the domain.xml comes from / is written to some
shared storage available to the respawned DC, any changes made will be lost.
Of course, if the DC is only being used for reads, this isn't an issue.
Here some ideas for improvement …
In a kube env we should be able to swap out containers based on some
criteria. It should be possible to define these criteria, emit events
based on them create/remove/replace containers automatically.
Additionally a human should be able to make qualified decisions through
a console and create/remove/replace containers easily.
Much of the needed information is in jmx. Heiko told me that there is a
project that can push events to influx db - something to look at.
If information display contained in jmx in a console has value (e.g in
hawtio) that information must be aggregated and visible for each node.
Currently, we have a round robin service on 8080 which would show a
different hawtio instance on every request - this is nonsense.
I can see a number of high level items:
#1 a thing that aggregates jmx content - possibly multiple MBeanServers
in the DC VM that delegate to respective MBeanServers on other hosts, so
that a management client can pickup the info from one service
#2 look at the existing inluxdb thing and research into how to automate
the replacement of containers
#3 from the usability perspective, there may need to be an openshift
profile in the console(s) because some operations may not make sense in
that env
cheers
—thomas
PS: looking forward to an exiting ride in 2015
> On 5 Dec 2014, at 14:36, Thomas Diesler <tdiesler(a)redhat.com
> <mailto:tdiesler@redhat.com>> wrote:
>
> Folks,
>
> I’ve recently been looking at WildFly container deployments on
> OpenShift V3. The following setup is documented here
>
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/fabri...
>
> <example-rest-design.png>
>
> The example architecture consists of a set of three high available
> (HA) servers running REST endpoints.
> For server replication and failover we use Kubernetes. Each server
> runs in a dedicated Pod that we access via Services.
>
> This approach comes with a number of benefits, which are sufficiently
> explained in various OpenShift
>
<https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernet...;,
> Kubernetes
> <https://github.com/GoogleCloudPlatform/kubernetes/blob/master/README.md> and
> Docker <https://docs.docker.com/> materials, but also with a number of
> challenges. Lets look at those in more detail …
>
> In the example above Kubernetes replicates a number of standalone
> containers and isolates them in a Pod each with limited access from
> the outside world.
>
> * The management interfaces are not accessible
> * The management consoles are not visible
>
> With WildFly-Camel we have a Hawt.io
> <http://wildflyext.gitbooks.io/wildfly-camel/content/features/hawtio.html>
console
> that allows us to manage Camel Routes configured or deployed to the
> WildFly runtime.
> The WildFly console manages aspects of the appserver.
>
> In a more general sense, I was wondering how the WildFly domain model
> maps to the Kubernetes runtime environment and how these server
> instances are managed and information about them relayed back to the
> sysadmin
>
> a) Should these individual wildfly instances somehow be connected to
> each other (i.e. notion of domain)?
> b) How would an HA singleton service work?
> c) What level of management should be exposed to the outside?
> d) Should it be possible to modify runtime behaviour of these servers
> (i.e. write access to config)?
> e) Should deployment be supported at all?
> f) How can a server be detected that has gone bad?
> g) Should logs be aggregated?
> h) Should there be a common management view (i.e. console) for these
> servers?
> i) etc …
>
> Are these concerns already being addressed for WildFly?
>
> Is there perhaps even an already existing design that I could look at?
>
> Can such an effort be connected to the work that is going on in Fabric8?
>
> cheers
> —thomas
>
> PS: it would be area that we @ wildfly-camel were interested to work on
> _______________________________________________
> wildfly-dev mailing list
> wildfly-dev(a)lists.jboss.org <mailto:wildfly-dev@lists.jboss.org>
> https://lists.jboss.org/mailman/listinfo/wildfly-dev
--
Brian Stansberry
Senior Principal Software Engineer
JBoss by Red Hat
10:13 a.m.
New subject: WildFly domain on OpenShift Origin
On 17 Dec 2014, at 15:42, Brian Stansberry
<brian.stansberry(a)redhat.com> wrote:
On 12/17/14, 3:28 AM, Thomas Diesler wrote:
> Folks,
>
> following up on this topic, I worked a little more on WildFly-Camel in
> Kubernetes/OpenShift.
>
> These doc pages are targeted for the upcoming 2.1.0 release (01-Feb-2015)
>
> * WildFly-Camel on Docker
>
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/docke...
> * WildFly-Camel on OpenShift
>
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/opens...
>
Great. :)
>
> The setup looks like this
>
>
> We can now manage these individual wildfly nodes. The domain controller
> (DC) is replicated once, the host definition is replicated three times.
