
[JBoss Cache] Document updated/added: "OptimisticNodeLockingImpl"
by Manik Surtani
User development,
The document "OptimisticNodeLockingImpl", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-11545#cf
Document:
--------------------------------------------------------------
h2. Optimistic Node Locking (version 1)
by Manik Surtani (manik AT jboss DOT org) and Steve Woodcock (stevew AT jofti DOT com)
-
----
The optimistic solution is almost entirely written as interceptors, most of which have counterparts in the pessimistic chain. Transaction management from the other interceptors has been removed and put into an interceptor of its own.
The general concept is that each transaction has its own workspace - all changes take place within this workspace. All txs use 2 phase commits even if they are local and all methods have to be called inside a transaction.
If you call a method without creating a transaction a temporary one is created and the method executes within this context.
When a commit is issued, a prepare phase is entered which locks all the nodes in the workspace and validates that all changes can be applied to the cache itself. If it validates then a commit is invoked - this applies the changes and unlocks all the locks acquired in the prepare. If the prepare fails then a rollback is invoked.
When a tree is distributed the order of calls is that the local prepare is run first - then if that works a remote prepare is isssued (there is no point doing this remotely if the local can't work). If this works then a commit starts - which commits the remote txs first then the local tx.
The locks for the commit are acquired in the prepare phase so that prepares/validates run in two trees for the same nodes cannot both succeed as the locking will prevent this.
Operations that appear to take place outside a tx are actually individually wrapped in a temporary transaction that commits at then end of the method call.
h2. Interceptors
* CallInterceptor
Invokes calls on the underlying cache.
* OptimisticNodeInterceptor
Deals with all the put/get method interception for values and children - manges the addition of new
nodes into the workspace/changes in the nodes in the workspace and wrapping of returned values. All put and get methods are intercepted and are not passed down to the next interceptor.
* OptimisticCreateIfNotExistsInterceptor
Creates a new node in the workspace only if it doesn't exist on put() methods.
* OptimisticValidatorInterceptor
On a prepare the validator chacks that all the nodes in the workspace are able to be committed against (currently only simple version number) - the intention is to replace this with slightly more comples validation - this should be a configurable parameter for the user as there will be a speed/complexity tradeoff. On the commit it applies the changes to the real nodes it has in the workspace to the cache.
On rollback clears the nodes in the workspace. Does not pass prepare/commit/rollback methods to the next interceptor.
* OptimisticLockingInterceptor
On a prepare attempts to acquire write locks on all nodes in the workspace. On a commit or rollback releases all acquired locks.
* OptimisticReplicationInterceptor:
Uses 2PC to replicate workspace. Replicates synchronously on a local prepare all methods applied on the local store as a remote prepare. (if there is another tree in the view). Replicates synchronously on commit and rollback to other tree on applying these methods locally. Handles applying of all remote methods received prepare/commit/rollback.
* OptimisticTxInterceptor:
Handles all the transaction wrapping/suspending/creating for both local and remote methods. Uses 2 types of synchronisation handler to deal with commits and rollbacks for the transaction to differentiate whether local/remote. No other interceptor should deal with any of the transaction management. This is the only interceptor to register a handler (local or remote)- as this is a substitute for correct XA tx handling and so it would be better to move this when refactored accordingly. It also allows just this handler to control the whole tx sequence without anyone else calling a commit or rollback. All other interceptors just rely on method calls passed up the stack.
JBossCache (A) JBossCache (B)
CallInterceptor CallInterceptor
OptimisticNodeInterceptor OptimisticNodeInterceptor
OptimisticCreateIfNotExistsInterceptor OptimisticCreateIfNotExistsInterceptor
OptimisticValidatorInterceptor OptimisticValidatorInterceptor
OptimisticLockingInterceptor OptimisticLockingInterceptor
OptimisticReplicationInterceptor ------ ---OptimisticReplicationInterceptor
| |
OptimisticTxInterceptor | | OptimisticTxInterceptor
^ | | ^ ^
| |---------------------|---| | |
| remote call(B) |----------------| |
| remote call(A) |
|local method call) | (local method call)
h2. New Classes (that are not interceptors):
org.jboss.cache.optimistic:
h4. Comparator
Used in the workspace node tree to provide a sorted order for all fqns - even if they do not implement Comparable. This is needed because the iterator for the locking always has to acquire the locks in a tree in the same order for a particular JVM in order to prevent deadlock clashes.
The comparator walks through the fqn object list and compares each similar depth object by it's String value - even if the Object does not override toString - this allows us to ensure that for the life of say object java.lang.Object@23456 - this will remain as its fqn value and we can safely assume its order. Note the same Fqn does not have to be ordered on two JVMs in the same order - only matters that within the JVM the lock acquisition (which is local is the same). The alternative is to make all Fqn objects implement Comparable.
h4. WorkspaceNode
A sub interface of Node, with specific methods to access the actual DataNode represented by this WorkspaceNode. This interface acts as a buffer to the real DataNode in the workspace, and all operations in the workspace are performed on this. None of the operations are delegated to the underlying DataNode until commit time.
h4. WorkspaceNodeImpl
Implementation of the above.
h4. OptimisticMap
Keeps track of additions and removals without changing the underlying real map - used as a substiute for
the data and children map in the WorkspaceNode - so change are isolated from the real node maps until commit time. Removals are only recorded if they were in the original map when the wrapper was created around the real node. Essentailly acts as snapshot for the maps in the real node. The puts/removes are synchronized on the same object as there are really two data structures in each method - this is not a big bottle neck as each instance is local to a particular transaction.
h4. TransactionWorkspace
Te interface for the workspace for each transaction
h4. TransactionWorkspaceImpl
Implementation of the above. Handles the node addition/retrieval of nodes and allows subtrees of nodes to be obtained from the local node Map.
