
9:33 a.m.
Hi Manik,
On 3/9/11 11:30 AM, Manik Surtani wrote:
Sorry I haven't responded on this thread till now, somehow
slipped my attention. P/B is interesting, I have a few thoughts:
* How do you pick which is the primary?
The primary matches with the
coordinator in the JGroups view
(EmbeddedCacheManager.isCoordinator()).
First owner on a list of owners for a key obtained via consistent
hash? What if this owner is not the peer on which your transaction is running? Do you
eagerly acquire locks on the single owner?
* How does this deal with transactions spanning> 1 key, mapped to> 1
"primary" node?
As Paolo already said, we use a fully replication
mode in which
every node maintains all copies of the same data items and we don't
adopt an eager locking strategy.
* I presume you introduce a window of inconsistency when (a) a tx
commits to a primary node and (b) the primary node pushes changes to its backups. Is the
latter an async or batched process?
Why? Before a tx finalizes the commit on
the primary, all the
"modifications" are synchronously replicated to the other nodes (the
backups). This means that the primary waits for acknowledgments from all
backups and then it can apply the updates to the data container and
release the locks relevant to the written items.
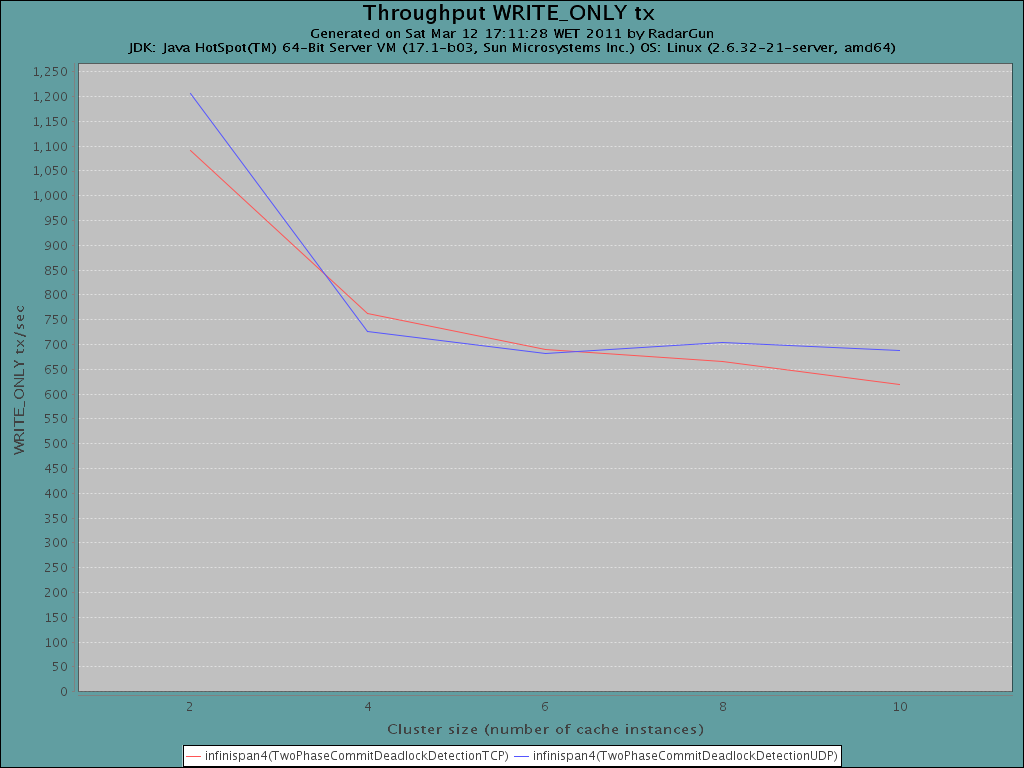
* Any thoughts on why - as per your graphs - P/B performance degrades
as cluster size increases?
The first attached graph highlights that this
behavior is
influenced on the time spent to commit for a transaction executed on the
primary node (a write transaction). In fact, as cluster size increases,
the average commit duration increases while the average execution
duration (after-commit) remains more or less uniform. Given that we are
using UDP as transport layer in JGroups stack, we suppose that the
aforementioned behavior is caused by the increasing of network
collisions on the acknowledgments from the backups.
