
10:38 a.m.
Hey guys,
TL;DR: there are ways how to make the memory footprint of Differential
Synchronization (DS) very low; if we assume that JSON patches are
reversible and we create cumulative patches from series of individual
patches, we can use (smart, garbage-collactable) revision control for
storage of documents that server need to maintain.
----
I had an idea in my head that for couple of days as I was becoming familiar
with how Differential Synchronization (DS) works and studying Dan's and
Luke's impl.
I share the concern that Randall expressed in earlier thread - the DS in
its pure version doesn't scale for huge amount of users when connected to
one server.
Sure, the algorithm can be scaled trivially by adding new nodes that uses
very same algorithm as is used for client<->server. But that doesn't mean
it is something that we should do regularly to get more memory available.
Instead, I was thinking about limiting a memory that server needs to
maintain in any point in time.
In pure DS, server have to maintain all copies of documents that clients
ever requested. Even worse, it has to maintain two copies - "shadow" and
"backup",
So, in worst case, 2 x N copies of document will be maintained by the
server for N clients.
-----
The DS algorithm doesn't tell us how the "shadow" and "backup"
documents
should be stored.
We can transparently plug in a storage that will be clever about how to use
"backups" and "shadow".
-----
CONCEPTS:
1) REVISION CONTROL
In order to limit a number of documents we need to maintain in server's
memory, we can come with a system where just last known state is remembered
in full version. Together with last known version, we remember also history
of the document for each revision as it was patched by clients.
But server doesn't have to maintain full history of the document, it
maintains just revisions that are known to its clients (that revision is
known by DS for each client out of the box).
2) GARBAGE COLLECTION
Server trivially knows what versions are mantained by client, so it can get
rid of those revisions that are no longer needed.
First, it can cut all the history that is older than the oldest version of
document throughout all its clients.
Secondly, it can accumulate the serious of patches between states so that
it doesn't have to maintain full history, but just revisions that is known
to any of those clients.
----
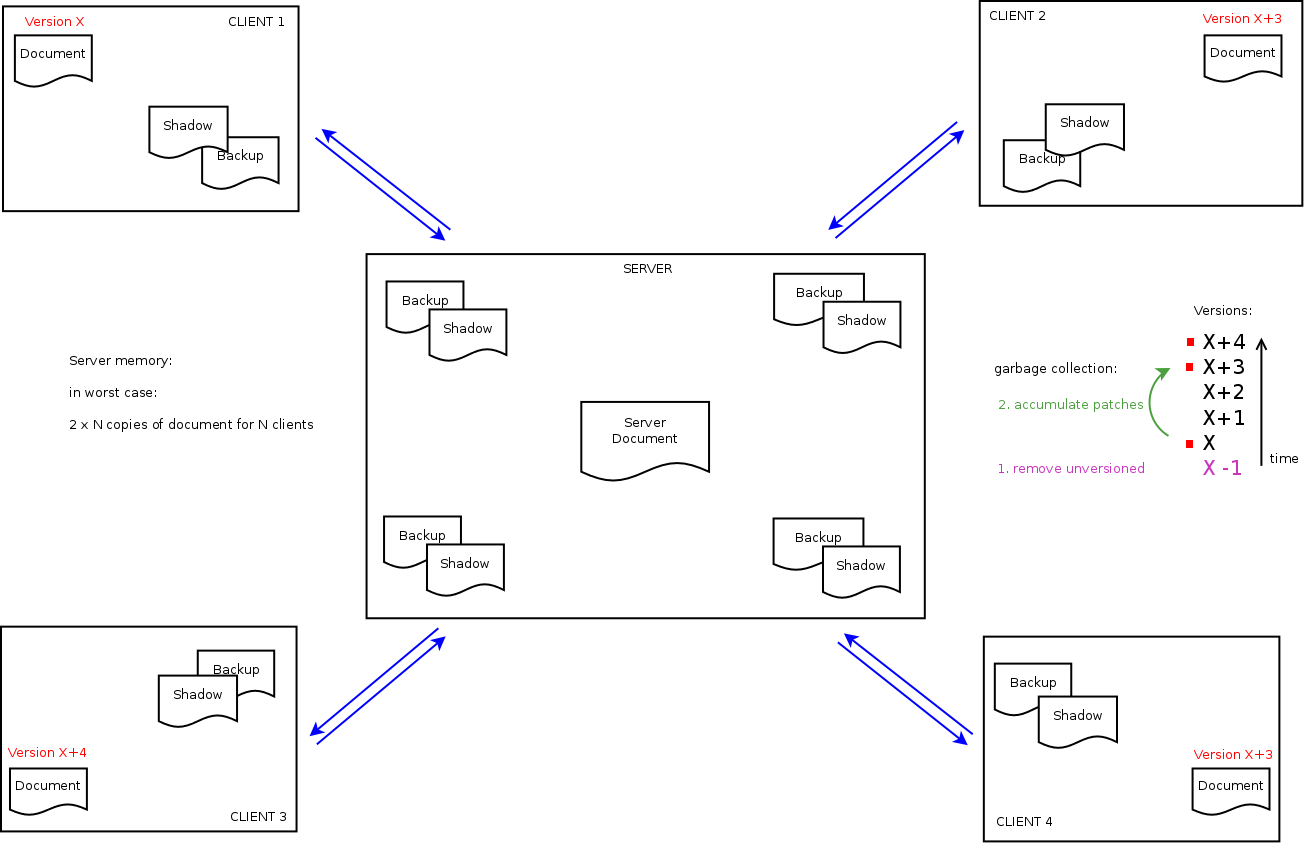
DIAGRAM:
I've attached a picture for illustration of the revision control / garbage
collection, it does not illustrate algorithm itself (Dan did awesome job
describing DS here [3]).
