
[JBoss Cache] Document updated/added: "Parent POMs in JBoss Cache"
by Manik Surtani
User development,
The document "Parent POMs in JBoss Cache", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-13392#cf
Document:
--------------------------------------------------------------
Several JBoss Cache projects depend on parent POMs. The POM hierarchy is explained here. For all of the artifacts referred, the common group ID is *org.jboss.cache*
h1. The different support artifacts in the group
h3. 1. Artifact ID *jbosscache-support*
This is the common parent for all other artifacts in the group.
h3. 2. Artifact ID jbosscache-common-parent
This is what all real project POMs will use as a parent, and has details such as Test NG settings
h3. 3. Artifact ID jbosscache-doc-xslt-support
Additional support for generating docbook documentation
*Support artifacts in Subversion*
These support artifacts are in Subversion, and can be accessed on this URL for non-committers:
http://anonsvn.jboss.org/repos/jbosscache/support/
Or this one for committers:
https://svn.jboss.org/repos/jbosscache/support/
h1. Releasing support artifacts
*NOTE:* Project POMs should only use +*released*+ support artifacts as parents. I.e., +*never, ever*+ use a -SNAPSHOT version of a parent artifact (unless publishing a -SNAPSHOT project artifact).
h3. Release process
1. Check out the support trunk
2. Make changes you need to the pom.xml, +except+ release version number changes
3. Commit your changes to trunk
4. Create a tag off trunk for your new release
5. Check out the new release
6. Update version in pom.xml, common/pom.xml and xslt/pom.xml to a valid release version (E.g., 1.6.BETA1, 1.6.GA, etc) in the release tag you just checked out
6.1. Tip: Using a search-and-replace is strongly recommended. There may be more than 1 place in each file where the version may need to be updated.
8. Check these back in
9. Run $ mvn release
9.1. For this to work, you need to have the JBoss Maven2 repository checked out locally
9.2. Have your ~/.m2/settings.xml properly configured to point to your local Maven2 repo checkout
11. Commit changes in your JBoss Maven2 repo checkout so that the new support artifacts are published
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "JBoss Cache in JBoss AS"
by Manik Surtani
User development,
The document "JBoss Cache in JBoss AS", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-12922#cf
Document:
--------------------------------------------------------------
The purpose of this page is to detail how JBoss Cache is used in JBoss AS.
h1. Cache Manager
h1. HTTP Session Replication
h3. Default configuration
h1. EJB3 Session Replication
Integration code is in svn https://svn.jboss.org/repos/jbossas/projects/ejb3/trunk/core/ in the org.jboss.ejb3.cache.tree package.
Testsuite is https://svn.jboss.org/repos/jbossas/projects/ejb3/trunk/testsuite via the clustered-tests target. The actual test code is in the org.jboss.ejb3.test.clusteredsession package.
A https://www.jboss.org/community/docs/DOC-9565 is in the works which will better define the SPI for the jbc integration.
h5. Basic characteristics:
Session-type use case. Sessions are only meant to be accessed on one node at a time, with that node remaining sticky. Replicating data via JBC is solely to provide HA in case of loss/shutdown of the owning node or some failure in session stickiness. Session stickiness makes this a good candidate for buddy replication.
h5. JBC features used:
* Passivation
* FileCacheLoader (default; users can configure their choice, but FCL is the logical choice for most environments)
* Eviction
** Programmatic registration of eviction regions
** Custom eviction algorithm based on LRUAlgorithm
** JBC-based eviction will be removed in future in favor of direct control of eviction by the integration code. Calls to evict() will still be used.
* Partial state transfer. When a bean is deployed, region associated with bean type is activated and state transferred.
* Region based marshalling.
* BuddyReplication (disabled by default)
* REPL_SYNC or REPL_ASYNC, with async as the default
* No TransactionManager. In the future BatchModeTransactionManager will be used.
* Cache accessed via CacheManager.
h5. Storage structure inside JBC
/sfsb
+++ /uniquenameofdeploymentandbean
++++++ /bucket [0-99]
+++++++++ /sessionid
Session is stored as a single K/V pair, key is string "bean", value is the StatefulBeanContext
TODO: convert the key to an enum.
The region for region-based-marshalling and partial state transfer is /sfsb/uniquenameofdeploymentandbean.
The "bucket [0-99] Fqn level above is a workaround to a FileCacheLoader issue wherein some filesystems limit the max number of child directories under /sfsb/uniquenameofdeploymentandbean to ~32K. The addition of 100 bucket nodes in the tree allows passivation of up to 3.2 million beans.
h3. Default configuration
See the sfsb-cache config in the https://svn.jboss.org/repos/jbossas/trunk/cluster/src/resources/jboss-cac....
h1. Entity Caching (Hibernate)
Integration Code is in svn https://svn.jboss.org/repos/hibernate/core/trunk/cache-jbosscache2/
Testsuite is contained in the same project as the main code.
Extensive documentation is available http://galder.zamarreno.com/wp-content/uploads/2008/09/hibernate-jbosscac...
For now, I (Brian) am not going to comment much on this as the docs are good and the code is clear; learn from those while I focus on the others. :-) I'll come back to this later.)
h3. Default configuration
h1. HA-JNDI
h3. Default configuration
h1. AS Wishlist
This is on a http://community.jboss.org/docs/DOC-13413
h1. Testing JBoss Cache with JBoss AS
A http://community.jboss.org/docs/DOC-12851 was created detailing how this can be done, specific to JBoss AS 5.
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "JBossCacheDevelopment"
by Manik Surtani
User development,
The document "JBossCacheDevelopment", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10259#cf
Document:
--------------------------------------------------------------
h2. Developing with JBoss Cache
This page is intended as a developer's guide to the JBoss Cache source tree, and in addition to information on the code repositories and tags and branches, also contains details on how to set up and use your IDE's debugger with JBoss Cache.
h2. Development resources
h3. Mailing lists
JBoss Cache developer's mailing list: https://lists.jboss.org/mailman/listinfo/jbosscache-dev
JBoss Cache Subversion commits list: https://lists.jboss.org/mailman/listinfo/jbosscache-commits
h3. Discussion forums
JBoss Cache user forum: http://jboss.org/index.html?module=bb&op=viewforum&f=157
JBoss Cache design forum: http://jboss.org/index.html?module=bb&op=viewforum&f=207
h3. IRC
jbosscache on irc.freenode.net
h2. Version control information
h3. Subversion (2.1.0 and beyond)
h4. Access
* Committer access - https://svn.jboss.org/repos/jbosscache
* Anonymous access - http://anonsvn.jboss.org/repos/jbosscache
* FishEye access - http://fisheye.jboss.org/browse/JBossCache
* ViewVC access - http://viewvc.jboss.org/cgi-bin/viewvc.cgi/jbosscache
Please read http://community.jboss.org/docs/DOC-11991 for more information on connecting to the JBoss.ORG repositories.