h2. Behaviour
Local call:
cache.put("/one/two","1", new Pojo());
->Invokes interceptor chain
OptimisitcTxInterceptor: does tx creation, creates a workspace if needed and synchronisation handler registration
OptimisticReplicationInterceptor: passes up
OptimisticLockingInterceptor: passes up
OptimisticValidationInterceptor: passes up
OptimisticNodeCreationInterceptor: creates nodes in workspace if not exists
OptimisitcNodeInterceptor: adds the value under the key to nodewrapper -> returns
Commit called on tx or transactionManager
Prepare Phase
-> SynchronisationHandler called: creates a prepare and passes to OptimisitcTxInterceptor
OptimisitcTxInterceptor : checks tx and passes up
OptimisticReplicationInterceptor: passes up
OptimisticLockingInterceptor: locks all nodes in workspace - if exception unlock - otherwise pass up
OptimisticValidationInterceptor: validates nodewrappers against nodes - return or throw exception
OptimisticLockingInterceptor: pass back
OptimisticReplicationInterceptor: if no exception - broadcast prepare if other trees in view - pass back or exception
OptimisitcTxInterceptor: pass back
SynchronisationHandler: if exception call rollback else commit
Commit phase
SynchronisationHandler: create commit pass up
OptimisitcTxInterceptor: checks tx and passes up
OptimisticReplicationInterceptor: call remote commit - if exception - pass up then return exception
OptimisticLockingInterceptor: pass up
OptimisticValidationInterceptor: apply changes return
OptimisticLockingInterceptor: unlock
OptimisticReplicationInterceptor: pass back
OptimisitcTxInterceptor: pass back
SynchronisationHandler: destroy entries in txtable
Rollback phase
SynchronisationHandler: create rollback pass up
OptimisitcTxInterceptor: checks tx and passes up
OptimisticReplicationInterceptor: call remote rollback - if exception - pass up then return exception
OptimisticLockingInterceptor: pass up
OptimisticValidationInterceptor: abandon workspace
OptimisticLockingInterceptor: unlock
OptimisticReplicationInterceptor: pass back
OptimisitcTxInterceptor: pass back
SynchronisationHandler: destroy entries in txtable
h2. Versioning
By default optimistically locked nodes use an internal implementation of the org.jboss.cache.optimistic.DataVersion class. Versioning may be explicit by passing in the version for each CRUD operation (using the Options API - see http://jira.jboss.com/jira/browse/JBCACHE-106 and http://community.jboss.org/docs/DOC-10277).
h2. Stuff left to do
1. Implement different validation strategies to make this more fine grained
(e.g. backward/forward validation, partial non-conflicting merges, dependency merges, etc.)
1. Write full threaded correctness tests to ensure locking behaves correctly.
2. Integrate with the AOP stuff (Are any additional changes necessary? Testing required)
3. The XA interfaces should be properly implemented so the logic can be moved out of the synchronisation handlers (which are really for callback notifications - not for running the whole tx completion phase - indeed currently the after complete is used to run the complete - which is not its intended use.
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "ConfigurationForWebLogic8.1.xSeries"
by Manik Surtani
User development,
The document "ConfigurationForWebLogic8.1.xSeries", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-9369#cf
Document:
--------------------------------------------------------------
After you start WebLogic, you will need to configure the startup and shutdown class in your web based admin console. Log in, and select 'Deployments -> Startup & Shutdown' on your navigation pane.
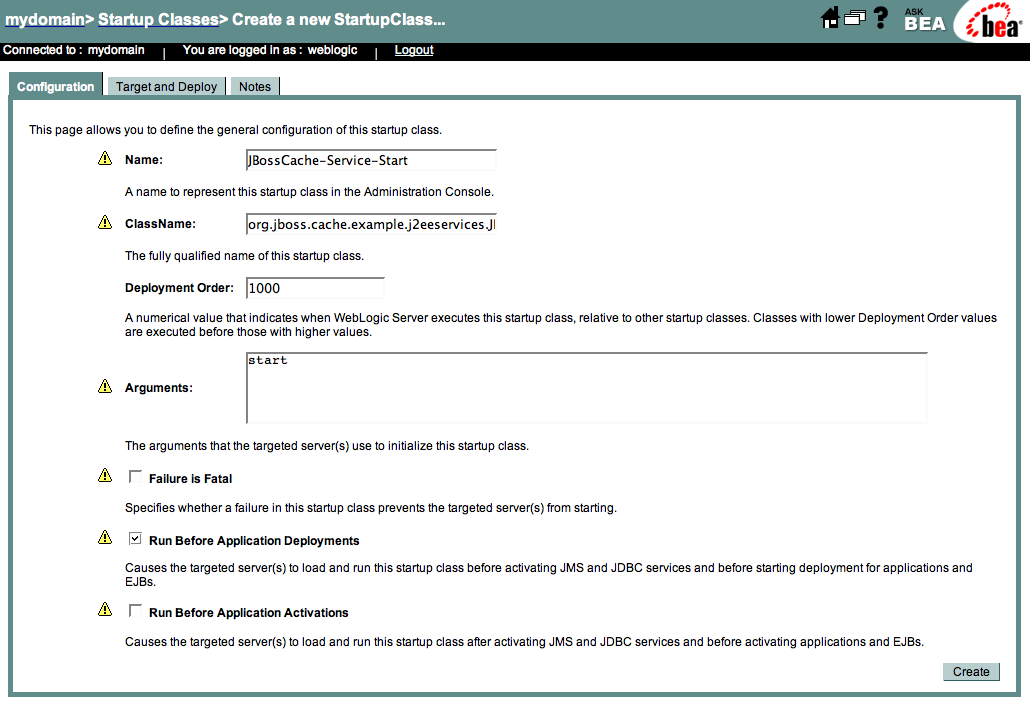
Select 'Configure a new Startup Class', and fill out details of the j2ee service class as follows:
http://community.jboss.org/servlet/JiveServlet/download/9369-6-4319/WL815...
Now select 'Configure a new Shutdown Class', and fill out the details of the j2ee service class as follows:
http://community.jboss.org/servlet/JiveServlet/download/9369-6-4317/WL815...
If you click 'Startup & Shutdown classes' now, it should look like:
http://community.jboss.org/servlet/JiveServlet/download/9369-6-4318/WL815...
h4. About the j2ee service class
This class is a simple one that takes in a single parameter, either start or stop. This parameter tells the class how to behave.
start mode: In this mode, the class simply creates a new instance of org.jboss.cache.TreeCache, starts it as a service, and binds it in JNDI.
stop mode: In this mode, the class retrieves the TreeCache from JNDI and stops the caching service.
Note that the TreeCache takes care of discovering other TreeCaches in the cluster and replicating. This is all configured in the jboss-cache configuration XML.
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "ConfigurationForWebLogic9.1.xSeries"
by Manik Surtani
User development,
The document "ConfigurationForWebLogic9.1.xSeries", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-9370#cf
Document:
--------------------------------------------------------------
WebLogic 9.1, in a bid to make things easier, have made things that much harder when deploying startup and shutdown classes.
h4. Step 1
When you log in to the web based admin console, click the "Startup and Shutdown classes" link. You should see:
http://community.jboss.org/servlet/JiveServlet/download/9370-7-4324/WL910...