> Theoretically, this means that there is no single point of failure with
> the domain controller any more - kube would respawn the DC on failure
>
I'm heading on PTO tomorrow so likely won't be able to follow up on this
question for a while, but one concern I had with the Kubernetes respawn
approach was retaining any changes that had been made to the domain
configuration. Unless the domain.xml comes from / is written to some
shared storage available to the respawned DC, any changes made will be lost.
Of course, if the DC is only being used for reads, this isn't an issue.
Yes, the management interface would need to detect whether a volume is used and perhaps
issue a warning accordingly
> Here some ideas for improvement …
>
> In a kube env we should be able to swap out containers based on some
> criteria. It should be possible to define these criteria, emit events
> based on them create/remove/replace containers automatically.
> Additionally a human should be able to make qualified decisions through
> a console and create/remove/replace containers easily.
> Much of the needed information is in jmx. Heiko told me that there is a
> project that can push events to influx db - something to look at.
>
> If information display contained in jmx in a console has value (e.g in
> hawtio) that information must be aggregated and visible for each node.
> Currently, we have a round robin service on 8080 which would show a
> different hawtio instance on every request - this is nonsense.
>
> I can see a number of high level items:
>
> #1 a thing that aggregates jmx content - possibly multiple MBeanServers
> in the DC VM that delegate to respective MBeanServers on other hosts, so
> that a management client can pickup the info from one service
> #2 look at the existing inluxdb thing and research into how to automate
> the replacement of containers
> #3 from the usability perspective, there may need to be an openshift
> profile in the console(s) because some operations may not make sense in
> that env
>
> cheers
> —thomas
>
> PS: looking forward to an exiting ride in 2015
>
>
>> On 5 Dec 2014, at 14:36, Thomas Diesler <tdiesler(a)redhat.com
>> <mailto:tdiesler@redhat.com>> wrote:
>>
>> Folks,
>>
>> I’ve recently been looking at WildFly container deployments on
>> OpenShift V3. The following setup is documented here
>>
<https://github.com/wildfly-extras/wildfly-camel-book/blob/2.1/cloud/fabri...
>>
>> <example-rest-design.png>
>>
>> The example architecture consists of a set of three high available
>> (HA) servers running REST endpoints.
>> For server replication and failover we use Kubernetes. Each server
>> runs in a dedicated Pod that we access via Services.
>>
>> This approach comes with a number of benefits, which are sufficiently
>> explained in various OpenShift
>>
<https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernet...;,
>> Kubernetes
>> <https://github.com/GoogleCloudPlatform/kubernetes/blob/master/README.md>
and
>> Docker <https://docs.docker.com/> materials, but also with a number of
>> challenges. Lets look at those in more detail …
>>
>> In the example above Kubernetes replicates a number of standalone
>> containers and isolates them in a Pod each with limited access from
>> the outside world.
>>
>> * The management interfaces are not accessible
>> * The management consoles are not visible
>>
>> With WildFly-Camel we have a Hawt.io
>> <http://wildflyext.gitbooks.io/wildfly-camel/content/features/hawtio.html>
console
>> that allows us to manage Camel Routes configured or deployed to the
>> WildFly runtime.
>> The WildFly console manages aspects of the appserver.
>>
>> In a more general sense, I was wondering how the WildFly domain model
>> maps to the Kubernetes runtime environment and how these server
>> instances are managed and information about them relayed back to the
>> sysadmin
>>
>> a) Should these individual wildfly instances somehow be connected to
>> each other (i.e. notion of domain)?
>> b) How would an HA singleton service work?
>> c) What level of management should be exposed to the outside?
>> d) Should it be possible to modify runtime behaviour of these servers
>> (i.e. write access to config)?
>> e) Should deployment be supported at all?
>> f) How can a server be detected that has gone bad?
>> g) Should logs be aggregated?
>> h) Should there be a common management view (i.e. console) for these
>> servers?
>> i) etc …
>>
>> Are these concerns already being addressed for WildFly?
>>
>> Is there perhaps even an already existing design that I could look at?
>>
>> Can such an effort be connected to the work that is going on in Fabric8?
>>
>> cheers
>> —thomas
>>
>> PS: it would be area that we @ wildfly-camel were interested to work on
>> _______________________________________________
>> wildfly-dev mailing list
>> wildfly-dev(a)lists.jboss.org <mailto:wildfly-dev@lists.jboss.org>
>> https://lists.jboss.org/mailman/listinfo/wildfly-dev
>
--
Brian Stansberry
Senior Principal Software Engineer
JBoss by Red Hat
_______________________________________________
wildfly-dev mailing list
wildfly-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/wildfly-dev
4242
days inactive
4254
days old
5 comments
2 participants
participants (2)
-
 Brian Stansberry
Brian Stansberry -
 Thomas Diesler
Thomas Diesler