Tags and branches have been migrated across from CVS, and the new directory structure is shown below.
h4. Core cache
/jbosscache/core - +core cache+
/jbosscache/core/branches - +branches for core cache+
/jbosscache/core/support-branches - +branches for core cache, for Red Hat internal support engineers+
/jbosscache/core/tags - +tags for core cache+
/jbosscache/core/trunk - +HEAD for core cache+
/jbosscache/core/trunk/src/main/java
/jbosscache/core/trunk/src/test/java
/jbosscache/core/trunk/src/test-perf/java
/jbosscache/core/trunk/src/test-stress/java
/jbosscache/core/trunk/src/main/docbook
h4. Pojo cache
/jbosscache/pojo - +pojo cache+
/jbosscache/pojo/branches - +branches for pojo cache+
/jbosscache/pojo/support-branches - +branches for pojo cache, for Red Hat internal support engineers+
/jbosscache/pojo/tags - +tags for pojo cache+
/jbosscache/pojo/trunk - +HEAD for pojo cache+
/jbosscache/pojo/trunk/src/main/java
/jbosscache/pojo/trunk/src/test/java
/jbosscache/pojo/trunk/src/test-perf/java
/jbosscache/pojo/trunk/src/test-stress/java
/jbosscache/pojo/trunk/src/main/docbook
h4. Branches and tags
Tags are simply named after the version, using a point notation (see http://docs.jboss.org/process-guide/en/html/release-procedure.html). E.g., *2.1.0.ALPHA1* or *2.2.0.GA*
Branches are named after the versions that would be tagged off the branch, using a *X* in place of the variable version.
E.g., a branch off which *2.0.0.GA*, *2.0.0.SP1*, *2.0.0.SP2*, etc. but +not+ *2.0.1.GA* would come off would be called *2.0.0.X*.
E.g., a branch off which *2.0.0.GA*, *2.0.0.SP1*, *2.0.1.GA*, etc. but +not+ *2.1.0.GA* would come off would be called *2.0.X*.
E.g., a branch off which *2.0.0.GA*, *2.0.0.SP1*, *2.0.1.GA*, *2.1.0.GA*, etc. but +not+ *3.0.0.GA* would come off would be called *2.X*.
See *1.4.X* and *1.3.X* as live examples of this.
h4. Legacy tags and branches
Old tags and branches have been imported from CVS, and have been renamed to ensure consistency. Note that all old tags and branches reside under the *core* module.
E.g., the old *Branch_JBossCache_1_4_0* is now https://svn.jboss.org/repos/jbosscache/core/branches/1.4.X
h4. Branches for Red Hat support engineers
Occasionally Red Hat support engineers may create branches on released versions. These will live separate from project branches, but follow a similar naming pattern. E.g.,
https://svn.jboss.org/repos/jbosscache/core/support-branches/1.4.1.SP3_CP01
h4. Snapshots
Snapshots will be released to the JBoss Maven2 snapshot repository. Note that snapshots do not have a release qualifier (*.GA*, etc.) but instead have the *-SNAPSHOT* qualifier. E.g., *2.1.0-SNAPSHOT*
h4. Maven for builds
We have moved to Maven2 to handle building of JBoss Cache and Pojo Cache. pom.xml will exist in /jbosscache/core/trunk/ and /jbosscache/pojo/trunk/ to manage library dependencies and documentation. See http://fisheye.jboss.com/browse/~raw,r=4259/JBossCache/core/trunk/README-... in the source tree for usage information.
h3. older CVS repository (up to and including 2.0.0.GA)
Older versions of JBoss Cache used JBoss.org's CVS repository.
*NOTE that this CVS repository is now FROZEN and READ-ONLY. All active work should happen in the Subversion repository (see above)*
*Note* that the CVS module name is *JBossCache* (case sensitive)
In the examples below, XXX is the tag or branch name. Beginning with 1.2.4 a source-only distribution is also available from the download site. For 1.2.2 and earlier, the source for JBossCache was integrated with the JBoss AS code base, so you need to check out JBoss AS code.
h4. Committer CVS Access
You would need to make sure your SSH keys are set up on the CVS server. Your first step should be to http://docs.jboss.org/process-guide/en/html/cvsaccess.html.
export CVS_RSH=SSH
cvs -d:ext:USERNAME@cvs.forge.jboss.com:/cvsroot/jboss co -r XXX JBossCache
h3. Anonymous CVS Access
cvs -d:pserver:mailto:anonymous@anoncvs.forge.jboss.com:/cvsroot/jboss co -r XXX JBossCache
h4. Web based access
Web-based access to JBoss Cache CVS repository is either via:
* http://fisheye.jboss.com/browse/JBoss/JBossCache
* http://viewvc.jboss.org/cgi-bin/viewvc.cgi/jboss/JBossCache.
