
11:10 a.m.
Hi David,
Please find attach graphs belonging to two runs that compare:
infinispan-4.0.0(repl-sync) - home grown marshalling layer
infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with revision
Not sure what's the conclusion here tbh. The results of 1.1.2 almost
look opposite in each test.
I've also attached some information from previously run profiling
sessions with a couple of local machines we have in Neuchatel. I
profiled the faster of the two machines.
Actually, looking at this profiled data, these tests are for synchronous
replicated caches but I see no traces of actually reading the stream,
only writing to it, hmmmm.
I'm adding Externalizers to class table and implementing
marshaller/unmarshaller pooling as my next tasks.
Regards,
David M. Lloyd wrote:
OK, I tried out a few things. You might want to try introducing
these
one at a time (i.e. update up to rev 173, then 174, then 175 and see how
each one does). In particular, I think 175 has just as much chance of
slowing things down as speeding them up - either you're getting tons of
collisions in the hash table or the profiler is skewing the results
there (maybe try filtering out org.jboss.marshalling.util.IdentityIntMap
and java.lang.System to see if that gives a different picture).
I feel pretty good about 173 and 174 though I think the profiler will
skew 173 unless you have that UTFUtils filter installed. If 175 slows
things down (outside of the profiler), let me know and I'll revert it.
None of my tests showed much difference but I don't have any good
benchmarks that really exercise that code right now.
There's a couple things left to try yet, like looking at replacing
ConcurrentReferenceHashMap (assuming that isn't the profiler again).
------------------------------------------------------------------------
r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08 May
2009) | 1 line
Try a trick to decrease the liklihood of collisions
------------------------------------------------------------------------
r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08 May
2009) | 1 line
Replacement caching is not economical; the cost is one extra hash table
get for non-replaced objects, two hash table gets (total) for replaced
objects. Removing the cache gets rid of the cost for non-replaced
objects, while replaced objects now have to be replaced again before the
single hash table hit.
------------------------------------------------------------------------
r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07 May
2009) | 1 line
JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
------------------------------------------------------------------------
- DML
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
{kind=link}
{kind=link}
{kind=link}
{kind=link}
12:09 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Profiler data with JBMAR r174
Galder Zamarreno wrote:
Hi David,
Please find attach graphs belonging to two runs that compare:
infinispan-4.0.0(repl-sync) - home grown marshalling layer
infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with revision
Not sure what's the conclusion here tbh. The results of 1.1.2 almost
look opposite in each test.
I've also attached some information from previously run profiling
sessions with a couple of local machines we have in Neuchatel. I
profiled the faster of the two machines.
Actually, looking at this profiled data, these tests are for synchronous
replicated caches but I see no traces of actually reading the stream,
only writing to it, hmmmm.
I'm adding Externalizers to class table and implementing
marshaller/unmarshaller pooling as my next tasks.
Regards,
David M. Lloyd wrote:
> OK, I tried out a few things. You might want to try introducing these
> one at a time (i.e. update up to rev 173, then 174, then 175 and see
> how each one does). In particular, I think 175 has just as much
> chance of slowing things down as speeding them up - either you're
> getting tons of collisions in the hash table or the profiler is
> skewing the results there (maybe try filtering out
> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to see
> if that gives a different picture).
>
> I feel pretty good about 173 and 174 though I think the profiler will
> skew 173 unless you have that UTFUtils filter installed. If 175 slows
> things down (outside of the profiler), let me know and I'll revert
> it. None of my tests showed much difference but I don't have any good
> benchmarks that really exercise that code right now.
>
> There's a couple things left to try yet, like looking at replacing
> ConcurrentReferenceHashMap (assuming that isn't the profiler again).
>
> ------------------------------------------------------------------------
> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08 May
> 2009) | 1 line
>
> Try a trick to decrease the liklihood of collisions
> ------------------------------------------------------------------------
> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08 May
> 2009) | 1 line
>
> Replacement caching is not economical; the cost is one extra hash
> table get for non-replaced objects, two hash table gets (total) for
> replaced objects. Removing the cache gets rid of the cost for
> non-replaced objects, while replaced objects now have to be replaced
> again before the single hash table hit.
> ------------------------------------------------------------------------
> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07 May
> 2009) | 1 line
>
> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
> ------------------------------------------------------------------------
>
> - DML
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
12:50 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
David,
A few questions about RiverMarshaller:
1. Why not make classCache and externalizers in RM live longer than the
start/finish period? For example, if you had a create/destroy lifecycles
that expanded for example Cache.start()/stop(), then classCache and
externalizers will be shared by all writes and I think this could
enhance performance. Wouldn't do this for instancesCache since it would
blow out.
2. Looking at the profiling data, I'm slightly concerned about
writeReplace() code are in the for(;;) loop in RM. I mean, writeReplace
only makes sense for Serializable classes but this section of code is
being executed a lot, much more than the number of Serializable classes
are in the tests.
I just a ran quick test and for a String, this section of the code is
executed but why do so when you know for sure that a String that is
final does not have and cannot have writeReplace()?
I think section should go right to the bottom to the obj instanceof
Serializable section or somewhere where is less in the critical path.
Regards,
Galder Zamarreno wrote:
Profiler data with JBMAR r174
Galder Zamarreno wrote:
> Hi David,
>
> Please find attach graphs belonging to two runs that compare:
>
> infinispan-4.0.0(repl-sync) - home grown marshalling layer
> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with revision
>
> Not sure what's the conclusion here tbh. The results of 1.1.2 almost
> look opposite in each test.
>
> I've also attached some information from previously run profiling
> sessions with a couple of local machines we have in Neuchatel. I
> profiled the faster of the two machines.
>
> Actually, looking at this profiled data, these tests are for
> synchronous replicated caches but I see no traces of actually reading
> the stream, only writing to it, hmmmm.
>
> I'm adding Externalizers to class table and implementing
> marshaller/unmarshaller pooling as my next tasks.
>
> Regards,
>
> David M. Lloyd wrote:
>> OK, I tried out a few things. You might want to try introducing
>> these one at a time (i.e. update up to rev 173, then 174, then 175
>> and see how each one does). In particular, I think 175 has just as
>> much chance of slowing things down as speeding them up - either
>> you're getting tons of collisions in the hash table or the profiler
>> is skewing the results there (maybe try filtering out
>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to see
>> if that gives a different picture).
>>
>> I feel pretty good about 173 and 174 though I think the profiler will
>> skew 173 unless you have that UTFUtils filter installed. If 175
>> slows things down (outside of the profiler), let me know and I'll
>> revert it. None of my tests showed much difference but I don't have
>> any good benchmarks that really exercise that code right now.
>>
>> There's a couple things left to try yet, like looking at replacing
>> ConcurrentReferenceHashMap (assuming that isn't the profiler again).
>>
>> ------------------------------------------------------------------------
>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08 May
>> 2009) | 1 line
>>
>> Try a trick to decrease the liklihood of collisions
>> ------------------------------------------------------------------------
>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08 May
>> 2009) | 1 line
>>
>> Replacement caching is not economical; the cost is one extra hash
>> table get for non-replaced objects, two hash table gets (total) for
>> replaced objects. Removing the cache gets rid of the cost for
>> non-replaced objects, while replaced objects now have to be replaced
>> again before the single hash table hit.
>> ------------------------------------------------------------------------
>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07 May
>> 2009) | 1 line
>>
>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>> ------------------------------------------------------------------------
>>
>> - DML
>
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat

2:47 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Already answered these in PM, but for the benefit of the list...
1. The caches aren't there for performance (though that is an obvious
side-effect); these are the backreference caches for written data. In
other words, we don't write the same instance twice in the same message;
instead there's a numerical reference to an object at an earlier stream
position. So in order to reuse this cache or avoid discarding it, you must
continue to write to the same stream to guarantee that the remote side will
read messages in the same order they were written by the corresponding
marshaller. Put simply, these caches *have* to be cleared on a per-message
basis, otherwise the backreferences won't match up and unmarshalling will fail.
2. The for(;;) loop actually only executes either one or two times (usually
just once). According to the serialization spec[1], the various checks
have to be done in a certain order, otherwise Serializable objects which
depend on certain features such as write replacement and custom write
methods might malfunction. That said, if we can prove that this is a
performance issue there are some things we can try, like optionally
disabling object substitution via a configuration object; also it's
possible that things can be rearranged without breaking the semantics.
For the example of String, we (you and I) might know that such a class can
never support substitution, but short of doing an "instanceof String"
there's no way that the marshaller can know that the instance is in fact a
String in time to avoid doing the check. And adding in a bunch of early
"instanceof" may well impose more of an overhead than just checking if the
method is there.
If you read the spec (chapter 2), actually any object type (including
non-serializable objects) can have a replacement. So disabling this has to
be an optional feature, if we even opt to do it (proving where perf. issues
are is pretty tricky even with profilers, as we're discovering).
[1]
http://java.sun.com/javase/6/docs/platform/serialization/spec/serialTOC.html
On 05/08/2009 12:50 PM, Galder Zamarreno wrote:
David,
A few questions about RiverMarshaller:
1. Why not make classCache and externalizers in RM live longer than the
start/finish period? For example, if you had a create/destroy lifecycles
that expanded for example Cache.start()/stop(), then classCache and
externalizers will be shared by all writes and I think this could
enhance performance. Wouldn't do this for instancesCache since it would
blow out.
