
6:42 p.m.
Hi guys,
I've drafted the alternative implementation of JDBC cache loader. Just a
brief, the base idea is to to traverse the tree in preorder and add some
indexing info to each node.
The affected methods are remove(Fqn), loadState(Fqn subtree, ..) and
put(Fqn, value).
How I've tested the performance:
a tree with a TREE_DEPTH depth is created. Each node in the tree has a
CHILDREN number of children. By default I've used TREE_DEPTH=7 and
CHILDREN=3 which gave a total number of 3280 children. A node is selected at
each depth from disjunct subtrees. ( i.e. in the benchmark used 7 nodes
are selected). On all those nodes a certain operation is performed:
loadState or remove. For benchmarking the put operation, the in memory tree
nodes are Collections.shuffle(List<Fqn>), then they are (randomly) added to
the database/classLoader.put. Also additional testing was performed in the
case of put for deep trees (100 - 200 nodes)
Results:
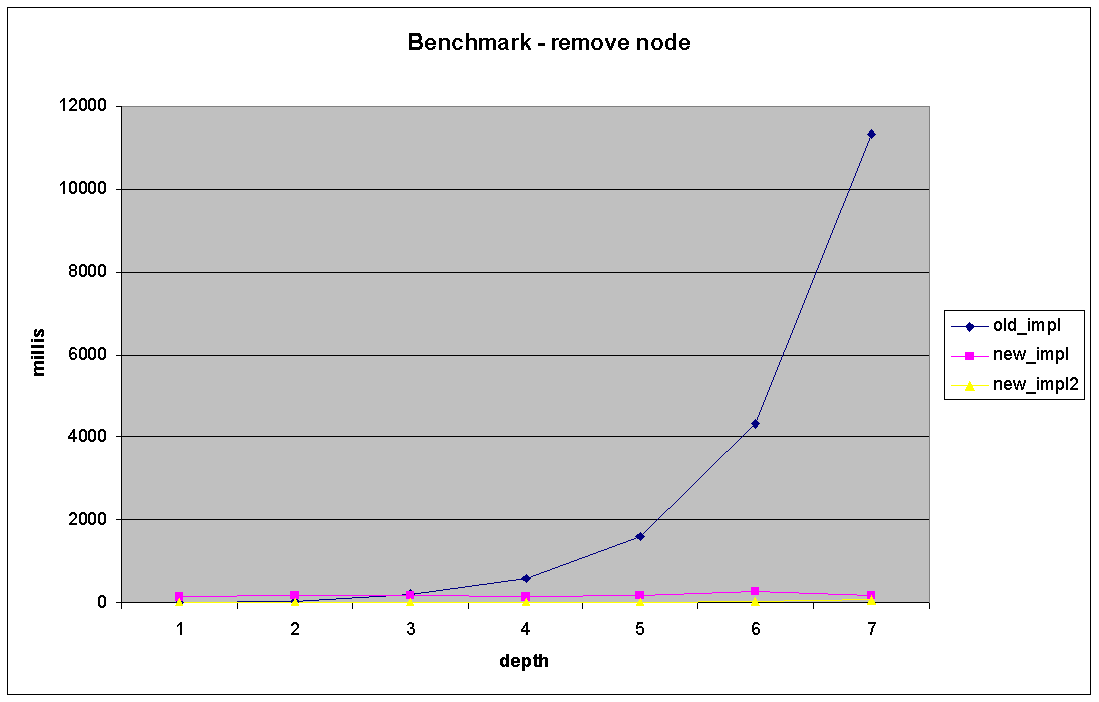
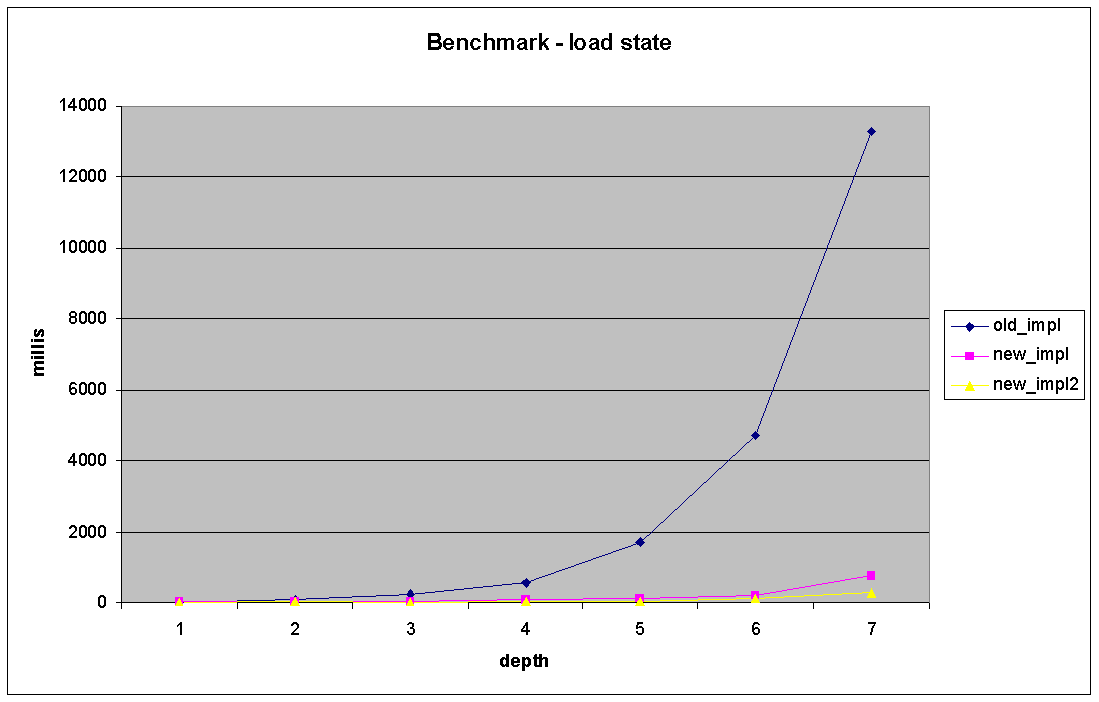
On the load and delete the new implementation is much more better. The
new deletion time is linear compared with the old approach where recursive
db calls lead to an exponential raise(see - remove_node_all.PNG). Relatively
the same in the case of loading subtrees(see - remove_node_all.PNG).
The problem is in the case of additions. When adding all 3280 nodes the time
is constantly 10 times bigger than when using existing implementation.
Profiling shewed that the update_indexes operation behaves really badly -
nothing to do in this area. Even if the operation is totally moved in the
database (mysql 5.0.X has limitations on working with triggers so I've used
a stored procedure) is doesn't cause an significant increase.
Another approach.
Another approach I've consider is to reduce the recursive DB calls to a fix