h4. Step 2
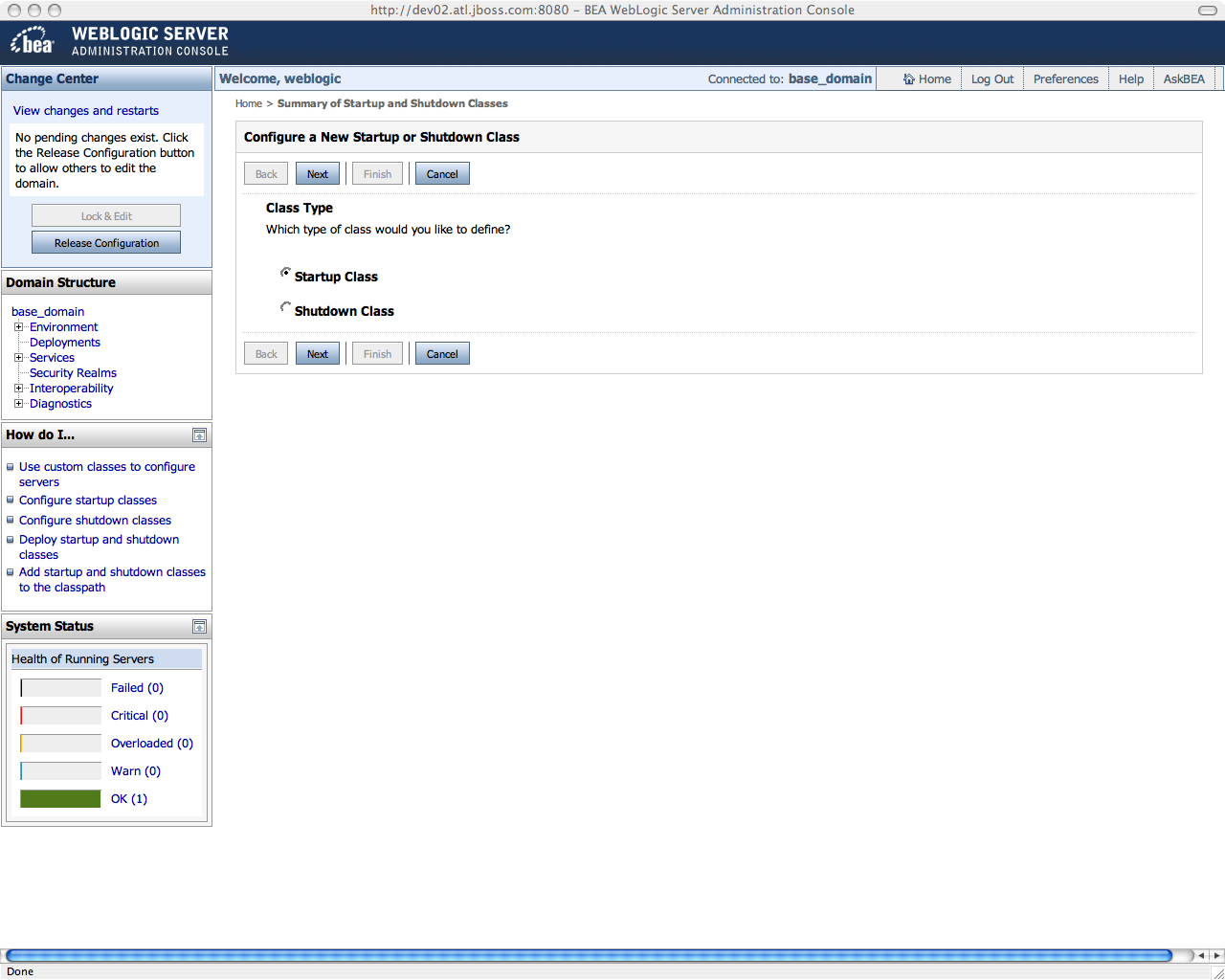
Select 'Startup Class' and click next. Enter the name of your startup class (+org.jboss.cache.example.j2eeservices.JBossCacheManager+)
http://community.jboss.org/servlet/JiveServlet/download/9370-7-4322/WL910...
Then click next and target the class to your cluster or individual servers.
h4. Step 3
Here is where things get a bit roundabout. Click on 'Startup and Shutdown Classes' again, so you see a list of configured classes. Click on the hyperlinked configuration you just created above and you should see a details page, which you should add the argument the class takes ("start") and check the box that says the class should be loaded before any applications are deployed.
http://community.jboss.org/servlet/JiveServlet/download/9370-7-4321/WL910...
Click ok to save this.
h4. Step 4
Repeat steps 1 and 2 for the shutdown class. If you are using the sample code provided, the shutdown class is the same as the startup class.
Once you have done this, go to the list of configured classes again, click on your newly configured shutdown class to get the details page - as you did in step 3 above. This time, enter "stop" as an argument.
http://community.jboss.org/servlet/JiveServlet/download/9370-7-4323/WL910...
h4. Step 5
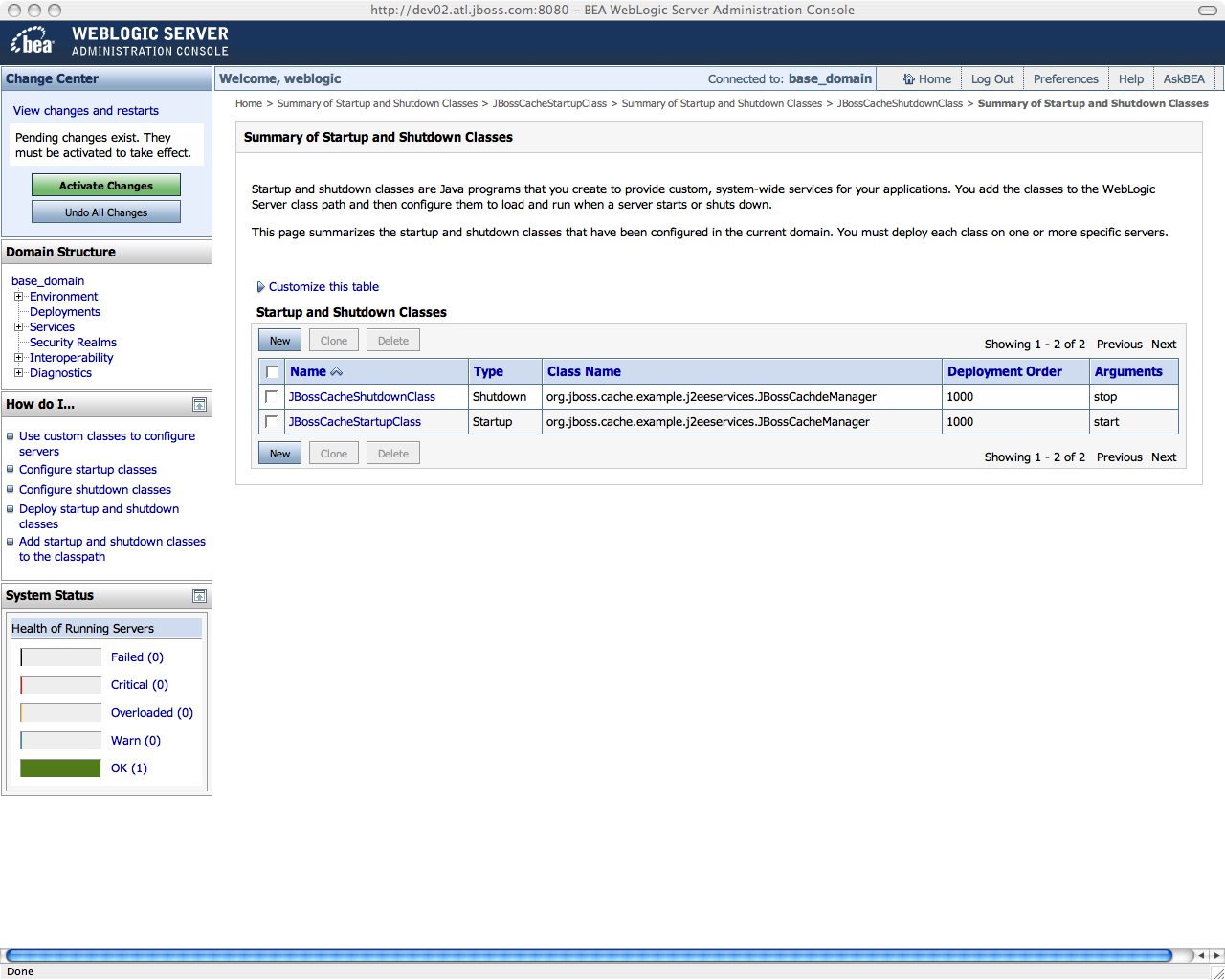
When you finally look at the list of startup and shutdown classes, you should see something like:
http://community.jboss.org/servlet/JiveServlet/download/9370-7-4320/WL910...