2. Looking at the profiling data, I'm slightly concerned about
writeReplace() code are in the for(;;) loop in RM. I mean, writeReplace
only makes sense for Serializable classes but this section of code is
being executed a lot, much more than the number of Serializable classes
are in the tests.
I just a ran quick test and for a String, this section of the code is
executed but why do so when you know for sure that a String that is
final does not have and cannot have writeReplace()?
I think section should go right to the bottom to the obj instanceof
Serializable section or somewhere where is less in the critical path.
Regards,
Galder Zamarreno wrote:
> Profiler data with JBMAR r174
>
> Galder Zamarreno wrote:
>> Hi David,
>>
>> Please find attach graphs belonging to two runs that compare:
>>
>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with
>> revision
>>
>> Not sure what's the conclusion here tbh. The results of 1.1.2 almost
>> look opposite in each test.
>>
>> I've also attached some information from previously run profiling
>> sessions with a couple of local machines we have in Neuchatel. I
>> profiled the faster of the two machines.
>>
>> Actually, looking at this profiled data, these tests are for
>> synchronous replicated caches but I see no traces of actually reading
>> the stream, only writing to it, hmmmm.
>>
>> I'm adding Externalizers to class table and implementing
>> marshaller/unmarshaller pooling as my next tasks.
>>
>> Regards,
>>
>> David M. Lloyd wrote:
>>> OK, I tried out a few things. You might want to try introducing
>>> these one at a time (i.e. update up to rev 173, then 174, then 175
>>> and see how each one does). In particular, I think 175 has just as
>>> much chance of slowing things down as speeding them up - either
>>> you're getting tons of collisions in the hash table or the profiler
>>> is skewing the results there (maybe try filtering out
>>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to
>>> see if that gives a different picture).
>>>
>>> I feel pretty good about 173 and 174 though I think the profiler
>>> will skew 173 unless you have that UTFUtils filter installed. If
>>> 175 slows things down (outside of the profiler), let me know and
>>> I'll revert it. None of my tests showed much difference but I don't
>>> have any good benchmarks that really exercise that code right now.
>>>
>>> There's a couple things left to try yet, like looking at replacing
>>> ConcurrentReferenceHashMap (assuming that isn't the profiler again).
>>>
>>> ------------------------------------------------------------------------
>>>
>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08
>>> May 2009) | 1 line
>>>
>>> Try a trick to decrease the liklihood of collisions
>>> ------------------------------------------------------------------------
>>>
>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08
>>> May 2009) | 1 line
>>>
>>> Replacement caching is not economical; the cost is one extra hash
>>> table get for non-replaced objects, two hash table gets (total) for
>>> replaced objects. Removing the cache gets rid of the cost for
>>> non-replaced objects, while replaced objects now have to be replaced
>>> again before the single hash table hit.
>>> ------------------------------------------------------------------------
>>>
>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07
>>> May 2009) | 1 line
>>>
>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>> ------------------------------------------------------------------------
>>>
>>>
>>> - DML
>>
>
5:52 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Galder, would you mind switching to trunk and trying that version
(unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning and get a
source blob built asap!)?
- DML
On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
Profiler data with JBMAR r174
Galder Zamarreno wrote:
> Hi David,
>
> Please find attach graphs belonging to two runs that compare:
>
> infinispan-4.0.0(repl-sync) - home grown marshalling layer
> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with revision
>
> Not sure what's the conclusion here tbh. The results of 1.1.2 almost
> look opposite in each test.
>
> I've also attached some information from previously run profiling
> sessions with a couple of local machines we have in Neuchatel. I
> profiled the faster of the two machines.
>
> Actually, looking at this profiled data, these tests are for
> synchronous replicated caches but I see no traces of actually reading
> the stream, only writing to it, hmmmm.
>
> I'm adding Externalizers to class table and implementing
> marshaller/unmarshaller pooling as my next tasks.
>
> Regards,
>
> David M. Lloyd wrote:
>> OK, I tried out a few things. You might want to try introducing
>> these one at a time (i.e. update up to rev 173, then 174, then 175
>> and see how each one does). In particular, I think 175 has just as
>> much chance of slowing things down as speeding them up - either
>> you're getting tons of collisions in the hash table or the profiler
>> is skewing the results there (maybe try filtering out
>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to see
>> if that gives a different picture).
>>
>> I feel pretty good about 173 and 174 though I think the profiler will
>> skew 173 unless you have that UTFUtils filter installed. If 175
>> slows things down (outside of the profiler), let me know and I'll
>> revert it. None of my tests showed much difference but I don't have
>> any good benchmarks that really exercise that code right now.
>>
>> There's a couple things left to try yet, like looking at replacing
>> ConcurrentReferenceHashMap (assuming that isn't the profiler again).
>>
>> ------------------------------------------------------------------------
>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08 May
>> 2009) | 1 line
>>
>> Try a trick to decrease the liklihood of collisions
>> ------------------------------------------------------------------------
>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08 May
>> 2009) | 1 line
>>
>> Replacement caching is not economical; the cost is one extra hash
>> table get for non-replaced objects, two hash table gets (total) for
>> replaced objects. Removing the cache gets rid of the cost for
>> non-replaced objects, while replaced objects now have to be replaced
>> again before the single hash table hit.
>> ------------------------------------------------------------------------
>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07 May
>> 2009) | 1 line
>>
>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>> ------------------------------------------------------------------------
>>
>> - DML
>
11:06 a.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Hey,
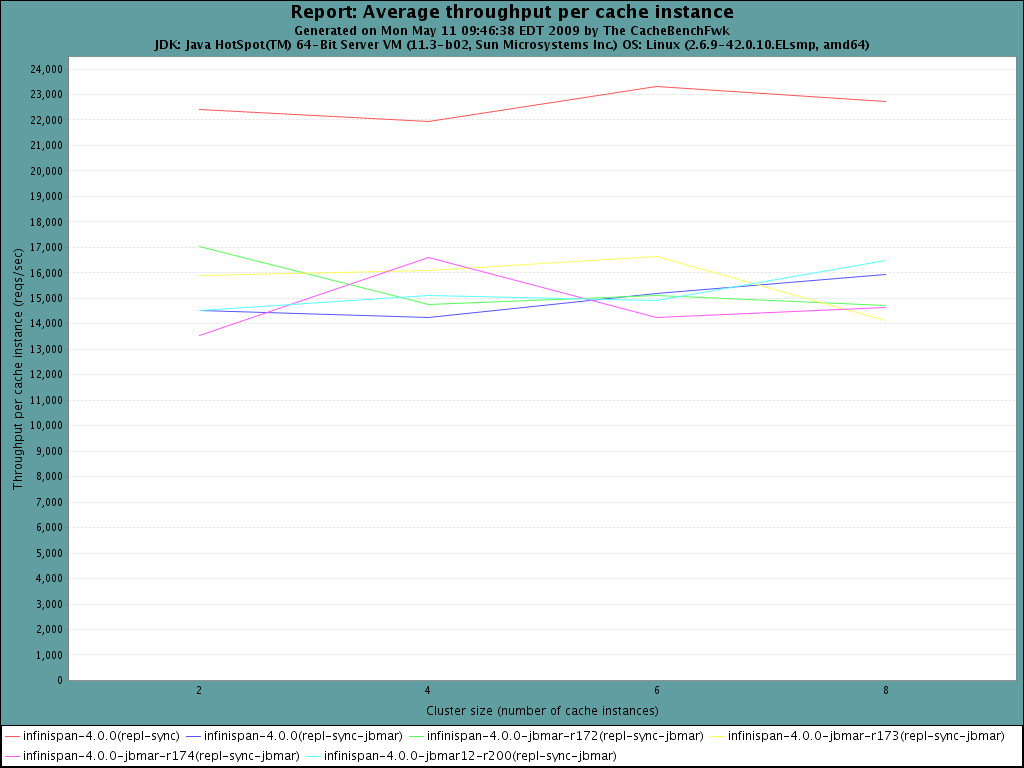
Run a couple of round of tests with JBMAR trunk (r200) and please find
attached the results. No real improvement I'm afraid. I'll look into the
profile data from r200 tomorrow.
I'm currently working on the pooling.
Regards,
David M. Lloyd wrote:
Galder, would you mind switching to trunk and trying that version
(unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning and get
a source blob built asap!)?
- DML
On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
> Profiler data with JBMAR r174
>
> Galder Zamarreno wrote:
>> Hi David,
>>
>> Please find attach graphs belonging to two runs that compare:
>>
>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with
>> revision
>>
>> Not sure what's the conclusion here tbh. The results of 1.1.2 almost
>> look opposite in each test.
>>
>> I've also attached some information from previously run profiling
>> sessions with a couple of local machines we have in Neuchatel. I
>> profiled the faster of the two machines.
>>
>> Actually, looking at this profiled data, these tests are for
>> synchronous replicated caches but I see no traces of actually reading
>> the stream, only writing to it, hmmmm.
>>
>> I'm adding Externalizers to class table and implementing
>> marshaller/unmarshaller pooling as my next tasks.