h4. CVS tags for released versions
|| Version || Label or branch name in CVS || Location in SVN || ||
| 2.0.0.GA +"Habanero"+ | JBossCache_2_0_0_GA | http://anonsvn.jboss.org/repos/jbosscache/core/tags/2.0.0.GA |
| 1.4.1.SP4 +"Cayenne"+ | JBossCache_1_4_1_SP4 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.1.SP4 | |
| 1.4.1.SP3 +"Cayenne"+ | JBossCache_1_4_1_SP3 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.1.SP3 | |
| 1.4.1.SP2 +"Cayenne"+ | JBossCache_1_4_1_SP2 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.1.SP2 | |
| 1.4.1.SP1 +"Cayenne"+ | JBossCache_1_4_1_SP1 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.1.SP1 | |
| 1.4.1.GA +"Cayenne"+ | JBossCache_1_4_1_GA | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.1.GA | |
| 1.4.0.SP1 +"Jalapeno"+ | JBossCache_1_4_0_SP1 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.0.SP1 | |
| 1.4.0.GA +"Jalapeno"+ | JBossCache_1_4_0_GA | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.4.0.GA | |
| 1.3.0.SP4 +"Wasabi"+ | JBossCache_1_3_0_SP4 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.3.0.SP4 | |
| 1.3.0.SP3 +"Wasabi"+ | JBossCache_1_3_0_SP3 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.3.0.SP3 | |
| 1.3.0.SP2 +"Wasabi"+ | JBossCache_1_3_0_SP2 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.3.0.SP2 | |
| 1.3.0.SP1 +"Wasabi"+ | JBossCache_1_3_0_SP1 | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.3.0.SP1 | |
| 1.3.0.GA +"Wasabi"+ | JBossCache_1_3_0_GA | http://anonsvn.jboss.org/repos/jbosscache/core/tags/1.3.0.GA | |
h4. CVS branches for development streams
|| Version || Branch name || Location in SVN || Description || ||
| 2.0.x branch | +branch not created as yet+ | Ongoing development on the 2.0.x stream | | |
| 1.4.x branch | Branch_JBossCache_1_4_0 | http://anonsvn.jboss.org/repos/jbosscache/core/branches/1.4.X | Ongoing development on the 1.4.x stream | |
| 1.3.x branch | Branch_JBossCache_1_3_0 | http://anonsvn.jboss.org/repos/jbosscache/core/branches/1.3.X | Unused (except for backports and releasing service packs) on the 1.3.x stream. | |
h3. Using Maven
Maven2 is the preferred approach when developing software with JBoss Cache. Point your project's pom.xml to http://repository.jboss.org/maven2 to get the latest JBoss Cache releases. From 2.1.0, JBoss Cache uses the groupId org.jboss.cache and the artifactId jbosscache-core or jbosscache-pojo.
h4. Snapshots
Point your project's pom.xml to http://shapshots.jboss.org/maven2 to be able to use snapshots of JBoss Cache.
h5. Parent POMs
Seehttp://community.jboss.org/docs/DOC-13392 for a discussion on parent POMs and how to release them.
h4. Classpaths with IDEs
Use the mvn idea:idea or mvn eclipse:eclipse commands to build project files for IDEA or Eclipse. This sets up your project dependencies, etc. as per the maven2 pom.
h2. IDEs and debugging
h3. IntelliJ IDEA
1. Set up the project as you would in IntelliJ, by checking out the source tree from CVS.
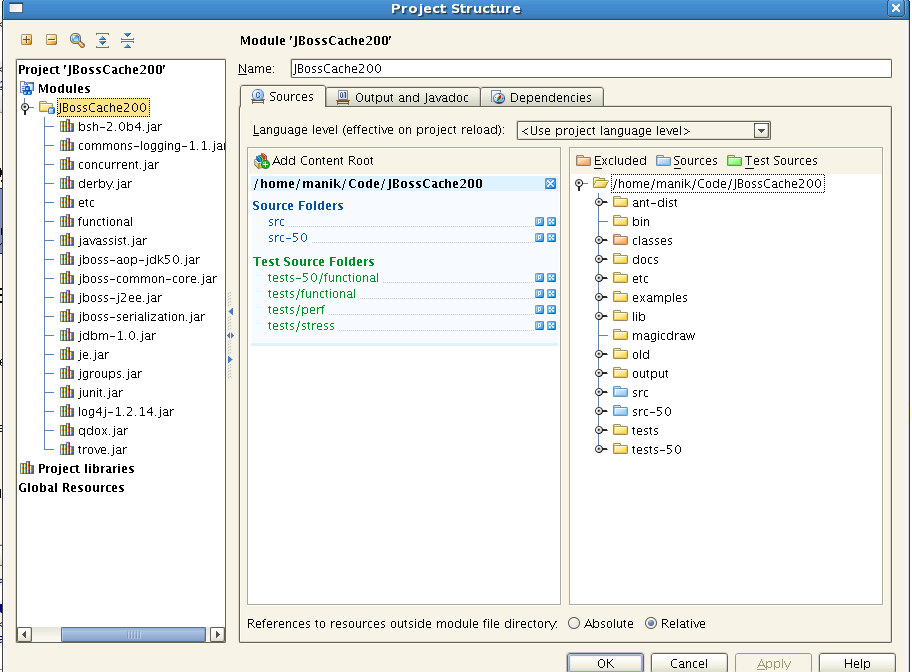
2. Make sure your source directories include src and src-50, and your test-source directories include tests/functional, tests/stress, tests/perf and tests-50/functional
http://community.jboss.org/servlet/JiveServlet/download/10259-50-4665/ide...
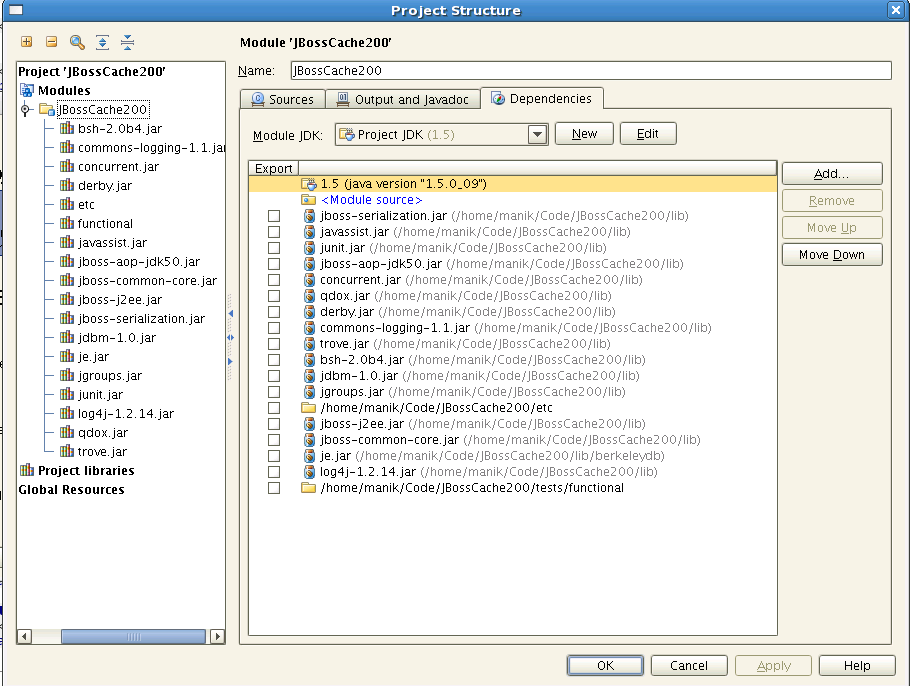
3. Make sure your library dependencies include all the jars in lib as well as the etc/ directory and the tests/functional directory (some tests have additional resources there that are looked up using a context class loader)
http://community.jboss.org/servlet/JiveServlet/download/10259-50-4662/ide...