Don't forget to "Activate Configuration Changes" otherwise WebLogic won't pick these up!!
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossCacheOptimisticLockingPerformance"
by Manik Surtani
User development,
The document "JBossCacheOptimisticLockingPerformance", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10276#cf
Document:
--------------------------------------------------------------
h2. Intro
This page talks about the latest performance improvements in http://community.jboss.org/docs/DOC-11544 in the upcoming *JBoss Cache 1.3.0 +"Wasabi"+*.
h3. History
Optimistic locking was first released as a preview technology in JBoss Cache 1.2.4 and while we encouraged people to try it out, we did not recommend it for production use. The feedback we got from this release was invaluable though, and helped us target specific areas for improvement with the 'production' version in 1.3.0.
h3. Where have things improved?
When using optimistic locking in LOCAL mode, things were decisively slower than pessimistically locked configurations. This was due to an excessive overhead when copying node data from memory to a workspace used by the transaction. This has been heavily overhauled.
In addition, the verification process when a transaction commits was inefficient in the way it traversed node trees to look for and validate changes. This too has been heavily overhauled.
The third major bottleneck had to do with merging data froma transaction workspace back into the underlying treecache. Inefficiencies in both node traversal and copying have been worked out and removed.
h3. Where things are now
These problems compounded themselves - and particularly when using cache loaders - made optimistic locking in JBoss Cache 1.2.4 virtually unusable. In addition to other optimisations in the cache loader code, improvements made above ensure that this is no longer the case in JBoss Cache 1.3.0. While an optimistically locked will always be slower than a pessimistically locked one due to the extra processes that go in to handling the concurrency afforded by optimistic locking, it is no longer unusably slow.
h3. Performance tests
A few simple tests show that optimistic locking is a lot closer to pessimistic locking in terms of performance, all using cache mode as *LOCAL*.
The tests were run on the following environment:
* a single server
** running SuSE Enterprise Linux 9/2.6 Kernel
** 2 x 3.06 GHz P4 Xeon CPUs
** 2GB of RAM.
* Sun JDK 1.5.0_05
The format of the tests were:
* Perform a number of *put()'s*, followed by *get()'s* and then *remove()'s*, on each iteration on a separate node.
* 1000 iterations of each are run first as a 'warm up' to bring the JIT up to speed.
* 5 threads running 10000 iterations each run and measured.
h3. Results
|| Test Name || Overall Avg Time || Put Avg Time || Get Avg Time || Remove Avg Time ||
| *P/Locks (1.3.0.DR1)* | 0.04926 | 0.0537 | 0.07588 | 0.0182 |
| *O/Locks (1.3.0.DR1)* | 1.4313 | 4.0922 | 0.0793 | 0.1224 |
| *P/Locks (1.2.4.SP1)* | 0.121073333 | 0.1741 | 0.07916 | 0.10996 |
| *O/Locks (1.2.4.SP1)* | 9.941566667 | 29.64734 | 0.0704 | 0.10696 |
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossCacheBuddyReplication"
by Manik Surtani
User development,
The document "JBossCacheBuddyReplication", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10255#cf
Document:
--------------------------------------------------------------
h2. Buddy Replication
Buddy replication - the ability to replicate your HTTP or SFSB session data to specific servers in a cluster and not to everyone - is a feature that is WIP in JBossCache at the moment, and will probably not be ready for production use till the summer of 2006. That said, the goals of buddy replication could still be achieved with the new features in JBossCache 1.3 - the underpinning technology used by JBoss session replication.
Let us analyse the goals of buddy replication. Buddy replication is used:
1. to achieve failover by ensuring that collective state of a cluster is maintained even if some servers in a cluster go down.
2. to minimise network traffic that is a result of full replication of state to all servers in a cluster.
3. to minimise memory usage which is a result of each server maintaining not only its own state but the state of _every_ server in the cluster.
Until we have a production-ready buddy replication implementation, there are some interesting new features in the upcoming JBossCache 1.3 that can be used to achieve similar results.
h3. JBossCache 1.3.0 (due for release in March 2006)
Some new features in JBossCache 1.3.0 that we could use:
* Chaining Cache Loader. This feature allows you to configure more than one cache loader.
* ClusterCacheLoader. This cache loader queries in-memory state of other caches in the cluster, behaving as a cache loader.
* New cache mode - INVALIDATION rather than REPLICATION - so that when a node is updated, rather than replicating data, other caches receive an invalidation message to evict the node in memory. This way we can notify other caches in a cluster of an update without needing to replicate the changed objects.
h2. Using these features to achieve the effects of Buddy Replication
*1. To achieve durability of persistent data:*
* A chaining cache loader should be configured with a ClusteredCacheLoader and a JDBCCacheLoader.
** Use the ClusteredCacheLoader to quickly retrieve data from other caches in the cluster.
*** Should be tuned with sensible timeouts.
** Use the JDBCCacheLoader as the 'true' representation of all state in the system.
*** Should be shared so all servers use the same JDBCCacheLoader
*2. To minimise network traffic:*
* If a cache cluster were configured with invalidation rather than replication, we have effectively minimised network load.
*3. To minimise memory usage on cluster nodes:*
* Since data is not replicated to all servers in the cluster, all servers don't maintain all session data in the cluster.
* The caches should be tuned with a sensible eviction policy
h3. This does not mean we're NOT doing Buddy Replication!
Alternatives are always good, but just because we have one does not mean we will not be adding production-grade buddy replication to JBossCache in the very near future. Watch this space, but in the meanwhile, if you run a cluster of a large number of servers and want to achieve some of the goals of buddy replication, consider tuning JBossCache 1.3.0 as described above.