>>
>> Regards,
>>
>> David M. Lloyd wrote:
>>> OK, I tried out a few things. You might want to try introducing
>>> these one at a time (i.e. update up to rev 173, then 174, then 175
>>> and see how each one does). In particular, I think 175 has just as
>>> much chance of slowing things down as speeding them up - either
>>> you're getting tons of collisions in the hash table or the profiler
>>> is skewing the results there (maybe try filtering out
>>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to
>>> see if that gives a different picture).
>>>
>>> I feel pretty good about 173 and 174 though I think the profiler
>>> will skew 173 unless you have that UTFUtils filter installed. If
>>> 175 slows things down (outside of the profiler), let me know and
>>> I'll revert it. None of my tests showed much difference but I don't
>>> have any good benchmarks that really exercise that code right now.
>>>
>>> There's a couple things left to try yet, like looking at replacing
>>> ConcurrentReferenceHashMap (assuming that isn't the profiler again).
>>>
>>> ------------------------------------------------------------------------
>>>
>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08
>>> May 2009) | 1 line
>>>
>>> Try a trick to decrease the liklihood of collisions
>>> ------------------------------------------------------------------------
>>>
>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08
>>> May 2009) | 1 line
>>>
>>> Replacement caching is not economical; the cost is one extra hash
>>> table get for non-replaced objects, two hash table gets (total) for
>>> replaced objects. Removing the cache gets rid of the cost for
>>> non-replaced objects, while replaced objects now have to be replaced
>>> again before the single hash table hit.
>>> ------------------------------------------------------------------------
>>>
>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07
>>> May 2009) | 1 line
>>>
>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>> ------------------------------------------------------------------------
>>>
>>>
>>> - DML
>>
>
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
{kind=link}
{kind=link}
{kind=link}
{kind=link}
12:44 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
OK, then I think there must be something outside of JBMAR that is impacting
this. I've gone through and literally removed a number of the top hotspots
from the profiler reports which should have made a big difference if the
reports were correct.
Is there any way I can get ahold of your whole test case?
- DML
On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
Hey,
Run a couple of round of tests with JBMAR trunk (r200) and please find
attached the results. No real improvement I'm afraid. I'll look into the
profile data from r200 tomorrow.
I'm currently working on the pooling.
Regards,
David M. Lloyd wrote:
> Galder, would you mind switching to trunk and trying that version
> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning and
> get a source blob built asap!)?
>
> - DML
>
> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>> Profiler data with JBMAR r174
>>
>> Galder Zamarreno wrote:
>>> Hi David,
>>>
>>> Please find attach graphs belonging to two runs that compare:
>>>
>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with
>>> revision
>>>
>>> Not sure what's the conclusion here tbh. The results of 1.1.2 almost
>>> look opposite in each test.
>>>
>>> I've also attached some information from previously run profiling
>>> sessions with a couple of local machines we have in Neuchatel. I
>>> profiled the faster of the two machines.
>>>
>>> Actually, looking at this profiled data, these tests are for
>>> synchronous replicated caches but I see no traces of actually
>>> reading the stream, only writing to it, hmmmm.
>>>
>>> I'm adding Externalizers to class table and implementing
>>> marshaller/unmarshaller pooling as my next tasks.
>>>
>>> Regards,
>>>
>>> David M. Lloyd wrote:
>>>> OK, I tried out a few things. You might want to try introducing
>>>> these one at a time (i.e. update up to rev 173, then 174, then 175
>>>> and see how each one does). In particular, I think 175 has just as
>>>> much chance of slowing things down as speeding them up - either
>>>> you're getting tons of collisions in the hash table or the profiler
>>>> is skewing the results there (maybe try filtering out
>>>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to
>>>> see if that gives a different picture).
>>>>
>>>> I feel pretty good about 173 and 174 though I think the profiler
>>>> will skew 173 unless you have that UTFUtils filter installed. If
>>>> 175 slows things down (outside of the profiler), let me know and
>>>> I'll revert it. None of my tests showed much difference but I
>>>> don't have any good benchmarks that really exercise that code right
>>>> now.
>>>>
>>>> There's a couple things left to try yet, like looking at replacing
>>>> ConcurrentReferenceHashMap (assuming that isn't the profiler again).
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08
>>>> May 2009) | 1 line
>>>>
>>>> Try a trick to decrease the liklihood of collisions
>>>> ------------------------------------------------------------------------
>>>>
>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08
>>>> May 2009) | 1 line
>>>>
>>>> Replacement caching is not economical; the cost is one extra hash
>>>> table get for non-replaced objects, two hash table gets (total) for
>>>> replaced objects. Removing the cache gets rid of the cost for
>>>> non-replaced objects, while replaced objects now have to be
>>>> replaced again before the single hash table hit.
>>>> ------------------------------------------------------------------------
>>>>
>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07
>>>> May 2009) | 1 line
>>>>
>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>> - DML
>>>
>>
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------
1:34 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
David M. Lloyd wrote:
OK, then I think there must be something outside of JBMAR that is
impacting this. I've gone through and literally removed a number of the
top hotspots from the profiler reports which should have made a big
difference if the reports were correct.
Is there any way I can get ahold of your whole test case?
I'm a real ^%%$£%:
1.- In the cluster tests I had run, the nodes never joined and hence
never formed a cluster, so each node run independently!
Todo: improve benchmark framework so that if a cluster test is being run
with multiple nodes, the cluster view does indeed have that number of
nodes!!
2.- More importantly, all along I've been ignoring
cache-products/xyz/config.sh and hence when updating JBMAR, I was simply
copying the folder, without updating config.sh. Result? All the JBMAR
tests have been running with the very 1st JBMAR version tested.
Once again, I'm a real ^%%$£%^%*&%*£!!
I'm working to fix these two issues asap and will come back with
information asap.
- DML
On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
> Hey,
>
> Run a couple of round of tests with JBMAR trunk (r200) and please find
> attached the results. No real improvement I'm afraid. I'll look into
> the profile data from r200 tomorrow.
>
> I'm currently working on the pooling.
>
> Regards,
>
> David M. Lloyd wrote:
>> Galder, would you mind switching to trunk and trying that version
>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning and
>> get a source blob built asap!)?
>>
>> - DML
>>
>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>> Profiler data with JBMAR r174
>>>
>>> Galder Zamarreno wrote:
>>>> Hi David,
>>>>
>>>> Please find attach graphs belonging to two runs that compare:
>>>>
>>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with
>>>> revision
>>>>
>>>> Not sure what's the conclusion here tbh. The results of 1.1.2
>>>> almost look opposite in each test.
>>>>
>>>> I've also attached some information from previously run profiling
>>>> sessions with a couple of local machines we have in Neuchatel. I
>>>> profiled the faster of the two machines.
>>>>
>>>> Actually, looking at this profiled data, these tests are for
>>>> synchronous replicated caches but I see no traces of actually
>>>> reading the stream, only writing to it, hmmmm.
>>>>
>>>> I'm adding Externalizers to class table and implementing
>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>
>>>> Regards,
>>>>
>>>> David M. Lloyd wrote:
>>>>> OK, I tried out a few things. You might want to try introducing
>>>>> these one at a time (i.e. update up to rev 173, then 174, then 175
>>>>> and see how each one does). In particular, I think 175 has just
>>>>> as much chance of slowing things down as speeding them up - either
>>>>> you're getting tons of collisions in the hash table or the
>>>>> profiler is skewing the results there (maybe try filtering out
>>>>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to
>>>>> see if that gives a different picture).
>>>>>
>>>>> I feel pretty good about 173 and 174 though I think the profiler
>>>>> will skew 173 unless you have that UTFUtils filter installed. If
>>>>> 175 slows things down (outside of the profiler), let me know and
>>>>> I'll revert it. None of my tests showed much difference but I
>>>>> don't have any good benchmarks that really exercise that code
>>>>> right now.
>>>>>
>>>>> There's a couple things left to try yet, like looking at
replacing
>>>>> ConcurrentReferenceHashMap (assuming that isn't the profiler
again).
>>>>>
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08
>>>>> May 2009) | 1 line
>>>>>
>>>>> Try a trick to decrease the liklihood of collisions
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08
>>>>> May 2009) | 1 line
>>>>>
>>>>> Replacement caching is not economical; the cost is one extra hash
>>>>> table get for non-replaced objects, two hash table gets (total)
>>>>> for replaced objects. Removing the cache gets rid of the cost for
>>>>> non-replaced objects, while replaced objects now have to be
>>>>> replaced again before the single hash table hit.
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07
>>>>> May 2009) | 1 line
>>>>>
>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>>
>>>>> - DML
>>>>
>>>
>
>
> ------------------------------------------------------------------------
>
>
> ------------------------------------------------------------------------
>
>
> ------------------------------------------------------------------------
>
>
> ------------------------------------------------------------------------
>
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
1:38 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Galder Zamarreno wrote:
David M. Lloyd wrote:
> OK, then I think there must be something outside of JBMAR that is
> impacting this. I've gone through and literally removed a number of
> the top hotspots from the profiler reports which should have made a
> big difference if the reports were correct.
>
> Is there any way I can get ahold of your whole test case?
I'm a real ^%%$£%:
1.- In the cluster tests I had run, the nodes never joined and hence
never formed a cluster, so each node run independently!
Todo: improve benchmark framework so that if a cluster test is being run
with multiple nodes, the cluster view does indeed have that number of
nodes!!
