
10:21 a.m.
Hi,
I am looking for feedback on changes to provide the ability for work
to be completed in a currently running transaction. For example when a
TableGenerator or SequenceGenerator is being used for generating unique
ids. The statements that select then update the db are executed in a
separate transaction.
There is a jira for this feature.
https://hibernate.atlassian.net/browse/HHH-8429
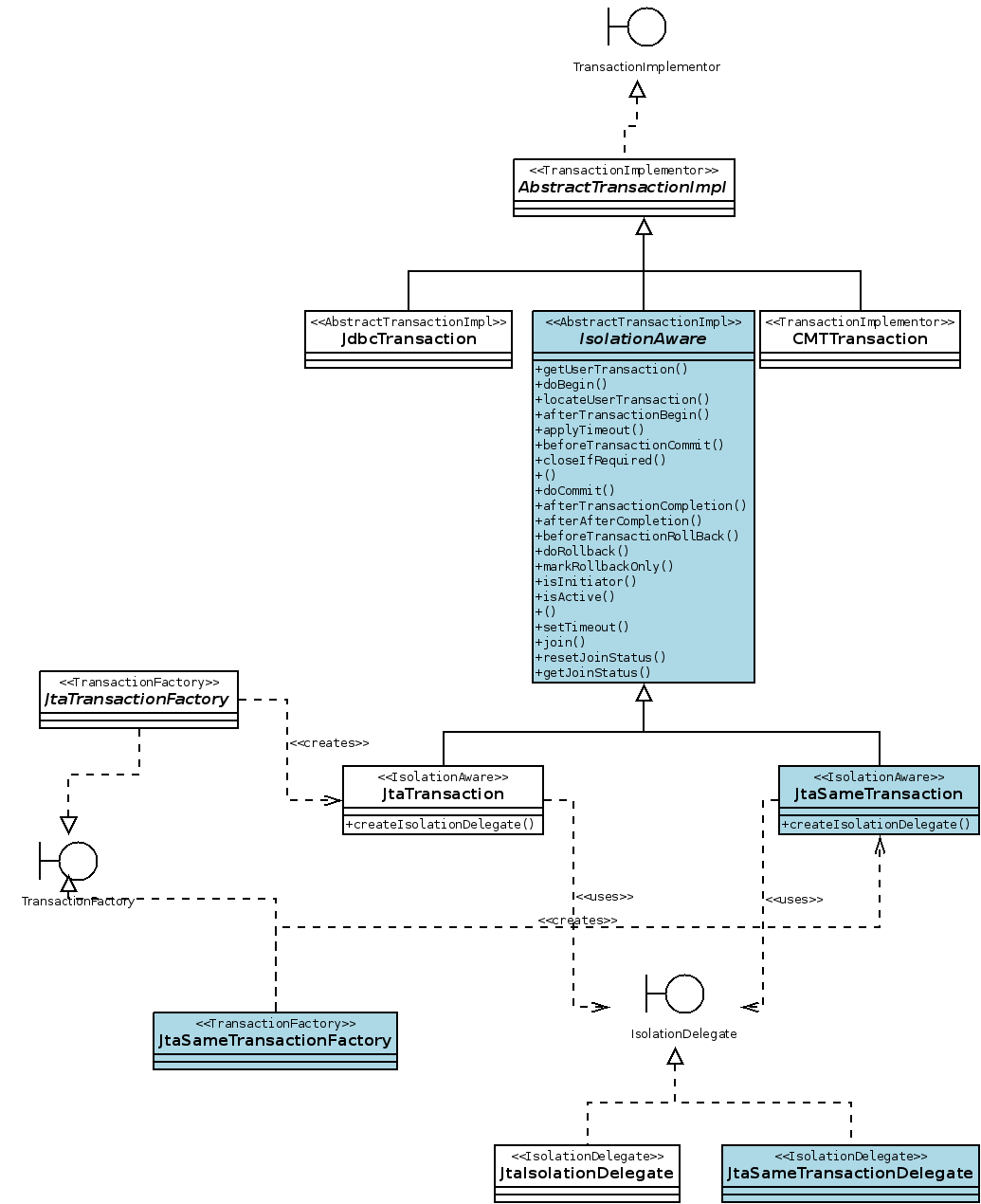
Attached to the jira is a diagram. See this link
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
This diagram shows what I currently have implemented. It shows the
existing classes and the new classes shaded in light blue. The methods
on a new class IsolationAware show how I've re-jigged most the
implementation from JtaTransaction to it's new ancestor IsolationAware.