In order to attempt to verify this assumption, we ran a test with TCP
rather than UDP using Primary-Backup only. The results are reported in
the second attached graph, highlighting that, as the number of nodes grows,
TCP achieves remarkably higher performance vs UDP. This is somewhat
surprising giving that the overhead to disseminate the updates on the
Primary should be lower with UDP than with TCP.
The only explanation we could come up with up to now is the increase of
collisions on the return of ACKs to the backups, as we already mentioned.
What do you think? Do you believe that Jgroups gathers any statistics
about UDP collisions? That would of course allow us to confirm/reject
our theory.
As we were curious, we ran a comparative test with 2PC (with deadlock
detection and 1000 keys) with UDP vs TCP (also in attach). The
performances here do not really change... we imagine that this depends
on the fact that, in this case, since we are at high contention, the
nodes are less synchronized in the return of the vote messages to the
coordinator (due to the high probability of encountering lock
contention... and that this may reduce the number of collisions.
The results were obtained by running the same experiments described in
the first mail (in the case of 1000 keys).
Cheers
Sebastiano
Cheers
Manik
On 11 Feb 2011, at 17:56, Sebastiano Peluso wrote:
> Hi all,
>
> first let us introduce ourselves given that it's the first time we write in this
mailing list.
>
> Our names are Sebastiano Peluso and Diego Didona, and we are working at INESC-ID
Lisbon in the context of the Cloud-TM project. Our work is framed in the context of
self-adaptive replication mechanisms (please refer to previous message by Paolo on this
mailing list and to the www.cloudtm.eu website for additional details on this project).
>
> Up to date we have been working on developing a relatively simple primary-backup (PB)
replication mechanism, which we integrated within Infinispan 4.2 and 5.0. In this kind of
scheme only one node (called the primary) is allowed to process update transactions,
whereas the remaining nodes only process read-only transactions. This allows coping very
efficiently with write transactions, as the primary does not have to incur in the cost of
remote coordination schemes nor in distributed deadlocks, which can hamper performance at
high contention with two phase commit schemes. With PB, in fact, the primary can serialize
transactions locally, and simply propagate the updates to the backups for fault-tolerance
as well as to allow them to process read-only transactions on fresh data of course. On the
other hand, the primary is clearly prone to become the bottleneck especially in large
clusters and write intensive workloads.
>
> Thus, this scheme does not really represent a replacement for the default 2PC
protocol, but rather an alternative approach that results particularly attractive (as we
will illustrate in the following with some radargun-based performance results) in small
scale clusters, or, in "elastic" cloud scenarios, in periods where the workload
is either read dominated or not very intense. Being this scheme particularly efficient in
these scenarios, in fact, its adoption would allow to minimize the number of resources
acquired from the cloud provider in these periods, with direct benefits in terms of cost
reductions. In Cloud-TM, in fact, we aim at designing autonomic mechanisms that would
dynamically switch among multiple replication mechanisms depending on the current workload
characteristics.
>
> Before discussing the results of our preliminary benchmarking study, we would like to
briefly overview how we integrated this replication mechanism within Infinispan. Any
comment/feedback is clearly highly appreciated. First of all we have defined a new
command, namely PassiveReplicationCommand, that is a subclass of PrepareCommand. We had to
define a new command because we had to design customized "visiting" methods for
the interceptors. Note that our protocol only affects the commit phase of a transaction,
specifically, during the prepare phase, in the prepare method of the TransactionXaAdapter
class, if the Primary Backup mode is enabled, then a PassiveReplicationCommand is built by
the CommandsFactory and it is passed to the invoke method of the invoker. The
PassiveReplicationCommand is then visited by the all the interceptors in the chain, by
means of the visitPassiveReplicationCommand methods. We describe more in detail the
operations performed by the non-trivial int!
erceptors:
> -TxInterceptor: like in the 2PC protocol, if the context is not originated locally,
then for each modification stored in the PassiveReplicationCommand the chain of
interceptors is invoked.
> -LockingInterceptor: first the next interceptor is called, then the cleanupLocks is
performed with the second parameter set to true (commit the operations). This operation is
always safe: on the primary it is called only after that the acks from all the slaves are
received (see the ReplicationInterceptor below); on the slave there are no concurrent
conflicting writes since these are already locally serialized by the locking scheme
performed at the primary.
