
10:38 a.m.
Hey guys,
TL;DR: there are ways how to make the memory footprint of Differential
Synchronization (DS) very low; if we assume that JSON patches are
reversible and we create cumulative patches from series of individual
patches, we can use (smart, garbage-collactable) revision control for
storage of documents that server need to maintain.
----
I had an idea in my head that for couple of days as I was becoming familiar
with how Differential Synchronization (DS) works and studying Dan's and
Luke's impl.
I share the concern that Randall expressed in earlier thread - the DS in
its pure version doesn't scale for huge amount of users when connected to
one server.
Sure, the algorithm can be scaled trivially by adding new nodes that uses
very same algorithm as is used for client<->server. But that doesn't mean
it is something that we should do regularly to get more memory available.
Instead, I was thinking about limiting a memory that server needs to
maintain in any point in time.
In pure DS, server have to maintain all copies of documents that clients
ever requested. Even worse, it has to maintain two copies - "shadow" and
"backup",
So, in worst case, 2 x N copies of document will be maintained by the
server for N clients.
-----
The DS algorithm doesn't tell us how the "shadow" and "backup"
documents
should be stored.
We can transparently plug in a storage that will be clever about how to use
"backups" and "shadow".
-----
CONCEPTS:
1) REVISION CONTROL
In order to limit a number of documents we need to maintain in server's
memory, we can come with a system where just last known state is remembered
in full version. Together with last known version, we remember also history
of the document for each revision as it was patched by clients.
But server doesn't have to maintain full history of the document, it
maintains just revisions that are known to its clients (that revision is
known by DS for each client out of the box).
2) GARBAGE COLLECTION
Server trivially knows what versions are mantained by client, so it can get
rid of those revisions that are no longer needed.
First, it can cut all the history that is older than the oldest version of
document throughout all its clients.
Secondly, it can accumulate the serious of patches between states so that
it doesn't have to maintain full history, but just revisions that is known
to any of those clients.
----
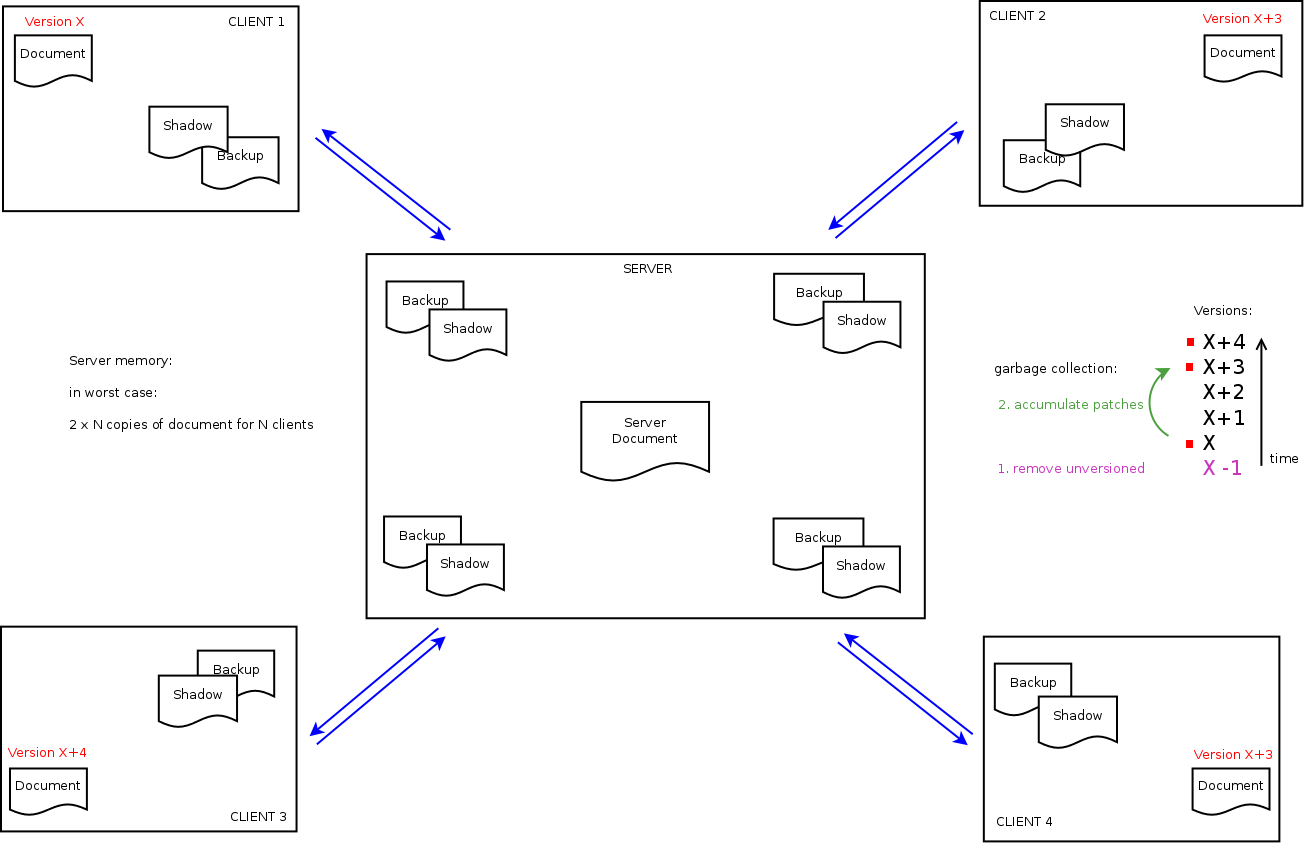
DIAGRAM:
I've attached a picture for illustration of the revision control / garbage
collection, it does not illustrate algorithm itself (Dan did awesome job
describing DS here [3]).
In the attached diagram, you can see four clients with different revisions:
Client 1: revision X
Client 2: revision X+3
Client 3: revision X+3
Client 4: revision X+4
If any of the clients reaches server, server can reconstruct the document
(shadow and backup) for given client revision and the DS algorithm then can
operate as normally (that's why it is transparent from algorithmic point of
view).
If server comes to garbage collection, it can scan through available client
revisions. As it identifies, that the oldest known revision is X, it can
remove patch for X-1 and less as they are no longer needed.