A new concrete implementation of IsolationDelegate will negotiate the
work to be executed in the same running transaction.
The structure splits up the factory/transaction/delegate classes into
two groups. "same transaction" and "separate transaction". This has
only
been done for JtaTransaction and the same will probably be necessary for
CMTTransaction as it also uses a separate transaction to complete work.
That has been left out to keep the diagram simple.
The option of using aggregation at the point where implementers of
TransactionImplementor are instantiated has been considered. Before too
much effort is expended coding I wondered what others thought is the
preferred way to implement this feature.
Jeremy
{kind=link}

12:20 p.m.
On 08/08/2013 11:21 AM, Jeremy Whiting wrote:
Hi,
I am looking for feedback on changes to provide the ability for work
to be completed in a currently running transaction. For example when a
TableGenerator or SequenceGenerator is being used for generating unique
ids. The statements that select then update the db are executed in a
separate transaction.
There is a jira for this feature.
https://hibernate.atlassian.net/browse/HHH-8429
Attached to the jira is a diagram. See this link
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
This diagram shows what I currently have implemented. It shows the
existing classes and the new classes shaded in light blue. The methods
on a new class IsolationAware show how I've re-jigged most the
implementation from JtaTransaction to it's new ancestor IsolationAware.
A new concrete implementation of IsolationDelegate will negotiate the
work to be executed in the same running transaction.
The structure splits up the factory/transaction/delegate classes into
two groups. "same transaction" and "separate transaction". This has
only
been done for JtaTransaction and the same will probably be necessary for
CMTTransaction as it also uses a separate transaction to complete work.
That has been left out to keep the diagram simple.
Your talking about making code changes here but I'm not following
exactly how this new features works. I added my questions about this to
the jira. When you respond there or here, could you please also include
how this new feature depends on isolation level (if it requires a
certain isolation level).
The option of using aggregation at the point where implementers of
TransactionImplementor are instantiated has been considered. Before too
much effort is expended coding I wondered what others thought is the
preferred way to implement this feature.
Jeremy
_______________________________________________
hibernate-dev mailing list
hibernate-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hibernate-dev
1:08 p.m.
Hi Scott,
To the database the sequence of statements will be as follows. The
statements around the read and write of sequence table are an example to
put the sequence_table work into context.
tx1 BEGIN
SELECT blah
SELECT blah
UPDATE blah
SELECT * from sequence_table;
UPDATE sequence_table SET ids=?;
INSERT INTO blah
UPDATE blah
tx1 END
tx1 COMMIT
The work will not be isolated from the current transaction tx1.
Concurrently running transactions will see the changes to sequence_table
depending on the isolation level set when the pool is filled.
Regards,
Jeremy
On 09/08/13 18:20, Scott Marlow wrote:
On 08/08/2013 11:21 AM, Jeremy Whiting wrote:
> Hi,
> I am looking for feedback on changes to provide the ability for work
> to be completed in a currently running transaction. For example when a
> TableGenerator or SequenceGenerator is being used for generating unique
> ids. The statements that select then update the db are executed in a
> separate transaction.
>
> There is a jira for this feature.
>
> https://hibernate.atlassian.net/browse/HHH-8429
>
> Attached to the jira is a diagram. See this link
>
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
>
>
> This diagram shows what I currently have implemented. It shows the
> existing classes and the new classes shaded in light blue. The methods
> on a new class IsolationAware show how I've re-jigged most the
> implementation from JtaTransaction to it's new ancestor IsolationAware.
> A new concrete implementation of IsolationDelegate will negotiate the
> work to be executed in the same running transaction.