2.- More importantly, all along I've been ignoring
cache-products/xyz/config.sh and hence when updating JBMAR, I was simply
copying the folder, without updating config.sh. Result? All the JBMAR
tests have been running with the very 1st JBMAR version tested.
Todo: cache-products/xyz/config.sh should not have the directory
hard-coded, it should retrieve the directory name of pwd or something
similar.
Once again, I'm a real ^%%$£%^%*&%*£!!
I'm working to fix these two issues asap and will come back with
information asap.
>
> - DML
>
> On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
>> Hey,
>>
>> Run a couple of round of tests with JBMAR trunk (r200) and please
>> find attached the results. No real improvement I'm afraid. I'll look
>> into the profile data from r200 tomorrow.
>>
>> I'm currently working on the pooling.
>>
>> Regards,
>>
>> David M. Lloyd wrote:
>>> Galder, would you mind switching to trunk and trying that version
>>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning and
>>> get a source blob built asap!)?
>>>
>>> - DML
>>>
>>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>>> Profiler data with JBMAR r174
>>>>
>>>> Galder Zamarreno wrote:
>>>>> Hi David,
>>>>>
>>>>> Please find attach graphs belonging to two runs that compare:
>>>>>
>>>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with
>>>>> revision
>>>>>
>>>>> Not sure what's the conclusion here tbh. The results of 1.1.2
>>>>> almost look opposite in each test.
>>>>>
>>>>> I've also attached some information from previously run profiling
>>>>> sessions with a couple of local machines we have in Neuchatel. I
>>>>> profiled the faster of the two machines.
>>>>>
>>>>> Actually, looking at this profiled data, these tests are for
>>>>> synchronous replicated caches but I see no traces of actually
>>>>> reading the stream, only writing to it, hmmmm.
>>>>>
>>>>> I'm adding Externalizers to class table and implementing
>>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>>
>>>>> Regards,
>>>>>
>>>>> David M. Lloyd wrote:
>>>>>> OK, I tried out a few things. You might want to try introducing
>>>>>> these one at a time (i.e. update up to rev 173, then 174, then
>>>>>> 175 and see how each one does). In particular, I think 175 has
>>>>>> just as much chance of slowing things down as speeding them up -
>>>>>> either you're getting tons of collisions in the hash table or
the
>>>>>> profiler is skewing the results there (maybe try filtering out
>>>>>> org.jboss.marshalling.util.IdentityIntMap and java.lang.System to
>>>>>> see if that gives a different picture).
>>>>>>
>>>>>> I feel pretty good about 173 and 174 though I think the profiler
>>>>>> will skew 173 unless you have that UTFUtils filter installed. If
>>>>>> 175 slows things down (outside of the profiler), let me know and
>>>>>> I'll revert it. None of my tests showed much difference but
I
>>>>>> don't have any good benchmarks that really exercise that code
>>>>>> right now.
>>>>>>
>>>>>> There's a couple things left to try yet, like looking at
>>>>>> replacing ConcurrentReferenceHashMap (assuming that isn't the
>>>>>> profiler again).
>>>>>>
>>>>>>
------------------------------------------------------------------------
>>>>>>
>>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500 (Fri, 08
>>>>>> May 2009) | 1 line
>>>>>>
>>>>>> Try a trick to decrease the liklihood of collisions
>>>>>>
------------------------------------------------------------------------
>>>>>>
>>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500 (Fri, 08
>>>>>> May 2009) | 1 line
>>>>>>
>>>>>> Replacement caching is not economical; the cost is one extra hash
>>>>>> table get for non-replaced objects, two hash table gets (total)
>>>>>> for replaced objects. Removing the cache gets rid of the cost
>>>>>> for non-replaced objects, while replaced objects now have to be
>>>>>> replaced again before the single hash table hit.
>>>>>>
------------------------------------------------------------------------
>>>>>>
>>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500 (Thu, 07
>>>>>> May 2009) | 1 line
>>>>>>
>>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>>
------------------------------------------------------------------------
>>>>>>
>>>>>>
>>>>>> - DML
>>>>>
>>>>
>>
>>
>> ------------------------------------------------------------------------
>>
>>
>> ------------------------------------------------------------------------
>>
>>
>> ------------------------------------------------------------------------
>>
>>
>> ------------------------------------------------------------------------
>>
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
1:42 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
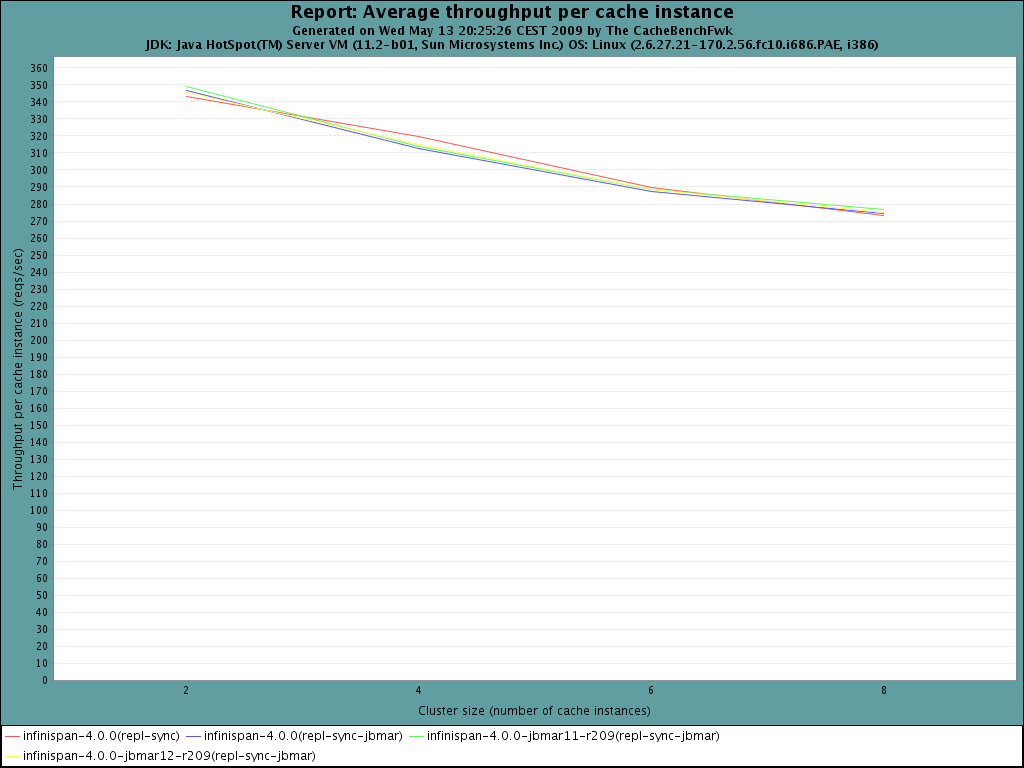
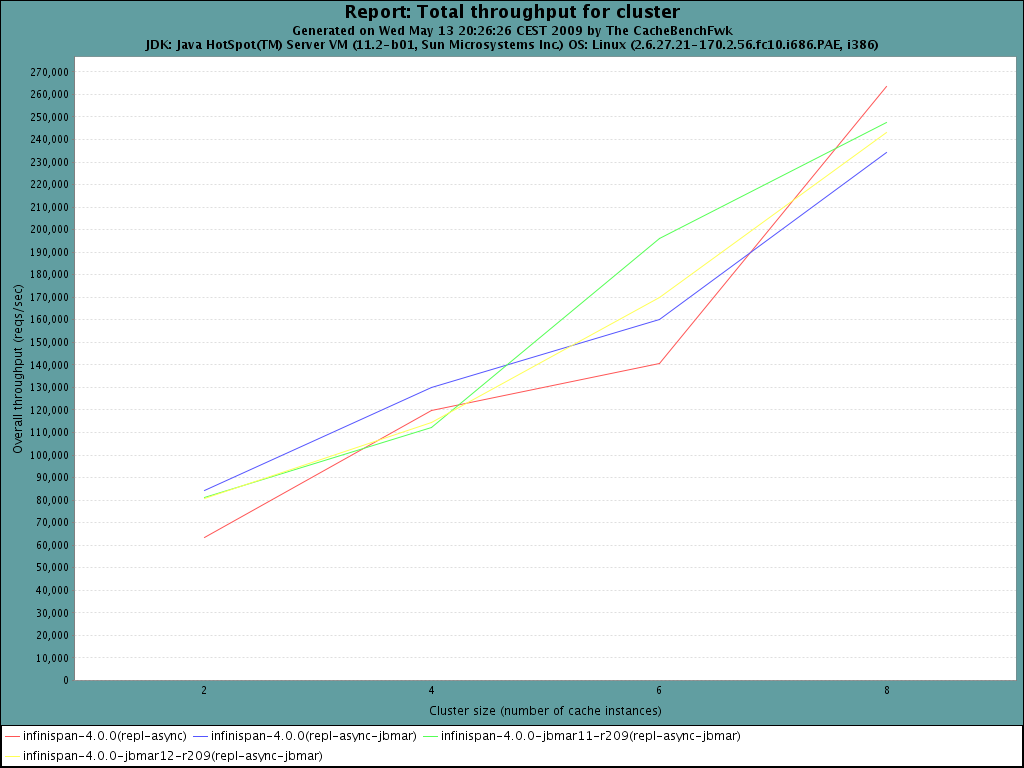
I've managed to get tests run making sure that the right JBMAR versions
and the clusters are formed correctly.