Later, it can even more optimize, and accumulate patches so that the only
information he knows is how to get to the revision for each participating
client. In the picture, he can compute cumulative patch for getting from
state X to state X+3, as X+1 and X+2 themselves are not needed.
(Patch accumulation is actually something that Google Wave does in its
Operational Transformation implementation, just there it is called
cumulative Operations).
----
Then it comes to caching strategies, you can maintain caches of things like
last recently used revisions (they don't need to be computed each time).
You can store some documents and their revision history to the disk (fully
or partially), etc.
----
THE USE CASE:
1000 employees maintain one document - Contact List - on their smartphones
400 of those employees has mobile data plan, so they want to synchronize
almost immediately as they are notified about changes. The rest of the
devices is connected rather sparely.
If one employee changes data, 600 devices are notified about the change
immediately (some on data plan, some through Wifi, etc.) Those clients all
have version say X+3, because they are synchronized proactively.
These clients reach the server in say <10 seconds after that employee did
the change.
First client reaches server and ask for version X+3 (it probably is still
in the memory, but if it isn't, it is deconstructed and placed into MRU
cache). All of the others reaches the server and re-synchronize themselves
against the one copy of backup/shadow that is in the memory already.
The other clients will reach the server later, as they are connecting to
Wifi, say in 5 minutes to 24 hours. They will have even older versions,
such as X. Those clients will require more computation, but at the end the
server can resolve them and through their revisions out of the window.
At the end, there are clients that didn't connected for days, maybe months
- I suggest we don't actually use DS here and fallback to e.g. slow
synchronization (show me what you have, I will show you mine), because
maintaining full history for longer period of days may be too resource
demanding (configurable?).
Obviously, 1000 is not much, but this can scale to pretty decent numbers if
we use hybrid approach (fallback to other sync strategies if revision is
already forgotten by a server).
----
WORST CASE:
we still have to maintain all the document revisions, but practically it
won't happen :-)
----
ASSUMPTIONS:
1. patches are reversible (we are able to compute reverse patch for each
patch sent by client)
2. patches are cumulative (we are able to compute aggregated patch from
series of patches)
For 1, it seems many of JSON-patch libraries actually implement it (Java,
JavaScript) [1, 2]
For 2, it again seems some libraries implement it and if not, we can
implement it or even use brute-force - compute a patch between two documents
----
It's not the only way how to make it scale, but it does solve the problem
pretty independently of the DS algorithm and still leaves the algorithm
clean and simple.
Cheers,
~ Lukas
[1] https://github.com/fge/json-patch
[2] https://github.com/benjamine/jsondiffpatch
{kind=link}