> The structure splits up the factory/transaction/delegate classes into
> two groups. "same transaction" and "separate transaction". This
has only
> been done for JtaTransaction and the same will probably be necessary for
> CMTTransaction as it also uses a separate transaction to complete work.
> That has been left out to keep the diagram simple.
Your talking about making code changes here but I'm not following
exactly how this new features works. I added my questions about this
to the jira. When you respond there or here, could you please also
include how this new feature depends on isolation level (if it
requires a certain isolation level).
>
> The option of using aggregation at the point where implementers of
> TransactionImplementor are instantiated has been considered. Before too
> much effort is expended coding I wondered what others thought is the
> preferred way to implement this feature.
>
> Jeremy
>
> _______________________________________________
> hibernate-dev mailing list
> hibernate-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/hibernate-dev
>

6:45 a.m.
On 9 August 2013 19:08, Jeremy Whiting <jwhiting(a)redhat.com> wrote:
Hi Scott,
To the database the sequence of statements will be as follows. The
statements around the read and write of sequence table are an example to
put the sequence_table work into context.
tx1 BEGIN
SELECT blah
SELECT blah
UPDATE blah
SELECT * from sequence_table;
UPDATE sequence_table SET ids=?;
INSERT INTO blah
UPDATE blah
tx1 END
tx1 COMMIT
The work will not be isolated from the current transaction tx1.
Concurrently running transactions will see the changes to sequence_table
depending on the isolation level set when the pool is filled.
What is the use case for creating the sequence in the same transaction?
Sequences are usually needed to be absolutely independent from transactions.
That is generally the case for "real" sequence constructs:
- http://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_6015.htm
With sequence tables we're providing alternative strategies but -as a
user- I would expect these to follow the same semantic, i.e. to be
fully independent from any running transaction.
Sanne
Regards,
Jeremy
On 09/08/13 18:20, Scott Marlow wrote:
> On 08/08/2013 11:21 AM, Jeremy Whiting wrote:
>> Hi,
>> I am looking for feedback on changes to provide the ability for work
>> to be completed in a currently running transaction. For example when a
>> TableGenerator or SequenceGenerator is being used for generating unique
>> ids. The statements that select then update the db are executed in a
>> separate transaction.
>>
>> There is a jira for this feature.
>>
>> https://hibernate.atlassian.net/browse/HHH-8429
>>
>> Attached to the jira is a diagram. See this link
>>
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
>>
>>
>> This diagram shows what I currently have implemented. It shows the
>> existing classes and the new classes shaded in light blue. The methods
>> on a new class IsolationAware show how I've re-jigged most the
>> implementation from JtaTransaction to it's new ancestor IsolationAware.
>> A new concrete implementation of IsolationDelegate will negotiate the
>> work to be executed in the same running transaction.
>> The structure splits up the factory/transaction/delegate classes into
>> two groups. "same transaction" and "separate transaction".
This has only
>> been done for JtaTransaction and the same will probably be necessary for
>> CMTTransaction as it also uses a separate transaction to complete work.
>> That has been left out to keep the diagram simple.
>
> Your talking about making code changes here but I'm not following
> exactly how this new features works. I added my questions about this
> to the jira. When you respond there or here, could you please also
> include how this new feature depends on isolation level (if it
> requires a certain isolation level).
>
>>
>> The option of using aggregation at the point where implementers of
>> TransactionImplementor are instantiated has been considered. Before too
>> much effort is expended coding I wondered what others thought is the
>> preferred way to implement this feature.
>>
>> Jeremy
>>
>> _______________________________________________
>> hibernate-dev mailing list
>> hibernate-dev(a)lists.jboss.org
>> https://lists.jboss.org/mailman/listinfo/hibernate-dev
>>
>
_______________________________________________
hibernate-dev mailing list
hibernate-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hibernate-dev

8:51 p.m.
First, you lump sequences and table-based sequence together here, but I
assure you sequences (real database sequences) are read inline with the
current transaction. In the case of a real sequence, the database
already handles the isolation of the generated values outside
transactional context. When you ask the database sequence for its next
value, that value is incremented regardless of the outcome of the
transaction.