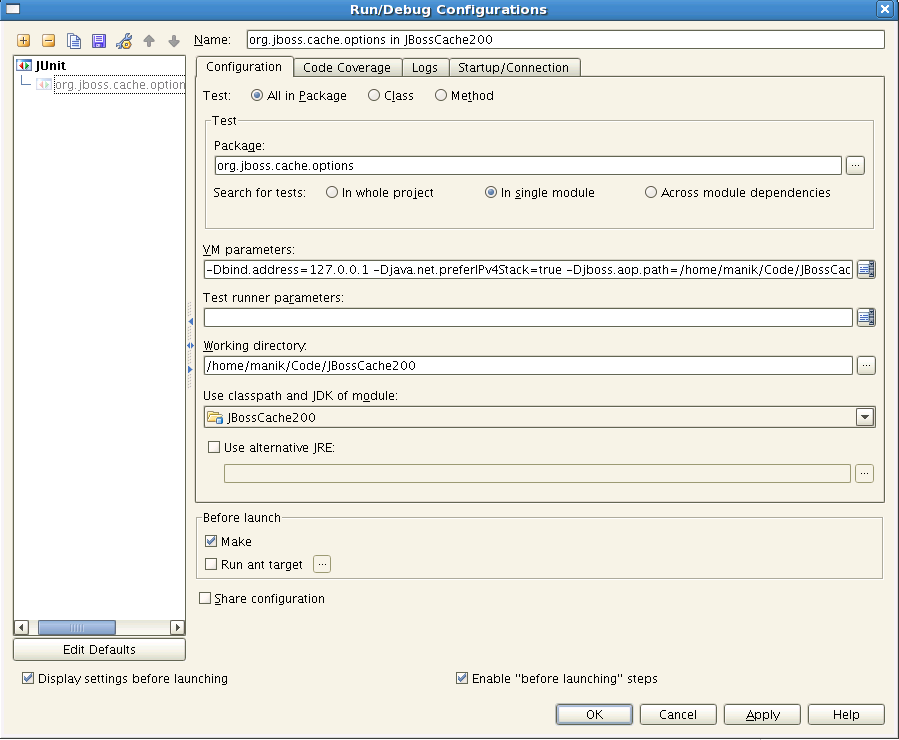
4. Running JUnit tests. Certain Linux kernels default to IPv6 which screws up a few things with some JDK implementations. Make sure you force IPv4 by passing in a few VM parameters to IntelliJ's JUnit plugin. The parameters you'd want are -Dbind.address=127.0.0.1 -Djava.net.preferIPv4Stack=true
http://community.jboss.org/servlet/JiveServlet/download/10259-50-4664/ide...
5. If you wish to test PojoCache tests and want load-time aspectisation of objects, add the following VM params as well. For JBoss Cache release 1.4.x (using JDK5):
-javaagent:$\lib-50\jboss-aop-jdk50.jar -Djboss.aop.path=$\etc\jboss-aop.xml -Dlog4j.configuration=file:$\etc\log4j.xml
For release 2.x (only supported in JDK5):
-javaagent:$\lib\jboss-aop-jdk50.jar -Djboss.aop.path=$\src-50\resources\pojocache-aop.xml -Dlog4j.configuration=file:$\etc\log4j.xml
h2. Code style
h3. IntelliJ IDEA
Download /settings.jar and import it into IDEA using *File | Import Settings*. This will only reset the code formatting, and leave everything else - including inspections, JDKs, etc - untouched. Thanks to Mircea Markus for this tip.
h3. Eclipse
Download and unzip /eclipse-settings.xml.zip, and import into Eclipse using *Preferences | Java | Code Style | Formatter | Import*.
h2. Continuous Integration
JBoss Cache uses Hudson for continuous integration. See
http://hudson.jboss.org/hudson/job/jboss-cache-1.4.X-jdk1.5/
h3. Trunk
http://dev45.qa.atl.jboss.com:8585/hudson/job/jboss-cache-core-jdk1.5/
http://dev45.qa.atl.jboss.com:8585/hudson/job/jboss-cache-core-jdk1.6/
http://dev45.qa.atl.jboss.com:8585/hudson/job/jboss-cache-pojo-jdk1.5/
http://dev45.qa.atl.jboss.com:8585/hudson/job/jboss-cache-pojo-jdk1.6/
h3. Branch 1.4.x
http://hudson.jboss.org/hudson/job/jboss-cache-1.4.X-jdk1.5
h2. Docs
h3. Prerequesites
You need the docbook-support module from the JBoss AS subversion repository (NOT the old, outdated, frozen CVS repo)
svn co https://svn.jboss.org/repos/jbossas/trunk/docbook-support
This should be checked out in the same directory you checked out the JBossCache CVS module. E.g.:,
FatBastard:~/Code manik$ pwd
/Users/manik/Code
FatBastard:~/Code manik$ ls -l
total 0
drwxr-xr-x 29 manik manik 986 Mar 2 17:10 JBossCache
drwxr-xr-x 9 manik manik 306 Feb 28 12:09 docbook-support
h3. Building docs
JBoss Cache docs can be built from their docbook sources using:
FatBastard:~/Code/JBossCache manik$ ./build.sh docs
from the JBoss Cache root directory.
h3. Output
HTML and PDF output will be in the docs/BOOK_TITLE/build directory.
h2. Unit tests
In order be able to execute the test suite before committing a modification, JBoss Cache runs its test suite in parallel. This requires following some rules and best practices for writing test as well. Please read this for a detailed description: https://www.jboss.org/community/docs/DOC-13315
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "JBoss Cache - Searchable Edition - Designs"
by Manik Surtani
User development,
The document "JBoss Cache - Searchable Edition - Designs", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-13454#cf
Document:
--------------------------------------------------------------
h1. JBoss Cache Searchable Edition (JBCS) Designs
h3. Historic
The current (v1.0) release of JBCS uses a listener approach.
1. The SearchableCacheFactory takes a running Cache, and creates a delegate
2. This delegate implements SearchableCache, which is a sub-interface of Cache
3. Most calls delegated to the underlying Cache, except the query related methods
4. A listener is created and attached to the cache
4.1. Used to listen for cache modifying events which originate both locally and remotely
4.2. Updates indexes based on events
h3. New
The plan is from v1.1 onwards, to drop the listener based approach as this can lead to complications with Hibernate Search (the interface to Lucene for indexing and searching).
Instead, we should create an interceptor and register this interceptor with the cache.