Buddy replication is targeted for release in JBoss Cache 1.4.0 "Jalapeno", by the end of April 2006. See JBossCacheBuddyReplicationDesign for an idea of what to expect.
h3. Sample configuration files
See http://anoncvs.forge.jboss.com/viewrep/JBoss/JBossCache/etc/META-INF/opti... in the /etc/META-INF directory of the JBossCache CVS tree.
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossCachePerfAnalysis"
by Manik Surtani
User development,
The document "JBossCachePerfAnalysis", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10279#cf
Document:
--------------------------------------------------------------
This is an experimental page to list potential bottlenecks or code inefficiencies we see in the JBC codebase. The purpose of this page is that whenever we come across any (any we cannot fix on the spot) while in the process of development of other features/debugging/tuning, we should note it down. These should, once analysed and solutions agreed upon, be converted into JIRA tasks.
|| Description || Class(es) affected || JIRA task (if any) || Potential solution ||
| Connection pooling does not occurr when JBC used standalone, affecting the performance of JDBCCL | o.j.c.l.JDBCCacheLoader | http://jira.jboss.com/jira/browse/JBCACHE-802 | Use a pooling library (i.e. C3P0) for the standalone version |
| Standard serialization is not performant and takes up far too much space | o.j.c.l.JDBCCacheLoader | http://jira.jboss.com/jira/browse/JBCACHE-879 | Reuse marshalling techniques introduced in JBC 1.4.0 and JBossSerialization for user types |
---
Elias's list
* PojoCache.detach is wasteful. PojoCache.detach returns the existing value as part of the remove, which actually does a retrieve of the existing value, then the remove. Performance testing revealed that fetching data of the underlying TreeCache was done multiple times.
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossClusteringPatternInvalidationSharedCL"
by Manik Surtani
User development,
The document "JBossClusteringPatternInvalidationSharedCL", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10293#cf
Document:
--------------------------------------------------------------
h2. Session affinity, large cluster, use of invalidation, shared cache loader
h3. IMPORTANT NOTE:
This page discusses the relevant concepts in terms of "HTTP Session replication". The configuration below is not a supported configuration for http session replication in the JBoss Application Server, and will not necessarily work properly if implemented. Readers of this page should think of the concepts on this page in terms of how to manage cached data that is logically "owned" by one server in a cluster, but which needs to be available to other servers in case of a failover. An HttpSession is conceptually that kind of data, but meeting the servlet spec and the full set of expected behaviors of an HttpSession mean that a sophisticated integration layer is required on top of the JBoss Cache. The current integration layer in JBoss AS may not work reliably with the configuration below.
h3. Author
Manik Surtani (mailto:manik@jboss.org)
h3. Use case
You have a large cluster of application servers and the overhead of replicating state is high. Network traffic and memory usage on each node is a problem and scaling is difficult. Data may be accessed on different nodes, although this is infrequent and typically sessions are sticky.
h3. Prerequisites
To use this pattern, you must:
* Use a load balancer
* Use sticky sessions
* JBoss Cache 1.3.0 "Wasabi" and above
h3. Description
JBoss Cache 1.3.0 has several features that can be used to help this scenario, in this case:
* Invalidation
* Chaining cache loaders
Since sessions are sticky, there is often no need for each node in the cluster to have access to all session data. We are concerned though that this data may live on another server as well and hence cannot rely on suppressing replication as this will result in stale data. Here is where we use a new cache mode, Invalidation. Invalidation offers you a chance to send evict messages to the cluster when data changes. evict messages are small and efficient, and will ensure that other caches in the cluster mark data as stale if the data has been modified elsewhere.
We revert back to a cache loader again to deal with the case of retrieving data and picking up from a failed node. A JBossClusteringPatternsFarCache may be used, but in this case I will consider a shared JDBC cache loader.
Keep in mind that in JBoss Cache 1.3.0 onwards, cache loaders can even be http://community.jboss.org/docs/DOC-10257.
h3. Sample configuration
h4. Configuring JBoss Cache on your cluster
<?xml version="1.0" encoding="UTF-8"?>
<server>
<classpath codebase="./lib" archives="jboss-cache.jar, jgroups.jar"></classpath>
<mbean code="org.jboss.cache.TreeCache"
name="jboss.cache:service=TreeCache">
<depends>jboss:service=Naming</depends>
<depends>jboss:service=TransactionManager</depends>
<attribute name="TransactionManagerLookupClass">org.jboss.cache.DummyTransactionManagerLookup</attribute>
<attribute name="IsolationLevel">REPEATABLE_READ</attribute>
<attribute name="CacheMode">INVALIDATION_ASYNC</attribute>
<attribute name="UseReplQueue">true</attribute>
<attribute name="ReplQueueInterval">2000</attribute>
<attribute name="ReplQueueMaxElements">25</attribute>
<attribute name="ClusterName">TreeCache-Cluster</attribute>
<attribute name="ClusterConfig">
<config>
<UDP mcast_addr="228.1.2.3" mcast_port="48866"
ip_ttl="64" ip_mcast="true"
mcast_send_buf_size="150000" mcast_recv_buf_size="80000"
ucast_send_buf_size="150000" ucast_recv_buf_size="80000"
loopback="false"></UDP>
<PING timeout="2000" num_initial_members="3"
up_thread="false" down_thread="false"></PING>
<MERGE2 min_interval="10000" max_interval="20000"></MERGE2>
<FD_SOCK></FD_SOCK>
<VERIFY_SUSPECT timeout="1500"
up_thread="false" down_thread="false"></VERIFY_SUSPECT>
<pbcast.NAKACK gc_lag="50" retransmit_timeout="600,1200,2400,4800"
max_xmit_size="8192" up_thread="false" down_thread="false"></pbcast>
<UNICAST timeout="600,1200,2400" window_size="100" min_threshold="10"
down_thread="false"></UNICAST>
<pbcast.STABLE desired_avg_gossip="20000"
up_thread="false" down_thread="false"></pbcast>
<FRAG frag_size="8192"
down_thread="false" up_thread="false"></FRAG>
<pbcast.GMS join_timeout="5000" join_retry_timeout="2000"
shun="true" print_local_addr="true"></pbcast>
<pbcast.STATE_TRANSFER up_thread="true" down_thread="true"></pbcast>
</config>
</attribute>
<attribute name="LockAcquisitionTimeout">10000</attribute>
<attribute name="UseMarshalling">false</attribute>
<attribute name="CacheLoaderConfiguration">
<config>
<passivation>false</passivation>
<shared>true</shared>
<cacheloader>
<class>org.jboss.cache.loader.JDBCCacheLoader</class>
<properties>
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
cache.jdbc.table.primarykey=jbosscache_pk
cache.jdbc.fqn.column=fqn
cache.jdbc.fqn.type=varchar(255)
cache.jdbc.node.column=node
cache.jdbc.node.type=longblob
cache.jdbc.parent.column=parent
cache.jdbc.driver=com.mysql.jdbc.Driver
cache.jdbc.url=jdbc:mysql://db_host.mycorp.com:3306/jbossdb
cache.jdbc.user=root
cache.jdbc.password=
</properties>
<async>true</async>
<fetchPersistentState>false</fetchPersistentState>
<ignoreModifications>true</ignoreModifications>
</cacheloader>
</config>
</attribute>
</mbean>
</server>
*Referenced by:*
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossClusteringPatternsLibrary"
by Manik Surtani
User development,
The document "JBossClusteringPatternsLibrary", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10294#cf
Document:
--------------------------------------------------------------
h2. The JBoss Clustering Patterns Library
h3. What is this?