That is to say, your example "sequence of calls" is indicative of table
based generation, not at all true of sequence based generation. For the
table based generation case, I am leery of doing this for a few
reasons. First, as Sanne points out, our "sequence table" strategy is
purely meant to mimic a database sequence in terms of semantic in cases
where a sequence cannot be used.
Secondly, you request this (I believe) as a performance enhancement as a
means to work around your particular use-case which I think we can all
agree is *at best* a questionable real-life scenario. The problem with
the performance aspect is that you are trading one type of performance
concern (resource allocation) for another (blocking). That is to say,
currently you have a performance problem because accessing the database
value causes multiple discrete transactions. But what you suggest
instead is to trade off the isolation with blocking *in the same
frequency*. To illustrate, lets take a (simplified) look at 2
transactions attempting to generate an identifier from the same
"sequence table":
T1 - begin
T2 - begin
T1 - select val from seq_table for update
T2 - select val from seq_table for update
T1 - update seq_table set val = ? where val = ?
T2 - update seq_table set val = ? where val = ?
T1 - insert into my_entity ...
T2 - insert into my_entity ...
T1 - commit
T2 - commit
We can notice a few different things here. In the *best* case scenario,
T1 simply blocks T2 meaning that T1 and T2 are no longer concurrent. T1
must completely finish before T2 will be allowed to proceed; T2 will
block either on the `select for update` or on the `update`,
depending... Yes, using separate transactions for reading the "sequence
table" value still does blocking, the difference is one of scope and
therefore duration.
Seems to me, if I were you, I'd be more interested in minimizing the
number of times the database is called regardless of what happens when
the database is called...
On 08/11/2013 06:45 AM, Sanne Grinovero wrote:
On 9 August 2013 19:08, Jeremy Whiting <jwhiting(a)redhat.com>
wrote:
> Hi Scott,
> To the database the sequence of statements will be as follows. The
> statements around the read and write of sequence table are an example to
> put the sequence_table work into context.
>
> tx1 BEGIN
> SELECT blah
> SELECT blah
> UPDATE blah
> SELECT * from sequence_table;
> UPDATE sequence_table SET ids=?;
> INSERT INTO blah
> UPDATE blah
> tx1 END
> tx1 COMMIT
>
> The work will not be isolated from the current transaction tx1.
> Concurrently running transactions will see the changes to sequence_table
> depending on the isolation level set when the pool is filled.
What is the use case for creating the sequence in the same transaction?
Sequences are usually needed to be absolutely independent from transactions.
That is generally the case for "real" sequence constructs:
- http://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_6015.htm
With sequence tables we're providing alternative strategies but -as a
user- I would expect these to follow the same semantic, i.e. to be
fully independent from any running transaction.
Sanne
> Regards,
> Jeremy
>
> On 09/08/13 18:20, Scott Marlow wrote:
>> On 08/08/2013 11:21 AM, Jeremy Whiting wrote:
>>> Hi,
>>> I am looking for feedback on changes to provide the ability for work
>>> to be completed in a currently running transaction. For example when a
>>> TableGenerator or SequenceGenerator is being used for generating unique
>>> ids. The statements that select then update the db are executed in a
>>> separate transaction.
>>>
>>> There is a jira for this feature.
>>>
>>> https://hibernate.atlassian.net/browse/HHH-8429
>>>
>>> Attached to the jira is a diagram. See this link
>>>
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
>>>
>>>
>>> This diagram shows what I currently have implemented. It shows the
>>> existing classes and the new classes shaded in light blue. The methods
>>> on a new class IsolationAware show how I've re-jigged most the
>>> implementation from JtaTransaction to it's new ancestor IsolationAware.
>>> A new concrete implementation of IsolationDelegate will negotiate the
>>> work to be executed in the same running transaction.
>>> The structure splits up the factory/transaction/delegate classes into
>>> two groups. "same transaction" and "separate
transaction". This has only
>>> been done for JtaTransaction and the same will probably be necessary for
>>> CMTTransaction as it also uses a separate transaction to complete work.