1. IndexingInterceptor should extend http://www.jboss.org/file-access/default/members/jbosscache/freezone/docs....
2. Methods we are interested in overriding are any visitXXXCommand() that change the cache (such as CommandInterceptor.visitPutKeyValueCommand()).
3. On interception, we should first check if there is a transaction in progress (http://www.jboss.org/file-access/default/members/jbosscache/freezone/docs... will tell you this)
4. If there is no transaction in progress, update indexes.
5. We should also override visitPrepareCommand() (and visitOptimisticPrepareCommand() as well, for backward compatibility). Here, we should make a note of all modifications made to the cache
6. If this is a one-phase prepare command, update indexes immediately. Otherwise, store the changes somewhere for now
7. We should also override visitCommitCommand(). Here, we should update indexes for all modifications stored in 6.
8. For visitRollbackCommand(), we should not do anything except free up resources by removing anything we store in 6 pertaining to this transaction.
That's it. :-)
The IndexingInterceptor should be registered with the cache by using Cache.addInterceptor(). It would be a good idea to put this just before the CallInterceptor, which is the last interceptor in the chain.
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "JBoss Cache Non-Blocking State Transfer"
by Manik Surtani
User development,
The document "JBoss Cache Non-Blocking State Transfer", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10275#cf
Document:
--------------------------------------------------------------
h2. Non-Blocking State Transfe
* Please use http://www.jboss.com/index.html?module=bb&op=viewtopic&p=4112547#4112547 to discuss ideas/enhancements and provide comments and feedback.
* JIRA: http://jira.jboss.org/jira/browse/JBCACHE-1236
h3. What we have now
Right now, JBoss Cache uses http://www.jgroups.org/javagroupsnew/docs/manual/html/protlist.html#d0e3916 to make sure any in-flight messages are received and prevent any more messages from being broadcast so that a stable state can be transferred.
While this provides a high level of data consistency, it is a brute force method that will not scale when there is a large amount of state to be transferred, since it effectively +freezes+ the cluster during the state transfer period.
h3. An alternative - *Non-Blocking State Transfer*
The alternative discussed here attempts to:
* provide state to a new node joining a cluster or a partition quickly and effectively
* provide consistency guarantees
* not hold up the cluster at all so the rest of the cluster can proceed as usual even while state is being transferred
This new approach would need MVCC locking to be implemented first since non-blocking reads is necessary. It also assumes idempotency of cache updates provided they are applied in the correct order.
h4. Assumptions
1. Non-blocking reads are available (MVCC)
2. Modifications are idempotent
3. Streaming state transfer is present in the JGroups stack (To provide an open stream between the 2 instances)
h4. Approach
Assume a 3-instance cluster, containing instances +A+, +B+, and +C+. Instance +D+ joins the cluster.
+All nodes track pending prepares since startup. This additional overhead means that whenever a transaction enters its prepare phase it is recorded in a concurrent collection and when the transaction commits or rolls back it is removed from this concurrent collection.
+
1. D asks A for state, and starts responding to all 1 and 2 phase prepares/commits positively, but doesn't log any transactions.
2. A starts logging all transactions and non-transactional writes
3. A starts sending transient and persistent state to D. This does not block on anything.
4. D applies state.
5. A starts sending the transaction log to D
6. A continues to write the transaction log until the log is either empty, or progress is no longer being made.
7. Lack of progress occurs when the log size is repeatedly not reduced after writing
8. A waits for pending incoming and outgoing requests to complete and suspends new ones
9. A sends a marker indicating the need to stop all modifications on A and D.
10. D receives the marker and unicasts a StateTransferControlCommand to A.
10.1. On receipt of this command, A closes a latch that prevents its RPC dispatcher from sending or receiving any commands.
10.2. D too closes a similar latch on its RPC dispatcher
10.3. Note that this latch does NOT block StateTransferControlCommands
12. These latches guarantee that other transactions originating at B or C will block in their communications to A or D until the latches are released.
13. D retrieves and applies the final transaction log, which should no longer be growing
14. D retrieves and applies all non-committed prepares
15. A sends a marker indicating transmission is complete
16. A resumes processing of incoming / outgoing requests
17. D unicasts another StateTransferControlCommand to A.
17.1. This releases latches on A
17.2. D also releases similar latches on D
19. D sets it's cache status to *STARTED*.
h4. Transaction Log
This is a data structure that will contain an ordered list of:
public static class LogEntry
{
private final GlobalTransaction transaction;
private final List<WriteCommand> modifications;
}
The receiving node will apply this log by starting transactions using the given gtx, applying the modifications, and commit the transaction.
h4. Capturing the transaction log
It is imperative that the transaction log is captured in the order in which locks are acquired/transactions completed. As such, in the Synchronization on the state sender (A), the transaction is added in afterCompletion. In addition all non-committed prepares must be kept in a table indexed by gtx. Once the gtx has completed, it is removed from the table.
h3. Idempotency
Idempotency is a requirement since it is feasible that state read may or may not include a given update. As such, all transactions recorded during the state generation process will have to be re-applied. Still, this isn't a problem - even with node deletions, creation or moving - provided the transaction log is replayed in +exactly+ the same order as it was applied on the node generating state.
h4. Benefits
* Cluster continues operations, and is not held up
h4. Drawbacks
* D may take longer to join as it would need to replay a transaction log after acquiring state
h4. Assumptions/Requirements
* MVCC is in place to provide efficient non-blocking READ on the state provider
* Cache updates are idempotent
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "Replication Across Data Centres"
by Manik Surtani
User development,
The document "Replication Across Data Centres", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10249#cf
Document:
--------------------------------------------------------------
This page contains some brainstorming around being able to deploy JBoss Cache to replicate state across multiple data centres, https://jira.jboss.org/jira/browse/JBCACHE-816
Weblogic contains similar functionality limited to the HTTP session replication use case which you can find in http://community.jboss.org/docs/DOC-13202.
*TODO:* Diagrams to help understand different scenarios.
h1. Update - 12/03/09
Cache listener based approach is not the most adequate due to the following reasons. Instead, an interceptor should be developed:
- marshalling -> interceptor could take the command itself and forward that, versus listener that needs to convert command into listener event and we then need to convert it back to a command -> think performance!!!
- potential sync replication future! if listener, we can't make cross cluster invocations synched because we'll get callbacks either before or after local sync repl has finished. We're not part of synchronous invocation. If we're an interceptor, we're part of the synch invocation and could potentially implement 2pc accross clusters!
- ping pong effect! no need for wacky disabling of event notifications that would affect other components such as TC L1 cache. Just pass up the stack.