JBMAR looks faster is most cases of async communications already. It's
worth noting that with sync, the differences are minimal, network and
waiting for responses is probably a bigger latency than what u can gain
with marshalling.
I'll run another batch of async tests to see whether it's clearer which
JBMAR version I should go for.
Note that in async mode and 8 nodes, I started to see some view changes
under load and also some NAKACK errors.
I'll move now to implement pooling and improvement explained in
https://jira.jboss.org/jira/browse/ISPN-59.
Regards,
Galder Zamarreno wrote:
Galder Zamarreno wrote:
>
>
> David M. Lloyd wrote:
>> OK, then I think there must be something outside of JBMAR that is
>> impacting this. I've gone through and literally removed a number of
>> the top hotspots from the profiler reports which should have made a
>> big difference if the reports were correct.
>>
>> Is there any way I can get ahold of your whole test case?
>
> I'm a real ^%%$£%:
>
> 1.- In the cluster tests I had run, the nodes never joined and hence
> never formed a cluster, so each node run independently!
> Todo: improve benchmark framework so that if a cluster test is being
> run with multiple nodes, the cluster view does indeed have that number
> of nodes!!
>
> 2.- More importantly, all along I've been ignoring
> cache-products/xyz/config.sh and hence when updating JBMAR, I was
> simply copying the folder, without updating config.sh. Result? All the
> JBMAR tests have been running with the very 1st JBMAR version tested.
Todo: cache-products/xyz/config.sh should not have the directory
hard-coded, it should retrieve the directory name of pwd or something
similar.
>
> Once again, I'm a real ^%%$£%^%*&%*£!!
>
> I'm working to fix these two issues asap and will come back with
> information asap.
>
>>
>> - DML
>>
>> On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
>>> Hey,
>>>
>>> Run a couple of round of tests with JBMAR trunk (r200) and please
>>> find attached the results. No real improvement I'm afraid. I'll look
>>> into the profile data from r200 tomorrow.
>>>
>>> I'm currently working on the pooling.
>>>
>>> Regards,
>>>
>>> David M. Lloyd wrote:
>>>> Galder, would you mind switching to trunk and trying that version
>>>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning and
>>>> get a source blob built asap!)?
>>>>
>>>> - DML
>>>>
>>>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>>>> Profiler data with JBMAR r174
>>>>>
>>>>> Galder Zamarreno wrote:
>>>>>> Hi David,
>>>>>>
>>>>>> Please find attach graphs belonging to two runs that compare:
>>>>>>
>>>>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar with
>>>>>> revision
>>>>>>
>>>>>> Not sure what's the conclusion here tbh. The results of 1.1.2
>>>>>> almost look opposite in each test.
>>>>>>
>>>>>> I've also attached some information from previously run
profiling
>>>>>> sessions with a couple of local machines we have in Neuchatel. I
>>>>>> profiled the faster of the two machines.
>>>>>>
>>>>>> Actually, looking at this profiled data, these tests are for
>>>>>> synchronous replicated caches but I see no traces of actually
>>>>>> reading the stream, only writing to it, hmmmm.
>>>>>>
>>>>>> I'm adding Externalizers to class table and implementing
>>>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>>>
>>>>>> Regards,
>>>>>>
>>>>>> David M. Lloyd wrote:
>>>>>>> OK, I tried out a few things. You might want to try
introducing
>>>>>>> these one at a time (i.e. update up to rev 173, then 174,
then
>>>>>>> 175 and see how each one does). In particular, I think 175
has
>>>>>>> just as much chance of slowing things down as speeding them
up -
>>>>>>> either you're getting tons of collisions in the hash
table or
>>>>>>> the profiler is skewing the results there (maybe try
filtering
>>>>>>> out org.jboss.marshalling.util.IdentityIntMap and
>>>>>>> java.lang.System to see if that gives a different picture).
>>>>>>>
>>>>>>> I feel pretty good about 173 and 174 though I think the
profiler
>>>>>>> will skew 173 unless you have that UTFUtils filter installed.
>>>>>>> If 175 slows things down (outside of the profiler), let me
know
>>>>>>> and I'll revert it. None of my tests showed much
difference but
>>>>>>> I don't have any good benchmarks that really exercise
that code
>>>>>>> right now.
>>>>>>>
>>>>>>> There's a couple things left to try yet, like looking at
>>>>>>> replacing ConcurrentReferenceHashMap (assuming that isn't
the
>>>>>>> profiler again).
>>>>>>>
>>>>>>>
------------------------------------------------------------------------
>>>>>>>
>>>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500
(Fri,
>>>>>>> 08 May 2009) | 1 line
>>>>>>>
>>>>>>> Try a trick to decrease the liklihood of collisions
>>>>>>>
------------------------------------------------------------------------
>>>>>>>
>>>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500
(Fri,
>>>>>>> 08 May 2009) | 1 line
>>>>>>>
>>>>>>> Replacement caching is not economical; the cost is one extra
>>>>>>> hash table get for non-replaced objects, two hash table gets
>>>>>>> (total) for replaced objects. Removing the cache gets rid of
>>>>>>> the cost for non-replaced objects, while replaced objects now
>>>>>>> have to be replaced again before the single hash table hit.
>>>>>>>
------------------------------------------------------------------------
>>>>>>>
>>>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500
(Thu,
>>>>>>> 07 May 2009) | 1 line
>>>>>>>
>>>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>>>
------------------------------------------------------------------------
>>>>>>>
>>>>>>>
>>>>>>> - DML
>>>>>>
>>>>>
>>>
>>>
>>> ------------------------------------------------------------------------
>>>
>>>
>>>
>>> ------------------------------------------------------------------------
>>>
>>>
>>>
>>> ------------------------------------------------------------------------
>>>
>>>
>>>
>>> ------------------------------------------------------------------------
>>>
>>>
>
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1:55 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Galder Zamarreno wrote:
I've managed to get tests run making sure that the right JBMAR
versions
and the clusters are formed correctly.
JBMAR looks faster is most cases of async communications already. It's
worth noting that with sync, the differences are minimal, network and
waiting for responses is probably a bigger latency than what u can gain
with marshalling.
I'll run another batch of async tests to see whether it's clearer which
JBMAR version I should go for.
Note that in async mode and 8 nodes, I started to see some view changes
under load and also some NAKACK errors.
I'll move now to implement pooling and improvement explained in
https://jira.jboss.org/jira/browse/ISPN-59.
Manik, once I've done these two, I'll have a look at your two marshaller
related emails and will port whatever is necessary to the JBMAR.
Regards,
Galder Zamarreno wrote:
>
>
> Galder Zamarreno wrote:
>>
>>
>> David M. Lloyd wrote:
>>> OK, then I think there must be something outside of JBMAR that is
>>> impacting this. I've gone through and literally removed a number of
>>> the top hotspots from the profiler reports which should have made a
>>> big difference if the reports were correct.
>>>
>>> Is there any way I can get ahold of your whole test case?
>>
>> I'm a real ^%%$£%:
>>
>> 1.- In the cluster tests I had run, the nodes never joined and hence
>> never formed a cluster, so each node run independently!
>> Todo: improve benchmark framework so that if a cluster test is being
>> run with multiple nodes, the cluster view does indeed have that
>> number of nodes!!
>>
>> 2.- More importantly, all along I've been ignoring
>> cache-products/xyz/config.sh and hence when updating JBMAR, I was
>> simply copying the folder, without updating config.sh. Result? All
>> the JBMAR tests have been running with the very 1st JBMAR version
>> tested.
>
> Todo: cache-products/xyz/config.sh should not have the directory
> hard-coded, it should retrieve the directory name of pwd or something
> similar.
>
>>
>> Once again, I'm a real ^%%$£%^%*&%*£!!
>>
>> I'm working to fix these two issues asap and will come back with
>> information asap.
>>
>>>
>>> - DML
>>>
>>> On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
>>>> Hey,
>>>>
>>>> Run a couple of round of tests with JBMAR trunk (r200) and please
>>>> find attached the results. No real improvement I'm afraid. I'll
>>>> look into the profile data from r200 tomorrow.
>>>>
>>>> I'm currently working on the pooling.
>>>>
>>>> Regards,
>>>>
>>>> David M. Lloyd wrote:
>>>>> Galder, would you mind switching to trunk and trying that version
>>>>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning
>>>>> and get a source blob built asap!)?
>>>>>
>>>>> - DML
>>>>>
>>>>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>>>>> Profiler data with JBMAR r174
>>>>>>
>>>>>> Galder Zamarreno wrote:
>>>>>>> Hi David,
>>>>>>>
>>>>>>> Please find attach graphs belonging to two runs that
compare:
>>>>>>>
>>>>>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>>>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>>>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar
with
>>>>>>> revision
>>>>>>>
>>>>>>> Not sure what's the conclusion here tbh. The results of
1.1.2
>>>>>>> almost look opposite in each test.
>>>>>>>
>>>>>>> I've also attached some information from previously run
>>>>>>> profiling sessions with a couple of local machines we have in
>>>>>>> Neuchatel. I profiled the faster of the two machines.