>>> That has been left out to keep the diagram simple.
>> Your talking about making code changes here but I'm not following
>> exactly how this new features works. I added my questions about this
>> to the jira. When you respond there or here, could you please also
>> include how this new feature depends on isolation level (if it
>> requires a certain isolation level).
>>
>>> The option of using aggregation at the point where implementers of
>>> TransactionImplementor are instantiated has been considered. Before too
>>> much effort is expended coding I wondered what others thought is the
>>> preferred way to implement this feature.
>>>
>>> Jeremy
>>>
>>> _______________________________________________
>>> hibernate-dev mailing list
>>> hibernate-dev(a)lists.jboss.org
>>> https://lists.jboss.org/mailman/listinfo/hibernate-dev
>>>
> _______________________________________________
> hibernate-dev mailing list
> hibernate-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/hibernate-dev
_______________________________________________
hibernate-dev mailing list
hibernate-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hibernate-dev
8:17 a.m.
On 12/08/13 02:51, Steve Ebersole wrote:
First, you lump sequences and table-based sequence together here, but
I
assure you sequences (real database sequences) are read inline with the
current transaction. In the case of a real sequence, the database
already handles the isolation of the generated values outside
transactional context. When you ask the database sequence for its next
value, that value is incremented regardless of the outcome of the
transaction.
That is to say, your example "sequence of calls" is indicative of table
based generation, not at all true of sequence based generation. For the
table based generation case, I am leery of doing this for a few
reasons. First, as Sanne points out, our "sequence table" strategy is
purely meant to mimic a database sequence in terms of semantic in cases
where a sequence cannot be used.
Yes the table based generation is a simulation of
sequence generation
using sequences. You are right they should not be lumped together.
Secondly, you request this (I believe) as a performance enhancement
as a
means to work around your particular use-case which I think we can all
agree is *at best* a questionable real-life scenario.
The requirement to reduce
the number of transactions where possible is
real for my team and not unrealistic for general purpose applications.
The problem with
the performance aspect is that you are trading one type of performance
concern (resource allocation) for another (blocking). That is to say,
currently you have a performance problem because accessing the database
value causes multiple discrete transactions. But what you suggest
instead is to trade off the isolation with blocking *in the same
frequency*.
It is a trade off of not only isolation but also the associated
overhead of creating an additional transaction on the database. That
being the overhead of additional disk syncs and memory allocation for
crash recovery by the database. All to support the simulation of a
sequence increment being isolated.
Also this is weighed up against using pessimistic locking to control
the modification of the table used in the table based sequence
generating technique. But the database calls do not necessarily have to
use pessimistic locking. Discussing optimistic locking is hypothetical
at the moment because Hibernate only offers pessimistic locking in a
table based sequence generator. Correct me if I am wrong.
https://github.com/whitingjr/hibernate-orm/blob/master/hibernate-core/src...
If Hibernate were to offer optimistic locking that can be used
effectively with an application that has been coded to replay it's
behaviour when an OptimisticLockException (OLE) is caught. That will
reduce the problem of blocking on application concurrency. The frequency
of OLE can be minimised to an acceptable level by performance tuning.
To illustrate, lets take a (simplified) look at 2
transactions attempting to generate an identifier from the same
"sequence table":
T1 - begin
T2 - begin
T1 - select val from seq_table for update
T2 - select val from seq_table for update
T1 - update seq_table set val = ? where val = ?
T2 - update seq_table set val = ? where val = ?
T1 - insert into my_entity ...
T2 - insert into my_entity ...
T1 - commit
T2 - commit
We can notice a few different things here. In the *best* case scenario,
T1 simply blocks T2 meaning that T1 and T2 are no longer concurrent. T1
must completely finish before T2 will be allowed to proceed; T2 will
block either on the `select for update` or on the `update`,
depending... Yes, using separate transactions for reading the "sequence
table" value still does blocking, the difference is one of scope and
therefore duration.