The JBoss Clustering Patterns library is a collection of reusable clustering architectural patterns and configurations. Following the style of the http://en.wikipedia.org/wiki/GoF patterns, this each pattern in this collection includes *a use case*, *prereqisites*, *description*, and even *sample configuration files* and a link to a thread in the JBoss Clustering user forum where real live uses of such patterns can be discussed.
In general, these are tried and tested real-world configurations. We encourage JBoss users to submit their own patterns and ideas, and where possible, mention where such patterns are used.
h3. The patterns
1. http://community.jboss.org/docs/DOC-10292
2. http://community.jboss.org/docs/DOC-10293
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossCacheOptionsAPI"
by Manik Surtani
User development,
The document "JBossCacheOptionsAPI", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10277#cf
Document:
--------------------------------------------------------------
h2. JBossCache Options API
This API allows users to pass in configuration overrides on a per-invocation basis. *Note:* Refer to the http://labs.jboss.com/portal/jbosscache/docs/index.html on the Option class for up-to-date information on the API available.
In *JBossCache 1.3.0 +"Wasabi"+* the following options are be supported:
* *cacheModeLocal* - overriding CacheMode from REPL_SYNC, REPL_ASYNC, INVALIDATION_SYNC, INVALIDATION_ASYNC to LOCAL. Only applies to put() and remove() methods on the cache.
* *failSilently* - suppress any failures in your cache operation, including version mismatches with optimistic locking, timeouts obtaining locks, transaction rollbacks. If this is option is set, the method invocation will *never fail or throw an exception*, although it may not succeed. With this option enabled the call will *not* participate in any ongoing transactions even if a transaction is running.
* *dataVersion* - passing in an org.jboss.cache.optimistic.DataVersion instance when using optimistic locking will override the default behaviour of internally generated version info and allow the caller to handle data versioning.
Since *JBossCache 1.4.0 +"Jalapeno"+*:
* *suppressLocking* - Suppresses acquiring locks for the given invocation. Used with pessimistic locking only. Use with extreme care, may lead to a breach in data integrity!
* *forceDataGravitation* - enables data gravitation calls if a cache miss is detected when using http://community.jboss.org/docs/DOC-10256. Enabled only for a given invocation, and only useful if autoDataGravitation is set to false. See http://community.jboss.org/docs/DOC-10256 documentation for more details.
Since *JBossCache 2.0.0 +"Habanero"+*:
* *forceWriteLock* - set to force a write lock being obtained (only used with pessimistic locking) even if the call is a READ call. Useful to emulate SELECT FOR UPDATE semantics.
> Note
>
> you only need to set the options you wish to use. You may set one or more of the options, leave the ones you don't wish to use as unset.
See http://anoncvs.forge.jboss.com/viewrep/JBoss/JBossCache/src/org/jboss/cac...
h3. Transactions
This new API does have specific behaviour when used in a transactional context, that users will need to be aware of:
* The last method invocation before the transaction is committed or rolled back is consulted for the *cacheModeLocal* option.
* Whenever the *failSilently* option is used the method invocation does not participate in any ongoing transactions. If a transaction is present, it is suspended, the method is invoked and then the transaction is resumed.
h2. For JBossCache Interceptor authors
* Use Interceptor.getInvocationContext() to get a hold of an InvocationContext
* InvocationContext.getOptionOverrides() to get the Option object associated with a particular invocation.
** this may be null
h2. The future
Future versions of JBossCache will have more override options available through this API, allowing you to configure locking, isolation levels, etc. on a more fine-grained basis. Watch this space!
--------------------------------------------------------------
16 years, 4 months
[JBoss Cache] Document updated/added: "JBossCacheBuddyReplicationDesign"
by Manik Surtani
User development,
The document "JBossCacheBuddyReplicationDesign", was updated Feb 22, 2010
by Manik Surtani.
To view the document, visit:
http://community.jboss.org/docs/DOC-10256#cf
Document:
--------------------------------------------------------------
h2. Buddy Replication for JBoss Cache 1.4.0 "Jalapeno"
- Manik Surtani (mailto:manik@jboss.org)
+(http://www.jboss.com/index.html?module=bb&op=viewtopic&t=78308)+
h3. Introduction
Buddy replication is based on a concept where data is replicated to a finite number of nodes in a cluster rather than the entire cluster. This helps a cluster scale by not impacting network replication traffic, nor node memory usage as more nodes are added.
h4. Network traffic cost
Network traffic is always restricted to the number of buddy nodes configured. This may not be that great a saving as IP multicast may be used to broadcast changes, but replies (if synchronous replication is used) and subsequent wait time will increase in a linear fashion with every node added to a cluster. When the number of buddies is finite and fixed, nodes can be added to a cluster without any such impact as this replication cost is always static.
h4. Memory cost
With buddy replication, memory usage for each node will be approximately (b+1) X where X is the average data size of each node and b is the number of buddies per node. This scales a lot better than total replication where each node would hold nX where n is the number of nodes in the cluster. Being a function of n, you can see that with total replication, memory usage per node increases with the number of nodes while with buddy replication, this does not happen.
h4. Pre-requisties and assumptions
It is assumed that a decent load balancer will be in use so requests are evenly spread across a cluster and sticky sessions (or equivalent for use cases other than HTTP session replication) are used so that recurring data accesses happen on fixed nodes.
h3. Design concepts
For the sake of simplicity in explanation, I will assume that the number of buddies are set at *1*.
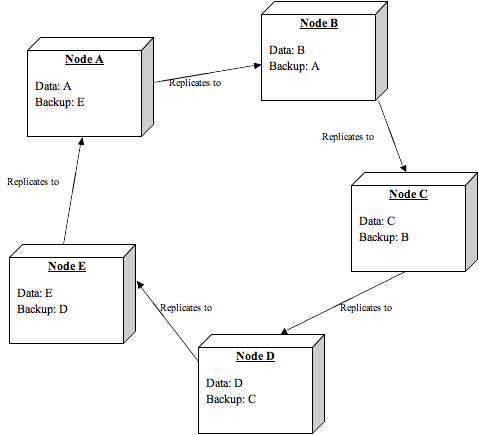
*Diagram 1: Operational cluster*
http://community.jboss.org/servlet/JiveServlet/download/10256-46-4658/Bud...