number. All operation rely on the fact that the entire fqn is persisted for
each node. E.g. when deleting node(/a/b/c) I'll remove all records that
have a path starting with (/a/b/c/). Same in the case of node loading. It
proved to work even better than in the case of first implementation.
Recursion in the case of insertions - I've solved this by
a) querying for the first persited ancestor
b) add all the children in a batch pr statement.
Interestingly enough this always-2-queries approach is 30% slower than the
old recursive impl. Profiling showed that the db driver (mysql-connector/J)
takes the same time for executing a batch (new impl) as it takes in the case
of individual calls (old impl).Also the firstAncestor query takes quite long
on mysql. Another observation is that new impl proves much better in the
case of deeper trees, and fails up-2 50% in the case of flatter trees. An
interesting thing would be to see it working on an Oracle/SqlServ... The
good news is that old implementation can be used instead - or a policy can
be defined to use the new impl where tree structure requires it.
Naturally I'd chose the second approach - if you don't see any problem with
it
I'll stop here :)
Cheers,
Mircea
{kind=link}
{kind=link}

5:34 a.m.
Nice one Mircea.
Some comments:
* Re: your "second impl", For the sake of general portability I'd
stay away from prepared statements/triggers and strive for a Java-
only solution. I'd leave optimisations such as prepared statements
for people who want to further customise the JDBCCacheLoader for
their specific DBMS product. Then again, this could be a
configuration param where the "default" is to use the Java-only
solution, and *if* the name and signature of a prepared statement is
provided for a batch insert then use this.