Seems to me, if I were you, I'd be more interested in minimizing the
number of times the database is called regardless of what happens when
the database is called...
We have been tasked with identifying where optimizations
can be made.
We are trying to achieve exactly as you suggest by minimising the number
of times the database is called. Which currently (tx BEGIN,tx END) are
expensive file system sync operations.
I think applications that have been written to accommodate situations
of OLE by replaying the business operation can take advantage of this
alternative sequence generating technique. It will remove the need to
create a simulated scenario that was only necessary for a database
sequence that isn't even being used in this particular situation.
I think the tradeoff is the frequency 0 or n times of sequence
incrementing OLE versus the frequency n of incrementing the sequence
table in a separate transaction during runtime. Both can be managed by
tuning.
Regards,
Jeremy
On 08/11/2013 06:45 AM, Sanne Grinovero wrote:
> On 9 August 2013 19:08, Jeremy Whiting <jwhiting(a)redhat.com> wrote:
>> Hi Scott,
>> To the database the sequence of statements will be as follows. The
>> statements around the read and write of sequence table are an example to
>> put the sequence_table work into context.
>>
>> tx1 BEGIN
>> SELECT blah
>> SELECT blah
>> UPDATE blah
>> SELECT * from sequence_table;
>> UPDATE sequence_table SET ids=?;
>> INSERT INTO blah
>> UPDATE blah
>> tx1 END
>> tx1 COMMIT
>>
>> The work will not be isolated from the current transaction tx1.
>> Concurrently running transactions will see the changes to sequence_table
>> depending on the isolation level set when the pool is filled.
> What is the use case for creating the sequence in the same transaction?
> Sequences are usually needed to be absolutely independent from transactions.
> That is generally the case for "real" sequence constructs:
> - http://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_6015.htm
>
> With sequence tables we're providing alternative strategies but -as a
> user- I would expect these to follow the same semantic, i.e. to be
> fully independent from any running transaction.
>
> Sanne
>
>
>
>> Regards,
>> Jeremy
>>
>> On 09/08/13 18:20, Scott Marlow wrote:
>>> On 08/08/2013 11:21 AM, Jeremy Whiting wrote:
>>>> Hi,
>>>> I am looking for feedback on changes to provide the ability for work
>>>> to be completed in a currently running transaction. For example when a
>>>> TableGenerator or SequenceGenerator is being used for generating unique
>>>> ids. The statements that select then update the db are executed in a
>>>> separate transaction.
>>>>
>>>> There is a jira for this feature.
>>>>
>>>> https://hibernate.atlassian.net/browse/HHH-8429
>>>>
>>>> Attached to the jira is a diagram. See this link
>>>>
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
>>>>
>>>>
>>>> This diagram shows what I currently have implemented. It shows the
>>>> existing classes and the new classes shaded in light blue. The methods
>>>> on a new class IsolationAware show how I've re-jigged most the
>>>> implementation from JtaTransaction to it's new ancestor
IsolationAware.
>>>> A new concrete implementation of IsolationDelegate will negotiate the
>>>> work to be executed in the same running transaction.
>>>> The structure splits up the factory/transaction/delegate classes
into
>>>> two groups. "same transaction" and "separate
transaction". This has only
>>>> been done for JtaTransaction and the same will probably be necessary for
>>>> CMTTransaction as it also uses a separate transaction to complete work.
>>>> That has been left out to keep the diagram simple.
>>> Your talking about making code changes here but I'm not following
>>> exactly how this new features works. I added my questions about this
>>> to the jira. When you respond there or here, could you please also
>>> include how this new feature depends on isolation level (if it
>>> requires a certain isolation level).
>>>
>>>> The option of using aggregation at the point where implementers of
>>>> TransactionImplementor are instantiated has been considered. Before too
>>>> much effort is expended coding I wondered what others thought is the
>>>> preferred way to implement this feature.