> -ReplicationInterceptor: first it invokes the next iterceptor; then if the predicate
shouldInvokeRemoteTxCommand(ctx) is true, then the method
rpcManager.broadcastRpcCommand(command, true, false) is performed, that replicates the
modifications in a synchronous mode (waiting for an explicit ack from all the backups).
>
> As for the commit phase:
> -Given that in the Primary Backup the prepare phase works as a commit too, the commit
method on a TransactionXaAdapter object in this case simply returns.
>
> On the resulting extended Infinispan version a subset of unit/functional tests were
executed and successfully passed:
> - commands.CommandIdUniquenessTest
> - replication.SyncReplicatedAPITest
> - replication.SyncReplImplicitLockingTest
> - replication.SyncReplLockingTest
> - replication.SyncReplTest
> - replication.SyncCacheListenerTest
> - replication.ReplicationExceptionTest
>
>
> We have tested this solution using a customized version of Radargun. Our
customizations were first of all aimed at having each thread accessing data within
transactions, instead of executing single put/get operations. In addition, now every
Stresser thread accesses with uniform probability all of the keys stored by Infinispan,
thus generating conflicts with a probability proportional to the number of concurrently
active threads and inversely proportional to the total number of keys maintained.
>
> As already hinted, our results highlight that, depending on the current
workload/number of nodes in the system, it is possible to identify scenarios where the PB
scheme significantly outperforms the current 2PC scheme, and vice versa. Our experiments
were performed in a cluster of homogeneous 8-core (Xeon(a)2.16GhZ) nodes interconnected via
a Gigabit Ethernet and running a Linux Kernel 64 bit version 2.6.32-21-server. The results
were obtained by running for 30 seconds 8 parallel Stresser threads per nodes, and letting
the number of node vary from 2 to 10. In 2PC, each thread executes transactions which
consist of 10 (get/put) operations, with a 10% of probability of generating a put
operation. With PB, the same kind of transactions are executed on the primary, but the
backups execute read-only transactions composed of 10 get operations. This allows to
compare the maximum throughput of update transactions provided by the two compared
schemes, without excessively favoring PB !
by keeping the backups totally idle.
> The total write transactions' throughput exhibited by the cluster (i.e. not the
throughput per node) is shown in the attached plots, relevant to caches containing 1000,
10000 and 100000 keys. As already discussed, the lower the number of keys, the higher the
chance of contention and the probability of aborts due to conflicts. In particular with
the 2PC scheme the number of failed transactions steadily increases at high contention up
to 6% (to the best of our understanding in particular due to distributed deadlocks). With
PB, instead the number of failed txs due to contention is always 0.
>
> Note that, currently, we are assuming that backup nodes do not generate update
transactions. In practice this corresponds to assuming the presence of some load balancing
scheme which directs (all and only) update transactions to the primary node, and read
transactions to the backup. In the negative case (a put operation is generated on a backup
node), we simply throw a PassiveReplicationException at the CacheDelegate level. This is
probably suboptimal/undesirable in real settings, as update transactions may be
transparently rerouted (at least in principle!) to the primary node in a RPC-style. Any
suggestion on how to implement such a redirection facility in a transparent/non-intrusive
manner would be highly appreciated of course! ;-)
>
> To conclude, we are currently working on a statistical model that is able to predict
the best suited replication scheme given the current workload/number of machines, as well
as on a mechanism to dynamically switch from one replication scheme to the other.
>
>
> We'll keep you posted on our progresses!
>
> Regards,
> Sebastiano Peluso, Diego Didona
>
<PCvsPR_WRITE_TX_1000keys.png><PCvsPR_WRITE_TX_10000keys.png><PCvsPR_WRITE_TX_100000keys.png>_______________________________________________
> infinispan-dev mailing list
> infinispan-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/infinispan-dev
--
Manik Surtani
manik(a)jboss.org
twitter.com/maniksurtani
Lead, Infinispan
http://www.infinispan.org
_______________________________________________
infinispan-dev mailing list
infinispan-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/infinispan-dev
--
Sebastiano Peluso
GSD INESC-ID
{kind=link}
{kind=link}
{kind=link}