
9:46 a.m.
Hi Sebastian,
the "intelligent routing" of Hot Rod being one of - if not the main -
reason to use Hot Rod, I wonder if we shouldn't rather suggest people to
stick with HTTP (REST) in such architectures.
Several people have suggested in the past the need to have an HTTP smart
load balancer which would be able to route the external REST requests to
the right node. Essentially have people use REST over the wider network, up
to reaching the Infinispan cluster where the service endpoint (the load
balancer) can convert them to optimised Hot Rod calls, or just leave them
in the same format but routing them with the same intelligence to the right
nodes.
I realise my proposal requires some work on several fronts, at very least
we would need:
- feature parity Hot Rod / REST so that people can actually use it
- a REST load balancer
But I think the output of such a direction would be far more reusable, as
both these points are high on the wish list anyway.
Not least having a "REST load balancer" would allow to deploy Infinispan as
an HTTP cache; just honouring the HTTP caching protocols and existing
standards would allow people to use any client to their liking, without us
having to maintain Hot Rod clients and support it on many exotic platforms
- we would still have Hot Rod clients but we'd be able to pick a smaller
set of strategical platforms (e.g. Windows doesn't have to be in that list).
Such a load balancer could be written in Java (recent WildFly versions are
able to do this efficiently) or it could be written in another language,
all it takes is to integrate an Hot Rod client - or just the intelligence
of it- as an extension into an existing load balancer of our choice.
Allow me a bit more nit-picking on your benchmarks ;)
As you pointed out yourself there are several flaws in your setup: "didn't
tune", "running in a VM", "benchmarked on a mac mini", ...if you
know it's
a flawed setup I'd rather not publish figures, especially not suggest to
make decisions based on such results.
At this level of design need to focus on getting the architecture right; it
should be self-speaking that your proposal of actually using intelligent
routing in some way should be better than not using it. Once we'll have an
agreement on a sound architecture, then we'll be able to make the
implementation efficient.
Thanks,
Sanne
On 30 May 2017 at 13:43, Sebastian Laskawiec <slaskawi(a)redhat.com> wrote:
Hey guys!
Over past few weeks I've been working on accessing Infinispan cluster
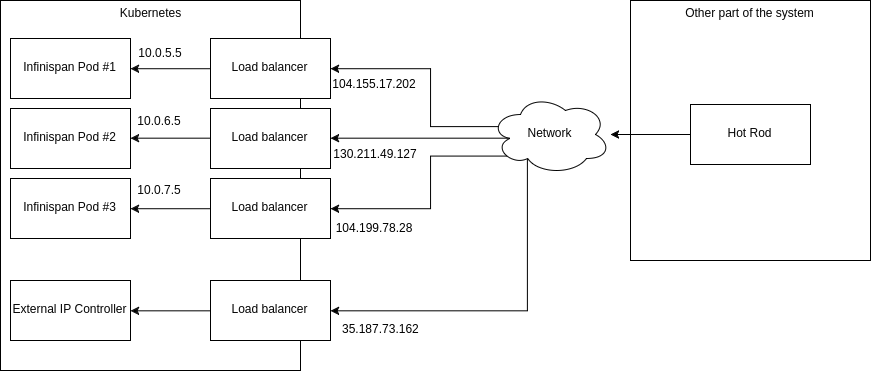
deployed inside Kubernetes from the outside world. The POC diagram looks
like the following:
[image: pasted1]
As a reminder, the easiest (though not the most effective) way to do it is
to expose a load balancer Service (or a Node Port Service) and access it
using a client with basic intelligence (so that it doesn't try to update
server list based on topology information). As you might expect, this won't
give you much performance but at least you could access the cluster.
Another approach is to use TLS/SNI but again, the performance would be even
worse.
During the research I tried to answer this problem and created "External
IP Controller" [1] (and corresponding Pull Request for mapping
internal/external addresses [2]). The main idea is to create a controller
deployed inside Kubernetes which will create (and destroy if not needed) a
load balancer per Infinispan Pod. Additionally the controller exposes
mapping between internal and external addresses which allows the client to
properly update server list as well as consistent hash information. A full
working example is located here [3].
The biggest question is whether it's worth it? The short answer is yes.
Here are some benchmark results of performing 10k puts and 10k puts&gets
(please take them with a big grain of salt, I didn't optimize any server
settings):
- Benchmark app deployed inside Kuberenetes and using internal
addresses (baseline):
- 10k puts: 674.244 ± 16.654
- 10k puts&gets: 1288.437 ± 136.207
- Benchamrking app deployed in a VM outside of Kubernetes with basic
intelligence:
- *10k puts: 1465.567 ± 176.349*
- *10k puts&gets: 2684.984 ± 114.993*
- Benchamrking app deployed in a VM outside of Kubernetes with address
mapping and topology aware hashing:
- *10k puts: 1052.891 ± 31.218*
- *10k puts&gets: 2465.586 ± 85.034*
Note that benchmarking Infinispan from a VM might be very misleading since
it depends on data center configuration. Benchmarks above definitely
contain some delay between Google Compute Engine VM and a Kubernetes
cluster deployed in Google Container Engine. How big is the delay? Hard to
tell. What counts is the difference between client using basic intelligence
and topology aware intelligence. And as you can see it's not that small.
So the bottom line - if you can, deploy your application along with
Infinispan cluster inside Kubernetes. That's the fastest configuration
since only iptables are involved. Otherwise use a load balancer per pod
with External IP Controller. If you don't care about performance, just use
basic client intelligence and expose everything using single load balancer.
Thanks,
Sebastian
[1] https://github.com/slaskawi/external-ip-proxy
[2] https://github.com/infinispan/infinispan/pull/5164
[3] https://github.com/slaskawi/external-ip-proxy/tree/master/benchmark
_______________________________________________
infinispan-dev mailing list
infinispan-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/infinispan-dev
{kind=link}