>>>>
>>>> Jeremy
>>>>
>>>> _______________________________________________
>>>> hibernate-dev mailing list
>>>> hibernate-dev(a)lists.jboss.org
>>>> https://lists.jboss.org/mailman/listinfo/hibernate-dev
>>>>
>> _______________________________________________
>> hibernate-dev mailing list
>> hibernate-dev(a)lists.jboss.org
>> https://lists.jboss.org/mailman/listinfo/hibernate-dev
> _______________________________________________
> hibernate-dev mailing list
> hibernate-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/hibernate-dev
_______________________________________________
hibernate-dev mailing list
hibernate-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hibernate-dev
--
Jeremy Whiting
Senior Software Engineer, Performance Team
Red Hat
------------------------------------------------------------
Registered Address: Red Hat UK Ltd, 64 Baker Street, 4th Floor, London. W1U 7DF. United
Kingdom.
Registered in England and Wales under Company Registration No. 03798903. Directors:
Michael Cunningham (USA), Mark Hegarty (Ireland), Matt Parson (USA), Charlie Peters (USA)
6:31 a.m.
Hi Steve,
Since my last response I have gone back to the drawing board to
re-evaluate and test the proposed change. In brief the change does
inline the sql in the current transaction and uses pessimistic locking.
This is a change to the initial ideas suggested. Reasons for that are
later in the response.
Comments in-line....
On 12/08/13 02:51, Steve Ebersole wrote:
First, you lump sequences and table-based sequence together here, but
I
assure you sequences (real database sequences) are read inline with the
current transaction. In the case of a real sequence, the database
already handles the isolation of the generated values outside
transactional context. When you ask the database sequence for its next
value, that value is incremented regardless of the outcome of the
transaction.
That is to say, your example "sequence of calls" is indicative of table
based generation, not at all true of sequence based generation. For the
table based generation case, I am leery of doing this for a few
reasons. First, as Sanne points out, our "sequence table" strategy is
purely meant to mimic a database sequence in terms of semantic in cases
where a sequence cannot be used.
Yes table based generation.
Secondly, you request this (I believe) as a performance enhancement
as a
means to work around your particular use-case which I think we can all
agree is *at best* a questionable real-life scenario. The problem with
the performance aspect is that you are trading one type of performance
concern (resource allocation) for another (blocking). That is to say,
currently you have a performance problem because accessing the database
value causes multiple discrete transactions. But what you suggest
instead is to trade off the isolation with blocking *in the same
frequency*. To illustrate, lets take a (simplified) look at 2
transactions attempting to generate an identifier from the same
"sequence table":
T1 - begin
T2 - begin
T1 - select val from seq_table for update
T2 - select val from seq_table for update
T1 - update seq_table set val = ? where val = ?
T2 - update seq_table set val = ? where val = ?
T1 - insert into my_entity ...
T2 - insert into my_entity ...
T1 - commit
T2 - commit
We can notice a few different things here. In the *best* case scenario,
T1 simply blocks T2 meaning that T1 and T2 are no longer concurrent. T1
must completely finish before T2 will be allowed to proceed; T2 will
block either on the `select for update` or on the `update`,
depending... Yes, using separate transactions for reading the "sequence
table" value still does blocking, the difference is one of scope and
therefore duration.
Yes I agree exactly this is what will happen. The tradeoff
relies on
the blocking of concurrent threads till T1 terminates.
Testing of the application I am using has shown an improvement in
response times. 5 graphs are shown. Scale excluded. The blue orange and
yellow (1st three) bars show results using an isolated transaction and
the green, brown and light blue (last three) show the inlined sql. See
the attached pdf to the HHH-8429
https://hibernate.atlassian.net/browse/HHH-8429
It shows the response time is improved most of the time or is equal.
Shorter bars is better btw.
Seems to me, if I were you, I'd be more interested in minimizing
the
number of times the database is called regardless of what happens when
the database is called...
I think by inlining the sql the system reduces the
number of calls by
three. To fetch the next block of ids. 3 being to manage the isolated
concurrent transaction.
The proposed idea for using optimistic locking was proved in testing
to be too buggy. Scott's question in the jira demonstrates the issue. In
my testing concurrent transactions did end up competing.