>>>>>>>
>>>>>>> Actually, looking at this profiled data, these tests are for
>>>>>>> synchronous replicated caches but I see no traces of actually
>>>>>>> reading the stream, only writing to it, hmmmm.
>>>>>>>
>>>>>>> I'm adding Externalizers to class table and implementing
>>>>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>>>>
>>>>>>> Regards,
>>>>>>>
>>>>>>> David M. Lloyd wrote:
>>>>>>>> OK, I tried out a few things. You might want to try
>>>>>>>> introducing these one at a time (i.e. update up to rev
173,
>>>>>>>> then 174, then 175 and see how each one does). In
particular,
>>>>>>>> I think 175 has just as much chance of slowing things
down as
>>>>>>>> speeding them up - either you're getting tons of
collisions in
>>>>>>>> the hash table or the profiler is skewing the results
there
>>>>>>>> (maybe try filtering out
>>>>>>>> org.jboss.marshalling.util.IdentityIntMap and
java.lang.System
>>>>>>>> to see if that gives a different picture).
>>>>>>>>
>>>>>>>> I feel pretty good about 173 and 174 though I think the
>>>>>>>> profiler will skew 173 unless you have that UTFUtils
filter
>>>>>>>> installed. If 175 slows things down (outside of the
profiler),
>>>>>>>> let me know and I'll revert it. None of my tests
showed much
>>>>>>>> difference but I don't have any good benchmarks that
really
>>>>>>>> exercise that code right now.
>>>>>>>>
>>>>>>>> There's a couple things left to try yet, like looking
at
>>>>>>>> replacing ConcurrentReferenceHashMap (assuming that
isn't the
>>>>>>>> profiler again).
>>>>>>>>
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500
(Fri,
>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>
>>>>>>>> Try a trick to decrease the liklihood of collisions
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500
(Fri,
>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>
>>>>>>>> Replacement caching is not economical; the cost is one
extra
>>>>>>>> hash table get for non-replaced objects, two hash table
gets
>>>>>>>> (total) for replaced objects. Removing the cache gets
rid of
>>>>>>>> the cost for non-replaced objects, while replaced objects
now
>>>>>>>> have to be replaced again before the single hash table
hit.
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500
(Thu,
>>>>>>>> 07 May 2009) | 1 line
>>>>>>>>
>>>>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>>
>>>>>>>> - DML
>>>>>>>
>>>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>
>
------------------------------------------------------------------------
This body part will be downloaded on demand.
--
Galder Zamarreño
Sr. Software Maintenance Engineer
JBoss, a division of Red Hat
2:08 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Great news :) I'm excited to see how it performs once you put in the rest
of the optimizations.
- DML
On 05/13/2009 01:42 PM, Galder Zamarreno wrote:
I've managed to get tests run making sure that the right JBMAR
versions
and the clusters are formed correctly.
JBMAR looks faster is most cases of async communications already. It's
worth noting that with sync, the differences are minimal, network and
waiting for responses is probably a bigger latency than what u can gain
with marshalling.
I'll run another batch of async tests to see whether it's clearer which
JBMAR version I should go for.
Note that in async mode and 8 nodes, I started to see some view changes
under load and also some NAKACK errors.
I'll move now to implement pooling and improvement explained in
https://jira.jboss.org/jira/browse/ISPN-59.
Regards,
Galder Zamarreno wrote:
>
>
> Galder Zamarreno wrote:
>>
>>
>> David M. Lloyd wrote:
>>> OK, then I think there must be something outside of JBMAR that is
>>> impacting this. I've gone through and literally removed a number of
>>> the top hotspots from the profiler reports which should have made a
>>> big difference if the reports were correct.
>>>
>>> Is there any way I can get ahold of your whole test case?
>>
>> I'm a real ^%%$£%:
>>
>> 1.- In the cluster tests I had run, the nodes never joined and hence
>> never formed a cluster, so each node run independently!
>> Todo: improve benchmark framework so that if a cluster test is being
>> run with multiple nodes, the cluster view does indeed have that
>> number of nodes!!
>>
>> 2.- More importantly, all along I've been ignoring
>> cache-products/xyz/config.sh and hence when updating JBMAR, I was
>> simply copying the folder, without updating config.sh. Result? All
>> the JBMAR tests have been running with the very 1st JBMAR version
>> tested.
>
> Todo: cache-products/xyz/config.sh should not have the directory
> hard-coded, it should retrieve the directory name of pwd or something
> similar.
>
>>
>> Once again, I'm a real ^%%$£%^%*&%*£!!
>>
>> I'm working to fix these two issues asap and will come back with
>> information asap.
>>
>>>
>>> - DML
>>>
>>> On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
>>>> Hey,
>>>>
>>>> Run a couple of round of tests with JBMAR trunk (r200) and please
>>>> find attached the results. No real improvement I'm afraid. I'll
>>>> look into the profile data from r200 tomorrow.
>>>>
>>>> I'm currently working on the pooling.
>>>>
>>>> Regards,
>>>>
>>>> David M. Lloyd wrote:
>>>>> Galder, would you mind switching to trunk and trying that version
>>>>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning
>>>>> and get a source blob built asap!)?
>>>>>
>>>>> - DML
>>>>>
>>>>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>>>>> Profiler data with JBMAR r174
>>>>>>
>>>>>> Galder Zamarreno wrote:
>>>>>>> Hi David,
>>>>>>>
>>>>>>> Please find attach graphs belonging to two runs that
compare:
>>>>>>>
>>>>>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>>>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>>>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar
with
>>>>>>> revision
>>>>>>>
>>>>>>> Not sure what's the conclusion here tbh. The results of
1.1.2
>>>>>>> almost look opposite in each test.
>>>>>>>
>>>>>>> I've also attached some information from previously run
>>>>>>> profiling sessions with a couple of local machines we have in
>>>>>>> Neuchatel. I profiled the faster of the two machines.
>>>>>>>
>>>>>>> Actually, looking at this profiled data, these tests are for
>>>>>>> synchronous replicated caches but I see no traces of actually
>>>>>>> reading the stream, only writing to it, hmmmm.
>>>>>>>
>>>>>>> I'm adding Externalizers to class table and implementing
>>>>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>>>>
>>>>>>> Regards,
>>>>>>>
>>>>>>> David M. Lloyd wrote:
>>>>>>>> OK, I tried out a few things. You might want to try
>>>>>>>> introducing these one at a time (i.e. update up to rev
173,
>>>>>>>> then 174, then 175 and see how each one does). In
particular,
>>>>>>>> I think 175 has just as much chance of slowing things
down as
>>>>>>>> speeding them up - either you're getting tons of
collisions in
>>>>>>>> the hash table or the profiler is skewing the results
there
>>>>>>>> (maybe try filtering out
>>>>>>>> org.jboss.marshalling.util.IdentityIntMap and
java.lang.System
>>>>>>>> to see if that gives a different picture).
>>>>>>>>
>>>>>>>> I feel pretty good about 173 and 174 though I think the
>>>>>>>> profiler will skew 173 unless you have that UTFUtils
filter
>>>>>>>> installed. If 175 slows things down (outside of the
profiler),
>>>>>>>> let me know and I'll revert it. None of my tests
showed much
>>>>>>>> difference but I don't have any good benchmarks that
really
>>>>>>>> exercise that code right now.
>>>>>>>>
>>>>>>>> There's a couple things left to try yet, like looking
at
>>>>>>>> replacing ConcurrentReferenceHashMap (assuming that
isn't the
>>>>>>>> profiler again).
>>>>>>>>
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500
(Fri,
>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>
>>>>>>>> Try a trick to decrease the liklihood of collisions
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500
(Fri,
>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>
>>>>>>>> Replacement caching is not economical; the cost is one
extra
>>>>>>>> hash table get for non-replaced objects, two hash table
gets
>>>>>>>> (total) for replaced objects. Removing the cache gets
rid of
>>>>>>>> the cost for non-replaced objects, while replaced objects
now
>>>>>>>> have to be replaced again before the single hash table
hit.
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500
(Thu,
>>>>>>>> 07 May 2009) | 1 line
>>>>>>>>
>>>>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>>
>>>>>>>> - DML
>>>>>>>
>>>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>
>
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------

2:56 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Are we also testing that the marshalled data is no bigger in size than
the current marshalling ?
Maybe a unit test, e.g. to verify that a Boolean gets marshalled to 1 or
2 bytes and not 22 like with ObjectOutputStream.writeObject() !
Galder Zamarreno wrote:
I've managed to get tests run making sure that the right JBMAR
versions and the clusters are formed correctly.
JBMAR looks faster is most cases of async communications already. It's
worth noting that with sync, the differences are minimal, network and
waiting for responses is probably a bigger latency than what u can
gain with marshalling.
I'll run another batch of async tests to see whether it's clearer
which JBMAR version I should go for.
Note that in async mode and 8 nodes, I started to see some view
changes under load and also some NAKACK errors.
I'll move now to implement pooling and improvement explained in
https://jira.jboss.org/jira/browse/ISPN-59.
Regards,
Galder Zamarreno wrote:
>
>
> Galder Zamarreno wrote:
>>
>>
>> David M. Lloyd wrote:
>>> OK, then I think there must be something outside of JBMAR that is
>>> impacting this. I've gone through and literally removed a number
>>> of the top hotspots from the profiler reports which should have
>>> made a big difference if the reports were correct.