* Again in the case of your second approach, you're using the fact
that Fqns "start with" a particular string (e.g., "/a/b/c/") and
removing these when you need to call a remove ("/a/b/c") is fine,
only it still assumes that Fqns are comprised only of Strings. This
is fine, this limitation currently exists in the JDBCCacheLoader
anyway, just highlighting.
* "Also the firstAncestor query takes quite long on mysql." - What is
this query? Is this a case of, if I am adding ("/a/b/c") you need to
do a SELECT ... WHERE FQN="/a/b" ?Why is this specifically slower
than any other SELECT on an indexed column?
* "Another observation is that new impl proves much better in the
case of deeper trees, and fails up-2 50% in the case of flatter
trees." - what do you mean by fails? I hope this "just" means worse
performance rather than functional failure? :-) And if so, how much
worse is this with flatter trees, and what is this threshold? 2
nodes deep, 3 nodes deep, etc?
Cheers,
--
Manik Surtani
Lead, JBoss Cache
JBoss, a division of Red Hat
Email: manik(a)jboss.org
Telephone: +44 7786 702 706
MSN: manik(a)surtani.org
Yahoo/AIM/Skype: maniksurtani
On 29 Jan 2007, at 00:42, Mircea Markus wrote:
Hi guys,
I've drafted the alternative implementation of JDBC cache loader.
Just a brief, the base idea is to to traverse the tree in preorder
and add some indexing info to each node.
The affected methods are remove(Fqn), loadState(Fqn subtree, ..)
and put(Fqn, value).
How I've tested the performance:
a tree with a TREE_DEPTH depth is created. Each node in the tree
has a CHILDREN number of children. By default I've used
TREE_DEPTH=7 and CHILDREN=3 which gave a total number of 3280
children. A node is selected at each depth from disjunct
subtrees. ( i.e. in the benchmark used 7 nodes are selected). On
all those nodes a certain operation is performed: loadState or
remove. For benchmarking the put operation, the in memory tree
nodes are Collections.shuffle(List<Fqn>), then they are (randomly)
added to the database/classLoader.put. Also additional testing was
performed in the case of put for deep trees (100 - 200 nodes)
Results:
On the load and delete the new implementation is much more
better. The new deletion time is linear compared with the old
approach where recursive db calls lead to an exponential raise(see
- remove_node_all.PNG). Relatively the same in the case of loading
subtrees(see - remove_node_all.PNG).
The problem is in the case of additions. When adding all 3280 nodes
the time is constantly 10 times bigger than when using existing
implementation. Profiling shewed that the update_indexes operation
behaves really badly - nothing to do in this area. Even if the
operation is totally moved in the database (mysql 5.0.X has
limitations on working with triggers so I've used a stored
procedure) is doesn't cause an significant increase.
Another approach.
Another approach I've consider is to reduce the recursive DB calls
to a fix number. All operation rely on the fact that the entire fqn
is persisted for each node. E.g. when deleting node(/a/b/c) I'll
remove all records that have a path starting with (/a/b/c/). Same
in the case of node loading. It proved to work even better than in
the case of first implementation.
Recursion in the case of insertions - I've solved this by
a) querying for the first persited ancestor
b) add all the children in a batch pr statement.
Interestingly enough this always-2-queries approach is 30% slower
than the old recursive impl. Profiling showed that the db driver
(mysql-connector/J) takes the same time for executing a batch (new
impl) as it takes in the case of individual calls (old impl).Also
the firstAncestor query takes quite long on mysql. Another
observation is that new impl proves much better in the case of
deeper trees, and fails up-2 50% in the case of flatter trees. An
interesting thing would be to see it working on an Oracle/
SqlServ... The good news is that old implementation can be used
instead - or a policy can be defined to use the new impl where tree
structure requires it.
Naturally I'd chose the second approach - if you don't see any
problem with it
I'll stop here :)
Cheers,
Mircea
<load_state_all.PNG>
<remove_node_all.PNG>
_______________________________________________
jbosscache-dev mailing list
jbosscache-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/jbosscache-dev
7010
days inactive
7010
days old
jbosscache-dev@lists.jboss.org
1 comments
2 participants
participants (2)
-
 Manik Surtani
Manik Surtani -
 Mircea Markus
Mircea Markus