General advice:
- Do not create your own JGroups channel, get it from RPCManager.
h1. New approach altogether - Checkpoint Streaming
- Let's say there's a cluster of 3 nodes: A, B and C and contents are: A=1,2 B=7, C=10,12
- Now, Y joins in another cluster but it's configured for inter cluster replication.
- When Y joins, A instructs B and C to open an start streaming channel and start with a full backup. B&C do not respond immediately, they wait until it's their time so that they don't all stream at the same time (B does it after 1 min, C after 2).
- A streams the contents over of B and C when it receives them over to Y. A takes its contents and streams them over to Y as well when it's his turn.
- What's the content of the full backup? An image of each node that contains keys for which the node is primary (data partitioning).
- Y receives [1,2,7,10,12] contents in different moments in time and spreads them based on its hash algorithm and tolopology.
- Next time around, A=1,2,3 B=7,8 C=10,12,11
- Periodically, B & C send diffs to A, which forwards to Y. A forwards diffs to Y as well.
- These diffs could be big, so store them in file system. Diffs stored in disk in B, C and A so that they don't take up extra memory.
- These diffs or backups are streamed over to Y, no serialization or accumulation!
- Now, Z, in a new cluster, joins the inter cluster bridge.
- It's now time for a full backup, so A asks B&C to schedule a full backup and stream it throw A and sends it to Z.
- A crashes and B takes over - keys rebalanced -> a full backup needs to be forced next time around. -> C needs to open stream with B.
- Y gets uddated with 25 - ideally would only send whatever has been updated cos it's not coordinator - only diffs. Full backups are only send by the inter cluster bridge coordinator!! We don't want Y sending full backups.
- What if diffs from Y were sent at the same time B did a full backup? negotiate...
- How to deal with removes? Let is expire in other clusters? That'd be dangerous
- If 10 removed from C and B fails, a full backup has to be sent, how do we deal with 10 which is present in Y?
- Prefix keys with location (i.e cluster = NY) + version (1,2,3...etc)? Y knows that 10 is not in FB and it originalted in NY.
- Would be compat diffs? No, Difficult!
- Full backup contains keys for which you're primary only too (same as diffs)
h1. ---
h3. Current Solution - Primary/Backup Clusters
This solution aims to:
* Facilitate recovery of complete primary/production cluster failures by keeping standby backup clusters ready to take over if necessary.
This solution assumes that:
* Communication between primary and backup cluster is asynchronous; It's not about 100% data reliability.
* While the primary cluster is up, all clients are directed there and hence, communication between primary and backup cluster(s) is unidirectional, from primary to backup.
* Switching over clients from primary to backup is either done via external intervention or via an intelligent global load balancer that is able to detect when the primary cluster has gone down.
This solution consists of:
* A new component based on a JBoss Cache Listener that is running in at least one cluster node within the primary cluster and one cluster node in each of the existing backup clusters. The number of nodes where the component would run would be configurable to be able to cope with cluster node failures. The 2nd in line would maintain the last N updates and replay them when it takes over.
* Component in primary and backup are linked by a JGroups communication channel suited for long distances.
* Component in primary cluster maintains a queue of modifications lists (if transactional commit/prepares) or puts/removes (non-transactional) that are sent to backup cluster(s) components asynchronously.
* Component in backup cluster(s) spreads data evenly accross backup nodes using application consistent hashing mechanism. For example: In the case of HTTP sessions, a specific session data needs always to be in the same backup node. *Note*: If all backup nodes contained all state, it'd be easier+simpler for state transfer purpouses (proxy on primary can request state, or non buddy state from others in primary, for backup startup), and after a cluster failover there wouldn't need to a calculation on the load balancer side of who's got which session cos all of them had it.
* If cache uses buddy replication:
** Component in primary cluster needs to be active in at least one node in each buddy group listening for updates and pushing them to node queueing updates. If could be that the component is active in all nodes.
Caveats:
* How does a component node whether it's running in primary or backup cluster? Initially static and then modified at runtime in case of cluster failure?
* In buddy replication, how to avoid multiple identical puts being queued? Only the original one is needed. Does the component only live in one of the nodes of each buddy group? From a cache listener perspective, is there a difference between a cache put and a put from a buddy replication?
Discarded Alternatives:
* Rather than the component maintaining a queue of modifications, whether transactional or just put/removes, an alternative would be for such component to retrieve a snapshot periodically and pass it on to the other cluster. Such snapshots would have to make sure that they're transactionally consistent.
** Advantages here are
*** Component becomes stateless.
** Disadvantage here are:
*** If you're getting snapshot it from coordinator (non buddy scenario) or ask individual nodes to return their non buddy state, this could affect normal functioning of these nodes, potentially overloading them. Maybe snapshots could be retrieved when node(s) are not busy, with some kind of CPU check/threshold?
*** In the backup cache state would need to be cleared and reapplied, more work.
*** Two continuous snapshots would contain a lot of redundant data.
h3. Other Solutions - Cluster Load Balancing
This solution aims to:
* Allow inter cluster replication to recover from complete cluster failure while spreading load between separated clusters or data centres. For example: clients could be directed to the cluster with less traffic or closest to the client.
This solution assumes that:
* There're no primary/backup clusters, all clusters are active.
* Clients could be directed to a cluster or the other based on cluster load or proximity.
* Communication between clusters is still asynchronous.
* Sticky sessions are in use, with failover attempting to find a node within the local cluster, before doing a failover to a different cluster.
This solution consists of:
* Needs further thought.
Caveats:
* How to avoid data going backwards and forwards between the different clusters taking in account that all clusters can replicate to each other? Avoid ping-pong effect. Periodic snaphot transfer could help here.
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "JBoss Cache - Partitioning"
by Manik Surtani
User development,
The document "JBoss Cache - Partitioning", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-13734#cf
Document:
--------------------------------------------------------------
> *NOTE* that this is defunct and will +not+ be implemented. Refer to http://community.jboss.org/docs/DOC-10278
h2. Partitioning - Buddy Replication on Steroids
Partitioning is the concept of breaking up state in the cache and spreading it around a cluster, on sufficient nodes so that there will always be a backup somewhere, and with intelligent enough a data gravitation algorithm such that the data is always efficiently available on any given node.
Another way to look at it is buddy replication without the need for session affinity. (See JBossCacheBuddyReplicationDesign)
h3. The motivation
Buddy replication effectively solves the scalability issue encountered when dealing with synchronous state replication, but imposes a very restrictive rule that session affinity must be present. While this fits in perfectly with usage where session affinity is available anyway (state replication for HTTP sessions and EJB SFSBs) this is still restrictive on other use cases - such as in data grids where data access patterns are not fixed.
h3. The solution
Involves something very similar to Buddy Replication - with a few changes.