*Diagram 2: With node failure*
http://community.jboss.org/servlet/JiveServlet/download/10256-46-4659/Bud...
* Assume 5 nodes in a cluster, nodes A, B, C, D and E.
* Each node has its own data, and the backup data of one other node.
* Data is only replicated to the buddy node, not to the entire cluster (synchronous or asynchronous replication may be used)
* If a node fails (e.g., A is removed from the cluster) its data is still backed up on B. As nodes start looking for this data, it gravitates from B to the requesting node, which will now take ownership of this data and treat it as its own.
** B then starts acting as backup node for E.
h4. Gravitation of data
* As requests come in to cache instances which do not have the requested data locally, nodes then ask the cluster for the data and move that data to their local state.
* Taking ownership of this data allows for the data most used by specific cache instances to be located closest to such cache instances.
* When a cache instance takes ownership of data, it forces the original owner (and any buddies) to remove this data from their in-memory state.
* In the above scenario, this allows for the original state of A - backed up on B - to spread out evenly across the cluster as the load balancer directs requests meant for A across the cluster.
h4. Alternative implementation: Data slicing
The alternative to such a scenario where a node inherits all the backup data of a dead node is for the backup node to slice the data evenly and distribute it across the remaining cluster nodes rather than taking ownership of the data.
For a number of reasons, I have decided that this is an unfeasible approach and +not+ to implement it:
* Organisation within a tree of data is unknown and slicing may result in corrupt data.
* Even when specifically speaking of HTTP Session replication where data structure is known, when TreeCacheAOP is used (FIELD level replication) we don't know the relationship between data elements which makes slicing a challenge again.
* Traversing the tree to try and 'guess' data boundaries for slicing may be expensive.
I also see slicing as unnecessary because using data gravitation alleviates the imbalance of some nodes holding more data than others in a cluster.
h3. Dealing with more than 1 buddy
Behaviour is precisely the same as when dealing with just one buddy. The first instance to provide a valid respose to a data gravitation request is the one that is used as the source of data.
h4. A buddy node dies
* The Data Owner detects this, and nominates more buddies to meet its configured requirement.
** Initiates state transfers to these buddies so backups are preserved.
h2. Implementation overview
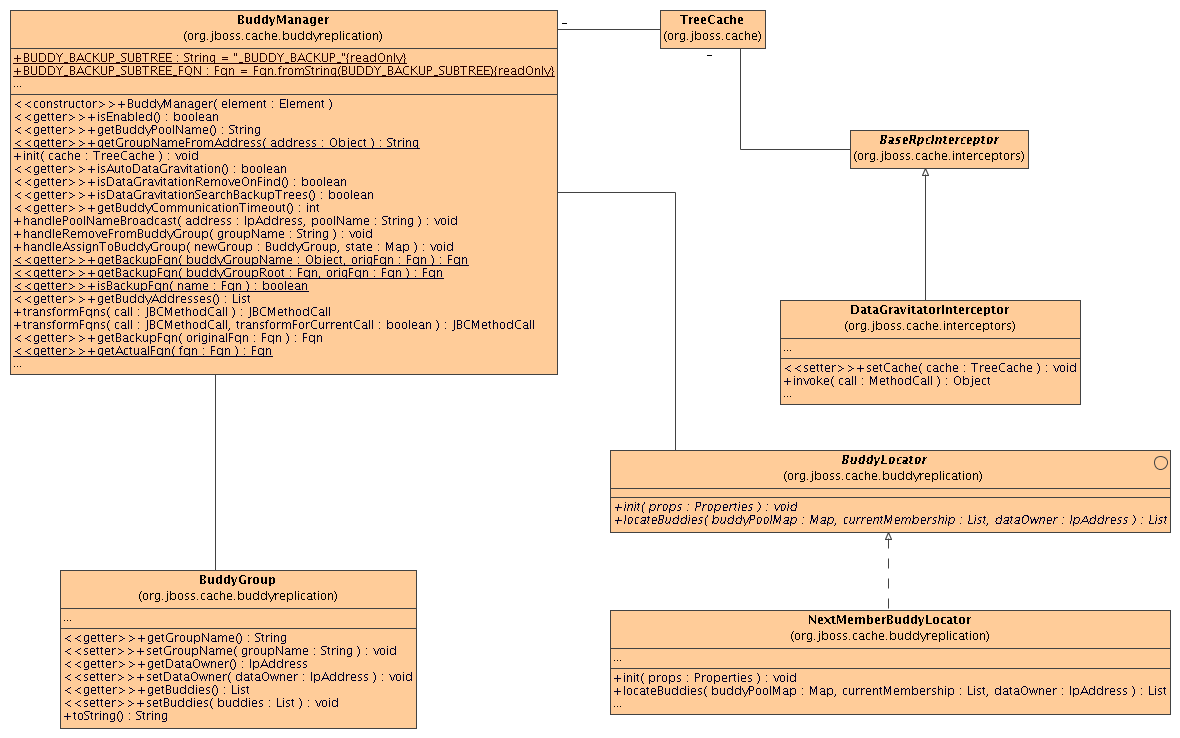
Buddy replication will be implemented by enhancing the BaseRPCInterceptor. This way existing replication semantics do not change in any of the subclasses of the BaseRPCInterceptor - the only thing that changes is the BaseRPCInterceptor.replicateCall() method, which based on configuration, replicates to the entire group or to specific nodes.
The BaseRPCInterceptor will maintain a reference to a BuddyManager (if configured), which will use a BuddyLocator (see below) to maintain a list of buddies.
h3. Configuring buddy replication
A new configuration element - BuddyReplicationConfig - will be used. The element will take an XML config element, to maintain consistency with the way eviction policies and cache loaders are configured.
<attribute name="BuddyReplicationConfig">
<config>
<buddyReplicationEnabled>true</buddyReplicationEnabled>
<buddyLocatorClass>org.jboss.cache.cluster.NextMemberBuddyLocator</buddyLocatorClass>
<buddyCommunicationTimeout>15000</buddyCommunicationTimeout>
<buddyLocatorProperties>numBuddies = 3</buddyLocatorProperties>
<dataGravitationRemoveOnFind>true</dataGravitationRemoveOnFind>
<dataGravitationSearchBackupTrees>true</dataGravitationSearchBackupTrees>
<autoDataGravitation>false</autoDataGravitation>
<buddyPoolName>groupOne</buddyPoolName>
</config>
</attribute>
If this configuration element is left empty or is ignored altogether, the BaseRPCInterceptor will revert to replicating to the entire cluster.
The buddyLocatorClass element is optional, and defaults to NextMemberBuddyLocator. The configuration element is provided for future expandability/customisation.