On 08/11/2013 06:45 AM, Sanne Grinovero wrote:
> On 9 August 2013 19:08, Jeremy Whiting <jwhiting(a)redhat.com> wrote:
>> Hi Scott,
>> To the database the sequence of statements will be as follows. The
>> statements around the read and write of sequence table are an example to
>> put the sequence_table work into context.
>>
>> tx1 BEGIN
>> SELECT blah
>> SELECT blah
>> UPDATE blah
>> SELECT * from sequence_table;
>> UPDATE sequence_table SET ids=?;
>> INSERT INTO blah
>> UPDATE blah
>> tx1 END
>> tx1 COMMIT
>>
>> The work will not be isolated from the current transaction tx1.
>> Concurrently running transactions will see the changes to sequence_table
>> depending on the isolation level set when the pool is filled.
> What is the use case for creating the sequence in the same transaction?
> Sequences are usually needed to be absolutely independent from transactions.
> That is generally the case for "real" sequence constructs:
> - http://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_6015.htm
>
> With sequence tables we're providing alternative strategies but -as a
> user- I would expect these to follow the same semantic, i.e. to be
> fully independent from any running transaction.
>
> Sanne
>
>
>
>> Regards,
>> Jeremy
>>
>> On 09/08/13 18:20, Scott Marlow wrote:
>>> On 08/08/2013 11:21 AM, Jeremy Whiting wrote:
>>>> Hi,
>>>> I am looking for feedback on changes to provide the ability for
work
>>>> to be completed in a currently running transaction. For example when a
>>>> TableGenerator or SequenceGenerator is being used for generating unique
>>>> ids. The statements that select then update the db are executed in a
>>>> separate transaction.
>>>>
>>>> There is a jira for this feature.
>>>>
>>>> https://hibernate.atlassian.net/browse/HHH-8429
>>>>
>>>> Attached to the jira is a diagram. See this link
>>>>
https://hibernate.atlassian.net/secure/attachment/19534/hibernate-class-s...
>>>>
>>>>
>>>> This diagram shows what I currently have implemented. It shows the
>>>> existing classes and the new classes shaded in light blue. The methods
>>>> on a new class IsolationAware show how I've re-jigged most the
>>>> implementation from JtaTransaction to it's new ancestor
IsolationAware.
>>>> A new concrete implementation of IsolationDelegate will negotiate the
>>>> work to be executed in the same running transaction.
>>>> The structure splits up the factory/transaction/delegate classes
into
>>>> two groups. "same transaction" and "separate
transaction". This has only
>>>> been done for JtaTransaction and the same will probably be necessary for
>>>> CMTTransaction as it also uses a separate transaction to complete work.
>>>> That has been left out to keep the diagram simple.
>>> Your talking about making code changes here but I'm not following
>>> exactly how this new features works. I added my questions about this
>>> to the jira. When you respond there or here, could you please also
>>> include how this new feature depends on isolation level (if it
>>> requires a certain isolation level).
>>>
>>>> The option of using aggregation at the point where implementers of
>>>> TransactionImplementor are instantiated has been considered. Before too
>>>> much effort is expended coding I wondered what others thought is the
>>>> preferred way to implement this feature.
>>>>
>>>> Jeremy
>>>>
>>>> _______________________________________________
>>>> hibernate-dev mailing list
>>>> hibernate-dev(a)lists.jboss.org
>>>> https://lists.jboss.org/mailman/listinfo/hibernate-dev
>>>>
>> _______________________________________________
>> hibernate-dev mailing list
>> hibernate-dev(a)lists.jboss.org
>> https://lists.jboss.org/mailman/listinfo/hibernate-dev
> _______________________________________________
> hibernate-dev mailing list
> hibernate-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/hibernate-dev
_______________________________________________
hibernate-dev mailing list
hibernate-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/hibernate-dev
4592
days inactive
4620
days old
6 comments
4 participants
participants (4)
-
 Jeremy Whiting
Jeremy Whiting -
 Sanne Grinovero
Sanne Grinovero -
 Scott Marlow
Scott Marlow -
 Steve Ebersole
Steve Ebersole