* Still use BuddyGroups to define a replication group
** Except that buddies in a group are treated as Peers, rather than DataOwner and Buddy relationship
*** Let's call this PartitionGroup for disambiguity
** Just like with BR, changes are replicated to the entire PartitionGroup
* Still use data gravitation as a means of querying the cluster and gravitating data back
** Except that when data is gravitated back, rather than removing data from the sender, the receiver joins the PartitionGroup of the sender
* A cache instance can be in several PartitionGroups
* Each cache instance runs a PartitionMaintenanceThread
** The purpose of this thread is to make sure a "distributed eviction' takes place
** Based on hard and soft upper and lower limits, defining how many copies of each data element should exist in the cluster
*** Colocated hosts need to be considered when shrinking partitions. Should not be counted as a "backup".
** Potentially re-use the eviction algorithms in deciding which cache instances should evict state
* Regions would be the granularity of tree nodes moved around
* Metadata - consisting of PartitionGroups, the region they represent, and peers in the group - would exist in a special "Metadata" partition. More in this later.
** Used to prevent unnecessary gravitation attempts for data that may not exist
h4. Initial partition group for a given region of data
http://www.jboss.org/community/servlet/JiveServlet/download/10278-33-4682...
h4. Partition grows
http://www.jboss.org/community/servlet/JiveServlet/download/10278-33-4680...
* Server C attempts to look up node /a/b.
* Looking at the metadata, it knows that this is a defined region and it attempts to join the region.
** This is allowed since this is within the upper and lower limits for the number of peers per partition.
** Which kicks off a partial state transfer event
** Will involve updated metadata being broadcast
h4. Partition shrinks
http://www.jboss.org/community/servlet/JiveServlet/download/10278-33-4681...
* Assuming 3 is outside the configuration's soft limit, after a period of time one server will be selected for removal from the partition
** Configurable algorithms
** Will involve voting and consensus within the partition
** Will involve updated metadata being broadcast
h3. Proxying calls
Instances wouldn't always join partitions when they are involved in a transaction that spans a partition. A partition may be configured such that the call is proxied to a instance which is a member of the partition instead.
The instance proxying the call may later decide, based on a frequency of transactions involving a partition and the way that partition is configured, to stop proxying calls and join the partition instead, based on:
* The partition proxy behaviour (ALWAYS_PROXY, ALWAYS_JOIN, THRESHOLD)
* And a threshold, which, if crossed, the proxying node stops proxying and joins the partition.
** The threshold is encoded as a frequency of transactions per minute.
Selecting an instance to proxy to would be based on a round-robin algorithm, although this could be pluggable.
h4. Evictions
Never proxy evictions.
h3. Cache loading
* When proxying a get, don't *ever* store the results in a cache loader!
* Partition or proxy interceptor should sit before the CacheLoaderInterceptor to prevent unnecessary lookups in the cache loader.
* Make sure state is removed from the cache loader when an instance leaves a partition
** but *not* if the cache loader is shared!!
h3. The "Metadata" Partition
This is a special partition, set up to hold metadata (MD) of all partitions. This MD includes partition region and all members of that partition at any given time. The purpose of MD is to prevent cluster-wide broadcasts to find data and partition membership when a node needs data it doesn't already have locally.
The original design for handling MD was to replicate it to every node in the cluster, and while viable for small clusters with little MD, this can be cumbersome if the cluster is large and/or the partitions defined are very fine-grained (more partitions -> more MD). Replicating MD can impact scalability.
We are now considering a special MD partition which always includes the *coordinator* and have a fixed size. This is so that if a node needs MD, it can look up the MD partition by asking a member of the special partition. Lookups can be load balanced by using a random number between 0 and numMetadataNodes and ask the JGroups View for the corresponding address.
h4. When is Metadata needed?
MD is needed whenever a node requires data that it doesn't have locally. This should be infrequent enough to warrant a remote call to request MD.
MD is only updated when a partition changes membership, which again should be infrequent enough to warrant updating the MD remotely. Depending on the size/membership of the MD partition, this would be more efficient that replicating the changes to MD across the cluster anyway.
h4. Defaults
The defaults for the MD partition would be tuned for small clusters, with MD partition upper hard limit == upper soft limit == lower hard limit == lower soft limit == cluster size, which will result in effectively replicating MD across all nodes.
h4. Metadata Design
Metadata to contain:
* Partition name
* List of partition members
* Join policy (Always join/always proxy/threshold)
* hU, sU, hL, sL
* threshold (encoded as a float; a metric based on frequency of partition accesses after which to join the partition. Needs to take time into account)
MD should not exceed 1k in size.
h4. Updating metadata
* Metadata updates should be done asynchronously, and should be multicast to everyone.
* When new partitions are created or a change in partition "shape" occurs, this is multicast so everyone gets the MD update.
* Nodes proxying to or otherwise involved in the partition in question can update their MD. Others - except the special partition members - would discard.
h4. Caching metadata
* Instances should cache MD for all partitions it is interested in, such as partitions it participates in or proxies to, and listen for MD update multicasts.
* Handle failed proxy requests by purging MD for the partition in question and retrieving MD from the "special" partition.
h3. Alternative to MetaData
Consistent hashing? -- needs research. http://weblogs.java.net/blog/tomwhite/archive/2007/11/consistent_hash.html So far, consistent hashing will not really help.
h3. Data Gravitation
Data gravitation is a concept we introduced when we implemented http://community.jboss.org/docs/DOC-10256. Building on what we have here, we'd need to enhance data gravitation to work with partitions as described here.
*NOTE* This section talks about FLUSH when transferring state. This may not be the final implementation, as hopefully we'd have a better state transfer mechanism in place by the time we implement partitioning. See JBossCacheNewStateTransfer
h4. Performing data gravitation
The current buddy replication implementation does the following when a new buddy is assigned to a buddy group.
* Perform a cluster-wide FLUSH to prevent changes to the cache
* The data owner of the group generates it's state (excluding it's BUDDYBACKUP_ region)
* Performs a state transfer of this state to the new buddy
* The new buddy applies this state to a new, backup sub-root
* The FLUSH block is released and the network resumes.
This would be changed, since partition groups only contain the state of a specific region rather than the entire state of a data owner, plus the concept of buddy subtrees are removed.