The buddyPoolName element is optional, and if specified, creates a logical subgroup and only picks buddies who share the same buddy pool name. This helps you (the sys admin) assert some control over how buddy selection takes place. For example, you may have 3 power sources in your HA cluster and you may want to ensure that buddies picked are never on the same power source. If not specified, this defaults to an internal constant name which then treats the entire cluster as a single buddy pool.
The buddyCommunicationTimeout property is optional and defaults to 10000. This is the timeout used for RPC calls to remote caches when setting up buddy groups.
The only mandatory property here is buddyReplicationEnabled, which is used to enable/disable buddy replication.
In its simplest form, Buddy Replication could be enabled with:
<attribute name="BuddyReplicationConfig">
<config>
<buddyReplicationEnabled>true</buddyReplicationEnabled>
</config>
</attribute>
h3. Gravitation of data
Data gravitation is implemented as an Interceptor, that sits after the CacheLoaderInterceptor. If data gravitation is enabled for the invocation (more on this in a bit)
the interceptor tests if the node exists in teh cache (after potentially loading/activating it). If not, it will broadcast a data gravitation call for this node and all
subnodes, and proceed to take ownership of it.
Enabling data gravitation for a particular invocation can be done in two ways. Enabling autoDataGravitation (false by default) or by setting an Option (see the Options API).
h3. Finding your buddy
Upon startup, the BuddyManager will use the configured BuddyLocator implementation to help it locate and select its buddy or buddies. Note that the BuddyLocator is only invoked when a change in cluster membership is detected.
h3. Backing up data
To ensure that backup data is maintained separate from primary data on each node, each node will use an internal subtree for each buddy group it participates in, and will contain the name of the Buddy Group it is backing up for. This Buddy Group name is simply a String representation of JGroups Address of the Data Owner of that Buddy Group.
/_buddy_backup_/server01:7890/
/_buddy_backup_/server02:7890/
Also, users would have to ensure that any eviction policies set up are not applied to the /_buddy_backup_ subtree.
h2. Implementation details
http://community.jboss.org/servlet/JiveServlet/download/10256-46-4660/Pac...
h3. 1. TreeCache
The TreeCache class will be enhanced to define 3 new internal methods:
* public void _remoteAssignToBuddyGroup(BuddyGroup group, Map state)
* public void _remoteRemoveFromBuddyGroup(String groupName)
* public void _remoteAnnounceBuddyPoolName(IpAddress address, String buddyPoolName)
The first two methods are called on remote caches (buddies) by Data Owners to add them or remove them from a BuddyGroup.
The last one is called on all remote caches (multicast) every time a view change is detected, so each cache has an accurate map of buddy pools. This method is only called if a buddy pool is configured.
h3. 2. BuddyManager
This class controls the group for which a TreeCache instance is a Data Owner as well as all other groups for which the TreeCache instance participates as a buddy. If buddy replication is configured, an instance of BuddyManager is created and referenced by the TreeCache.
* The BuddyManager maintains a reference to a single BuddyGroup for which the TreeCache instance is Data Owner, as well as a collection of BuddyGroups for which the TreeCache is a buddy.
* Creates a BuddyGroupMembershipMonitor, which implements TreeCacheListener, and registers this monitor to react to changes in the underlying group structure.
* Maintains a reference to an instance of BuddyLocator, used to build a BuddyGroup.
h3. 3. BuddyGroup
This class maintains a List of Addresses which represent the buddy nodes for the group. The class also maintains an Address reference of the Data Owner as well as a String representing the group name (dataOwnerAddress.toString()?). The class also creates an Fqn which is a backup root for this group, typically being the value of Fqn.fromString("/_buddy_backup_/" + groupName). This is used by BuddyManager.transformFqns(MethodCall call).
This class will be passed over the wire as an argument to RPC calls.
h3. 4. BaseRPCInterceptor
When replicateCall() is called on this interceptor, it will only replicate to BuddyManager.getBuddyAddresses() rather than the entire cluster, if a BuddyManager is available. In addition, it will transform the method call it tries to replicate by using BuddyManager.transformFqns(MethodCall call) before replicating anything.
h3. 5. BuddyLocator
This interface defines 2 methods:
public void init(Properties p);
which is used to pass in locator specific properties to the implementation on startup.
public List getBuddies(List groupMembers);
selects one or more buddies from a list of group members. End users may extend buddy replication functionality by providing their own buddy locating algorithms.
h4. NextMemberBuddyLocator
Will be shipped with JBoss Cache. Picks a buddy based on who is 'next in line'. Will take in an optional configuration property numBuddies (defaults to 1) and will attempt to select as many buddies when getBuddies() is called. This also takes in another optional configuration property ignoreColocatedBuddies, defaulting to true, which ensures that nodes on the same physical machine are not selected as buddies.
Colocated nodes are detected by comparing their InetAddress properties. We can also detect all the InetAddress instances available on a single host by consulting the enumeration returned by java.net.NetworkInterface.getNetworkInterfaces(). This will conclusively tell us whether 2 cluster members are on the same host or not.
Only buddies who share the same pool name are considered if buddyPoolName is configured.
In the end, buddy pools and ignoring colocated hosts are just hints - if no buddies can be found to meet these constraints, buddies that don't meet these constraints will be tried.
h3. Transferring state
h4. When nominating buddies
When a buddy is nominated to participate in a BuddyGroup (by having its _remoteAssignToGroup() method called), the Data Owner's state will be pushed as an argument of the call. State is then stored under /_buddy_backup_/server01:7890/. Note that this takes place in a separate thread, so that _remoteAssignToGroup() can return immediately.
h4. Changes to state transfer code
One major change in the state transfer code will be to exclude anything under /_buddy_backup_ when marshalling the tree.
Also, when invoked by BuddyManager.assignToGroup(), the state transfer process should be able to store state received in the relevant backup subtree. This may mean overloading the local state transfer method with a root under which state would be stored, defaulting to TreeCache.getRoot(). Note that this does *not* affect remote state transfer methods so there should be no issue regarding backward compatibility.
Also, with buddy replication, initial state transfers should always be disabled as nodes will pull down state relevant to their BuddyGroups as they are assigned to such groups.
h3. Further Reading and Research References
The following articles and papers were used as sources in understanding other implementations of buddy replication andsimilar mechanisms.
* http://www.theserverside.com/articles/article.tss?l=J2EEClustering
* http://scholar.google.com/scholar?hl=en&lr=&q=cache:QPvLwGBF4QMJ:www.stan...
* http://www.usenix.org/events/hotos03/tech/full_papers/ling/ling_html/inde...
* http://www.cs.nyu.edu/~nikos/papers/ling.pdf
Related wiki pages:
* BuddyReplicationAndHttpSessions
* BuddyReplicationAndClusteredSSO
+(http://www.jboss.com/index.html?module=bb&op=viewtopic&t=78308)+
--------------------------------------------------------------
16 years, 4 months
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}