>>>
>>> Is there any way I can get ahold of your whole test case?
>>
>> I'm a real ^%%$£%:
>>
>> 1.- In the cluster tests I had run, the nodes never joined and hence
>> never formed a cluster, so each node run independently!
>> Todo: improve benchmark framework so that if a cluster test is being
>> run with multiple nodes, the cluster view does indeed have that
>> number of nodes!!
>>
>> 2.- More importantly, all along I've been ignoring
>> cache-products/xyz/config.sh and hence when updating JBMAR, I was
>> simply copying the folder, without updating config.sh. Result? All
>> the JBMAR tests have been running with the very 1st JBMAR version
>> tested.
>
> Todo: cache-products/xyz/config.sh should not have the directory
> hard-coded, it should retrieve the directory name of pwd or something
> similar.
>
>>
>> Once again, I'm a real ^%%$£%^%*&%*£!!
>>
>> I'm working to fix these two issues asap and will come back with
>> information asap.
>>
>>>
>>> - DML
>>>
>>> On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
>>>> Hey,
>>>>
>>>> Run a couple of round of tests with JBMAR trunk (r200) and please
>>>> find attached the results. No real improvement I'm afraid. I'll
>>>> look into the profile data from r200 tomorrow.
>>>>
>>>> I'm currently working on the pooling.
>>>>
>>>> Regards,
>>>>
>>>> David M. Lloyd wrote:
>>>>> Galder, would you mind switching to trunk and trying that version
>>>>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the versioning
>>>>> and get a source blob built asap!)?
>>>>>
>>>>> - DML
>>>>>
>>>>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>>>>> Profiler data with JBMAR r174
>>>>>>
>>>>>> Galder Zamarreno wrote:
>>>>>>> Hi David,
>>>>>>>
>>>>>>> Please find attach graphs belonging to two runs that
compare:
>>>>>>>
>>>>>>> infinispan-4.0.0(repl-sync) - home grown marshalling layer
>>>>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar 1.1.2
>>>>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan + jbmar
>>>>>>> with revision
>>>>>>>
>>>>>>> Not sure what's the conclusion here tbh. The results of
1.1.2
>>>>>>> almost look opposite in each test.
>>>>>>>
>>>>>>> I've also attached some information from previously run
>>>>>>> profiling sessions with a couple of local machines we have in
>>>>>>> Neuchatel. I profiled the faster of the two machines.
>>>>>>>
>>>>>>> Actually, looking at this profiled data, these tests are for
>>>>>>> synchronous replicated caches but I see no traces of actually
>>>>>>> reading the stream, only writing to it, hmmmm.
>>>>>>>
>>>>>>> I'm adding Externalizers to class table and implementing
>>>>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>>>>
>>>>>>> Regards,
>>>>>>>
>>>>>>> David M. Lloyd wrote:
>>>>>>>> OK, I tried out a few things. You might want to try
>>>>>>>> introducing these one at a time (i.e. update up to rev
173,
>>>>>>>> then 174, then 175 and see how each one does). In
particular,
>>>>>>>> I think 175 has just as much chance of slowing things
down as
>>>>>>>> speeding them up - either you're getting tons of
collisions in
>>>>>>>> the hash table or the profiler is skewing the results
there
>>>>>>>> (maybe try filtering out
>>>>>>>> org.jboss.marshalling.util.IdentityIntMap and
java.lang.System
>>>>>>>> to see if that gives a different picture).
>>>>>>>>
>>>>>>>> I feel pretty good about 173 and 174 though I think the
>>>>>>>> profiler will skew 173 unless you have that UTFUtils
filter
>>>>>>>> installed. If 175 slows things down (outside of the
>>>>>>>> profiler), let me know and I'll revert it. None of
my tests
>>>>>>>> showed much difference but I don't have any good
benchmarks
>>>>>>>> that really exercise that code right now.
>>>>>>>>
>>>>>>>> There's a couple things left to try yet, like looking
at
>>>>>>>> replacing ConcurrentReferenceHashMap (assuming that
isn't the
>>>>>>>> profiler again).
>>>>>>>>
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46 -0500
(Fri,
>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>
>>>>>>>> Try a trick to decrease the liklihood of collisions
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39 -0500
(Fri,
>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>
>>>>>>>> Replacement caching is not economical; the cost is one
extra
>>>>>>>> hash table get for non-replaced objects, two hash table
gets
>>>>>>>> (total) for replaced objects. Removing the cache gets
rid of
>>>>>>>> the cost for non-replaced objects, while replaced objects
now
>>>>>>>> have to be replaced again before the single hash table
hit.
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52 -0500
(Thu,
>>>>>>>> 07 May 2009) | 1 line
>>>>>>>>
>>>>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>
>>>>>>>>
>>>>>>>> - DML
>>>>>>>
>>>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>>>
>>>> ------------------------------------------------------------------------
>>>>
>>>>
>>
>
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------
------------------------------------------------------------------------
_______________________________________________
infinispan-dev mailing list
infinispan-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/infinispan-dev
--
Bela Ban
Lead JGroups / Clustering Team
JBoss - a division of Red Hat
3:28 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Yes, Galder has such a test. :-) And yes, JBoss Marshalling writes
booleans as a single byte (or, in the case of boolean[], a single bit).
The test won't likely pass fully until Galder reimplements the custom
marshalling parts as ObjectTable instead of Externalizers. With the
current Externalizer-based design, it might write:
- This is an externalized object = 1 byte
- The class of the externalized object is in the class table = 1 byte
- The class table entry for the externalized class = 1 byte
- The externalizer object is predefined = 1 byte
- This is the custom ID of the externalizer object = 1 byte
- Begin custom object data = 1 byte
- Custom object data length = 1-4 bytes depending on N
- This is the custom object data = N bytes
- End custom data = 1 byte
Giving 8+N to 11+N bytes or more, depending on the mix of objects and
primitive data in the custom data block, due to the security features in
Externalizers which are not needed in ISPN. With an object table it would
write:
- This object is predefined = 1 byte
- This is the custom ID of the predefined object = 1 byte
- This is the custom object data = N bytes
Giving a constant 2+N bytes for custom objects with no additional overhead
for regular serialized or externalized user objects. This is what we're
talking about in that IRC transcript in ISPN-59.
- DML
On 05/13/2009 02:56 PM, Bela Ban wrote:
Are we also testing that the marshalled data is no bigger in size
than
the current marshalling ?
Maybe a unit test, e.g. to verify that a Boolean gets marshalled to 1 or
2 bytes and not 22 like with ObjectOutputStream.writeObject() !
Galder Zamarreno wrote:
> I've managed to get tests run making sure that the right JBMAR
> versions and the clusters are formed correctly.
>
> JBMAR looks faster is most cases of async communications already. It's
> worth noting that with sync, the differences are minimal, network and
> waiting for responses is probably a bigger latency than what u can
> gain with marshalling.
>
> I'll run another batch of async tests to see whether it's clearer
> which JBMAR version I should go for.
>
> Note that in async mode and 8 nodes, I started to see some view
> changes under load and also some NAKACK errors.
>
> I'll move now to implement pooling and improvement explained in
> https://jira.jboss.org/jira/browse/ISPN-59.
>
> Regards,
>
> Galder Zamarreno wrote:
>>
>>
>> Galder Zamarreno wrote:
>>>
>>>
>>> David M. Lloyd wrote:
>>>> OK, then I think there must be something outside of JBMAR that is
>>>> impacting this. I've gone through and literally removed a number
>>>> of the top hotspots from the profiler reports which should have
>>>> made a big difference if the reports were correct.
>>>>
>>>> Is there any way I can get ahold of your whole test case?
>>>
>>> I'm a real ^%%$£%:
>>>
>>> 1.- In the cluster tests I had run, the nodes never joined and hence
>>> never formed a cluster, so each node run independently!
>>> Todo: improve benchmark framework so that if a cluster test is being
>>> run with multiple nodes, the cluster view does indeed have that
>>> number of nodes!!
>>>
>>> 2.- More importantly, all along I've been ignoring
>>> cache-products/xyz/config.sh and hence when updating JBMAR, I was
>>> simply copying the folder, without updating config.sh. Result? All
>>> the JBMAR tests have been running with the very 1st JBMAR version
>>> tested.
>>
>> Todo: cache-products/xyz/config.sh should not have the directory
>> hard-coded, it should retrieve the directory name of pwd or something
>> similar.
>>
>>>
>>> Once again, I'm a real ^%%$£%^%*&%*£!!
>>>
>>> I'm working to fix these two issues asap and will come back with
>>> information asap.
>>>
>>>>
>>>> - DML
>>>>
>>>> On 05/11/2009 11:06 AM, Galder Zamarreno wrote:
>>>>> Hey,
>>>>>
>>>>> Run a couple of round of tests with JBMAR trunk (r200) and please
>>>>> find attached the results. No real improvement I'm afraid.
I'll
>>>>> look into the profile data from r200 tomorrow.
>>>>>
>>>>> I'm currently working on the pooling.
>>>>>
>>>>> Regards,
>>>>>
>>>>> David M. Lloyd wrote:
>>>>>> Galder, would you mind switching to trunk and trying that version
>>>>>> (unofficial 1.2.0.CR1 - yes I *promise* I'll fix the
versioning
>>>>>> and get a source blob built asap!)?