* Perform a cluster-wide FLUSH to prevent changes to the cache
* A single member of the partition group is selected as the state provider
* The state provider generates state for the required region
* This is streamed to the new member joining the region
** Applied directly on the recipient, not in a backup subtree
* The FLUSH block is released and the network resumes.
h4. Detecting a "global" cache miss versus a "local" cache miss
As is evident from above, gravitation can be expensive and hence should be minimised. To do this, we rely on region metadata that is replicated across the cluster.
* If a request for tree node N is received by an instance in the cluster,
** Check region metadata to determine which region this resides in
** Check if the current instance is a part of this region
*** If so, the tree node should be available locally
*** If not available locally, create this tree node.
** If the current instance is not a member of the region,
*** Join region
*** Will involve gravitation, as above
*** Create node if necessary
h4. Distributed eviction
As the PartitionManagementThread runs and decides that a partition has too many members (based on hard and soft limits) a voting protocol commences to determine which instances should be forced to leave the partition.
* Partition member that initiates the distributed eviction broadcasts a "DE" message to partition members.
* Each partition member reports a single value representing the 'participation weight' in that partition to the initiator.
* The initiator uses this to select which member or members have the lowest partition, based on the number of members that need to leave the partition group.
** In the event of a tie, the first instance in the tie is selected
* The initiator then broadcasts it's 'decision' on the instance that is elected to leave the partition.
** This will contain a new PartitionGroup and updates region metadata.
** The elected members respond with an acknowledgement, evicts the partition state from memory and leaves the partition.
** The other instances just respond with an acknowledgement.
h4. Participation weight algorithm, based on half-life decay of participation importance
To calculate the degree of participation in a partition, each node maintains:
* a degree of participation (Dp)
* a timestamp of when this was calculated (Dt)
* a list of timestamps when the partition was accessed (At)
* a half-life decay constant which is used to reduce the importance of accesses over time (H)
** E.g., an event that occured H milliseconds ago is deemed half as important as an event that occurs now.
Every time the PartitionManagementThread runs, OR a DE message is received, each instance recalculates it's degree of participation, updates Dp and Dt, and clears Lt. If a DE message was received, Dp is sent back to the initiator of DE.
Dp is calculated using the following algorithm:
* Let Tc be the current time, in millis, of the calculation (System.currentTimeMillis())
* if Dp != 0, re-weight Dp
** Dp = Dp x ( 1 / 2 ^ ((Tc - Dt)/H) )
** Dt = Tc
* Now add the new access events
** Dp = Dp + ( 1 / 2 ^ ((Tc - At)/H) )
* Empty the list of At collected
* This gives is a mechanism of maintaining the participation degree (Dp) without maintaining all access events as this is digested periodically.
* The algorithm above maintains the weightage of accesses, treating more recent accesses as more important than past accesses.
** Older accesses decay in importance exponentially, using the half-life constant passed in
* Includes a function to add the number of accesses as well, since Dp = Dp + f(At)
** so instances that accessed a participation a a significantly larger number of times in the past may still have a higher participation weightage to instances that accessed the partition only once, but very recently.
* H will be configurable, with a sensible default of 8 hours.
h2. Transactions
We should *never* allow transactions to span > 1 partition (for now, at least) since this can lead to ugly deadlocks, especially if proxying is involved.
When proxying calls - even get()&146;s, to maintain Repeatable Read - any transaction context should be propagated and the proxy node should be able to perform commits and potentially broadcast put()s to it's partition.
h2. New servers joining the cluster
We would provide configurable behaviour for new nodes joining the cluster. New nodes would have one of the following "default join" policies:
JoinNone, JoinSpecifiedPartitions, JoinAll, JoinSome. Some of these may take additional "join options".
h4. JoinNone
Simple - the server joins the cluster but does not join any partition (except the metadata partition, if the metadata partition is configured to be on all instances). It is assumed that as requests come to this new node, perhaps via a load balancer, it would join partitions as needed.
h4. JoinSpecifiedPartitions
A configuration option - PartitionsToJoin - would provide a comma-delimited list of region names to join on startup.
h4. JoinAll
Does what it says on the can.
h4. JoinSome
This would take in a further configuration option - PartitionSelectionAlgorithm - which would consist of JoinLargest, JoinSmallest, JoinMostHeavilyUsed, and JoinLeastHeavilyUsed, as well as another option NumberOfPartitionsToJoin - which will define how many partitions to select based on the required PartitionSelectionAlgorithm.
Largest and smallest are calculated based on number of members; usage is calculated based on degree of participation.
h2. Creating and destroying partitions
* Do we need an explicit API for destroying a partition?
* Need to clean up metadata when destroying entire partitions.
* We need to be able to create new partitions programmatically and on the fly.
** Needed for HTTP Session use case
** Creation needs to be optimised for reduced weight and fast response time
h2. Striping
Taking the concept of partitioning further, there is more that can be done if the cache were to be used to store very large data items (for exaple, a DVD - a byte{FOOTNOTE DEF } of 4GiB).
Using RAID-style error correction algorithms, the byte{FOOTNOTE DEF } could be broken up into chunks, the chunks stored in various nodes in the tree, each node defined as a separate partition.
The alternative is to break down the replication granularity of the tree into something smaller than a tree node - which I am not keen on doing as this means implicit knowledge of the relationships between the attributes in a node.
--------------------------------------------------------------
16 years, 2 months
[JBoss Cache] Document updated/added: "JBossCacheServer"
by Manik Surtani
User development,
The document "JBossCacheServer", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10287#cf
Document:
--------------------------------------------------------------
h2. JBossCache-Server
> Interested in what Infinispan is doing in this regard? Take a look at http://community.jboss.org/docs/DOC-14029
This is the design of the server module for JBoss Cache, that bolts on to either a replicated or standalone cache and exposes certain functionality over a TCP socket.
The plan is to provide a number of protocols, the first one, , being a basic JBoss Cache 2.x cache loader compatible one to replace the . Other protocols would involve a http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt and a binary equivalent.
h3. TreeCacheProtocol
The TreeCacheProtocol would provide the following functionality:
* GetChildrenNames
* GetKey
* Get
* Exists
* PutKeyVal
* PutMap
* RemoveKey
* Remove
* Clear
* PutList
h3. MemcachedProtocol
The memcached protocol is detailed http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt.
h3. CacheServerProtocol
This will eventually become the default, and is a binary protocol providing simple map-interface equivalent commands such as:
* Get
* Put
* Remove
* Contains
* Clear
* Replace
* PutIfAbsent
* Size
--------------------------------------------------------------
16 years, 2 months
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}