>>>>>>
>>>>>> - DML
>>>>>>
>>>>>> On 05/08/2009 12:09 PM, Galder Zamarreno wrote:
>>>>>>> Profiler data with JBMAR r174
>>>>>>>
>>>>>>> Galder Zamarreno wrote:
>>>>>>>> Hi David,
>>>>>>>>
>>>>>>>> Please find attach graphs belonging to two runs that
compare:
>>>>>>>>
>>>>>>>> infinispan-4.0.0(repl-sync) - home grown marshalling
layer
>>>>>>>> infinispan-4.0.0(repl-sync-jbmar) - infinispan + jbmar
1.1.2
>>>>>>>> infinispan-4.0.0(repl-sync-jbmar)-rXYZ - infinispan +
jbmar
>>>>>>>> with revision
>>>>>>>>
>>>>>>>> Not sure what's the conclusion here tbh. The results
of 1.1.2
>>>>>>>> almost look opposite in each test.
>>>>>>>>
>>>>>>>> I've also attached some information from previously
run
>>>>>>>> profiling sessions with a couple of local machines we
have in
>>>>>>>> Neuchatel. I profiled the faster of the two machines.
>>>>>>>>
>>>>>>>> Actually, looking at this profiled data, these tests are
for
>>>>>>>> synchronous replicated caches but I see no traces of
actually
>>>>>>>> reading the stream, only writing to it, hmmmm.
>>>>>>>>
>>>>>>>> I'm adding Externalizers to class table and
implementing
>>>>>>>> marshaller/unmarshaller pooling as my next tasks.
>>>>>>>>
>>>>>>>> Regards,
>>>>>>>>
>>>>>>>> David M. Lloyd wrote:
>>>>>>>>> OK, I tried out a few things. You might want to try
>>>>>>>>> introducing these one at a time (i.e. update up to
rev 173,
>>>>>>>>> then 174, then 175 and see how each one does). In
particular,
>>>>>>>>> I think 175 has just as much chance of slowing things
down as
>>>>>>>>> speeding them up - either you're getting tons of
collisions in
>>>>>>>>> the hash table or the profiler is skewing the results
there
>>>>>>>>> (maybe try filtering out
>>>>>>>>> org.jboss.marshalling.util.IdentityIntMap and
java.lang.System
>>>>>>>>> to see if that gives a different picture).
>>>>>>>>>
>>>>>>>>> I feel pretty good about 173 and 174 though I think
the
>>>>>>>>> profiler will skew 173 unless you have that UTFUtils
filter
>>>>>>>>> installed. If 175 slows things down (outside of the
>>>>>>>>> profiler), let me know and I'll revert it. None
of my tests
>>>>>>>>> showed much difference but I don't have any good
benchmarks
>>>>>>>>> that really exercise that code right now.
>>>>>>>>>
>>>>>>>>> There's a couple things left to try yet, like
looking at
>>>>>>>>> replacing ConcurrentReferenceHashMap (assuming that
isn't the
>>>>>>>>> profiler again).
>>>>>>>>>
>>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>>
>>>>>>>>> r175 | david.lloyd(a)jboss.com | 2009-05-08 00:17:46
-0500 (Fri,
>>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>>
>>>>>>>>> Try a trick to decrease the liklihood of collisions
>>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>>
>>>>>>>>> r174 | david.lloyd(a)jboss.com | 2009-05-08 00:04:39
-0500 (Fri,
>>>>>>>>> 08 May 2009) | 1 line
>>>>>>>>>
>>>>>>>>> Replacement caching is not economical; the cost is
one extra
>>>>>>>>> hash table get for non-replaced objects, two hash
table gets
>>>>>>>>> (total) for replaced objects. Removing the cache
gets rid of
>>>>>>>>> the cost for non-replaced objects, while replaced
objects now
>>>>>>>>> have to be replaced again before the single hash
table hit.
>>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>>
>>>>>>>>> r173 | david.lloyd(a)jboss.com | 2009-05-07 23:44:52
-0500 (Thu,
>>>>>>>>> 07 May 2009) | 1 line
>>>>>>>>>
>>>>>>>>> JBMAR-52 - Avoid extra copy of char array (1.5 of 2)
>>>>>>>>>
------------------------------------------------------------------------
>>>>>>>>>
>>>>>>>>>
>>>>>>>>> - DML
>>>>>>>>
>>>>>>>
>>>>>
>>>>>
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>>
>>>>>
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>>
>>>>>
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>>
>>>>>
>>>>>
------------------------------------------------------------------------
>>>>>
>>>>>
>>>
>>
>
>
> ------------------------------------------------------------------------
>
>
> ------------------------------------------------------------------------
>
>
> ------------------------------------------------------------------------
>
>
> ------------------------------------------------------------------------
>
> ------------------------------------------------------------------------
>
> _______________________________________________
> infinispan-dev mailing list
> infinispan-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/infinispan-dev

5:02 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
On 13 May 2009, at 21:28, David M. Lloyd wrote:
- This object is predefined = 1 byte
- This is the custom ID of the predefined object = 1 byte
- This is the custom object data = N bytes
Can't the first 2 be combined into a single byte? That's what I do in
my hand-wired marshaller. I assume that all objects are predefined,
and use a special, reserved 'custom ID' to denote that the object is
*not* predefined. Basically, I serialize a boolean into 2 bytes.
Cheers,
--
Manik Surtani
manik(a)jboss.org
Lead, Infinispan
Lead, JBoss Cache
http://www.infinispan.org
http://www.jbosscache.org
5:38 p.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
On 05/13/2009 05:02 PM, Manik Surtani wrote:
On 13 May 2009, at 21:28, David M. Lloyd wrote:
> - This object is predefined = 1 byte
> - This is the custom ID of the predefined object = 1 byte
> - This is the custom object data = N bytes
Can't the first 2 be combined into a single byte? That's what I do in
my hand-wired marshaller. I assume that all objects are predefined, and
use a special, reserved 'custom ID' to denote that the object is *not*
predefined. Basically, I serialize a boolean into 2 bytes.
Sure, you needed to do that because you included all the basic primitive
wrapper types and other stuff as custom objects. River already optimizes
these down to a very small number of bytes (1 byte for Boolean and Byte, 2
bytes for Short, etc., plus one byte in the case where there needs to be a
class descriptor).
Also, I believe I can squeeze more bytes out of your custom marshallers as
well - I'll look them over once Galder is done.
- DML
1:41 a.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
Exactly. We're talking about 2 types of types: the finite set of types
used by JBC itself, and user-defined data types. For the former, we can
do (IMO) with encoding the type in 7 bits, for the latter we could use a
predefined type of USER and that then uses the JBMAR mechanism
Manik Surtani wrote:
On 13 May 2009, at 21:28, David M. Lloyd wrote:
> - This object is predefined = 1 byte
> - This is the custom ID of the predefined object = 1 byte
> - This is the custom object data = N bytes
Can't the first 2 be combined into a single byte? That's what I do in
my hand-wired marshaller. I assume that all objects are predefined,
and use a special, reserved 'custom ID' to denote that the object is
*not* predefined. Basically, I serialize a boolean into 2 bytes.
--
Bela Ban
Lead JGroups / Clustering Team
JBoss - a division of Red Hat
1:38 a.m.
New subject: JProfiler snapshots for Infinispan+JBMAR
David M. Lloyd wrote:
Yes, Galder has such a test. :-) And yes, JBoss Marshalling writes
booleans as a single byte
Do you encode the value and type into the single byte ? Assuming you
need 1 bit for the value, you have 7 bits left for the type, which
leaves you with ~ 128 types. Is this assumption correct ?
(or, in the case of boolean[], a single bit).
How ?
The test won't likely pass fully until Galder reimplements the
custom
marshalling parts as ObjectTable instead of Externalizers. With the
current Externalizer-based design, it might write:
- This is an externalized object = 1 byte
- The class of the externalized object is in the class table = 1 byte
- The class table entry for the externalized class = 1 byte
- The externalizer object is predefined = 1 byte
- This is the custom ID of the externalizer object = 1 byte
- Begin custom object data = 1 byte
- Custom object data length = 1-4 bytes depending on N
- This is the custom object data = N bytes
- End custom data = 1 byte
Giving 8+N to 11+N bytes or more, depending on the mix of objects and
primitive data in the custom data block, due to the security features
in Externalizers which are not needed in ISPN. With an object table
it would write:
- This object is predefined = 1 byte
- This is the custom ID of the predefined object = 1 byte
- This is the custom object data = N bytes
This is 3 bytes compared to the 2 currently used, and - as you said
above - I think we can even get down to only 1 byte for a boolean (or
Boolean). I don't want to nitpick, but can't we get JBMAR to marshall a
boolean into 1 byte ? If we send 10 million messages with a boolean,
then the overhead gets quite large !
--
Bela Ban
Lead JGroups / Clustering Team
JBoss - a division of Red Hat
6215
days inactive
6221
days old
infinispan-dev@lists.jboss.org
17 comments
4 participants
participants (4)
-
 Bela Ban
Bela Ban -
 David M. Lloyd
David M. Lloyd -
 Galder Zamarreno
Galder Zamarreno -
 Manik Surtani
Manik Surtani