In the attached diagram, you can see four clients with different revisions:
Client 1: revision X
Client 2: revision X+3
Client 3: revision X+3
Client 4: revision X+4
If any of the clients reaches server, server can reconstruct the document
(shadow and backup) for given client revision and the DS algorithm then can
operate as normally (that's why it is transparent from algorithmic point of
view).
If server comes to garbage collection, it can scan through available client
revisions. As it identifies, that the oldest known revision is X, it can
remove patch for X-1 and less as they are no longer needed.
Later, it can even more optimize, and accumulate patches so that the only
information he knows is how to get to the revision for each participating
client. In the picture, he can compute cumulative patch for getting from
state X to state X+3, as X+1 and X+2 themselves are not needed.
(Patch accumulation is actually something that Google Wave does in its
Operational Transformation implementation, just there it is called
cumulative Operations).
----
Then it comes to caching strategies, you can maintain caches of things like
last recently used revisions (they don't need to be computed each time).
You can store some documents and their revision history to the disk (fully
or partially), etc.
----
THE USE CASE:
1000 employees maintain one document - Contact List - on their smartphones
400 of those employees has mobile data plan, so they want to synchronize
almost immediately as they are notified about changes. The rest of the
devices is connected rather sparely.
If one employee changes data, 600 devices are notified about the change
immediately (some on data plan, some through Wifi, etc.) Those clients all
have version say X+3, because they are synchronized proactively.
These clients reach the server in say <10 seconds after that employee did
the change.
First client reaches server and ask for version X+3 (it probably is still
in the memory, but if it isn't, it is deconstructed and placed into MRU
cache). All of the others reaches the server and re-synchronize themselves
against the one copy of backup/shadow that is in the memory already.
The other clients will reach the server later, as they are connecting to
Wifi, say in 5 minutes to 24 hours. They will have even older versions,
such as X. Those clients will require more computation, but at the end the
server can resolve them and through their revisions out of the window.
At the end, there are clients that didn't connected for days, maybe months
- I suggest we don't actually use DS here and fallback to e.g. slow
synchronization (show me what you have, I will show you mine), because
maintaining full history for longer period of days may be too resource
demanding (configurable?).
Obviously, 1000 is not much, but this can scale to pretty decent numbers if
we use hybrid approach (fallback to other sync strategies if revision is
already forgotten by a server).
----
WORST CASE:
we still have to maintain all the document revisions, but practically it
won't happen :-)
----
ASSUMPTIONS:
1. patches are reversible (we are able to compute reverse patch for each
patch sent by client)
2. patches are cumulative (we are able to compute aggregated patch from
series of patches)
For 1, it seems many of JSON-patch libraries actually implement it (Java,
JavaScript) [1, 2]
For 2, it again seems some libraries implement it and if not, we can
implement it or even use brute-force - compute a patch between two documents
----
It's not the only way how to make it scale, but it does solve the problem
pretty independently of the DS algorithm and still leaves the algorithm
clean and simple.
Cheers,
~ Lukas
[1] https://github.com/fge/json-patch
[2] https://github.com/benjamine/jsondiffpatch
{kind=link}

3:47 a.m.
I like the idea and anything that we can do to reduce the memory footprint
is great. I think this is worth investigating further and trying it out in
practice.
Thanks for the detailed description Lukas!
On 4 September 2014 17:38, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
Hey guys,
TL;DR: there are ways how to make the memory footprint of Differential
Synchronization (DS) very low; if we assume that JSON patches are
reversible and we create cumulative patches from series of individual
patches, we can use (smart, garbage-collactable) revision control for
storage of documents that server need to maintain.
----
I had an idea in my head that for couple of days as I was becoming
familiar with how Differential Synchronization (DS) works and studying
Dan's and Luke's impl.
I share the concern that Randall expressed in earlier thread - the DS in
its pure version doesn't scale for huge amount of users when connected to
one server.
Sure, the algorithm can be scaled trivially by adding new nodes that uses
very same algorithm as is used for client<->server. But that doesn't mean
it is something that we should do regularly to get more memory available.
Instead, I was thinking about limiting a memory that server needs to
maintain in any point in time.
In pure DS, server have to maintain all copies of documents that clients
ever requested. Even worse, it has to maintain two copies - "shadow" and
"backup",
So, in worst case, 2 x N copies of document will be maintained by the
server for N clients.
-----
The DS algorithm doesn't tell us how the "shadow" and "backup"
documents
should be stored.
We can transparently plug in a storage that will be clever about how to
use "backups" and "shadow".
-----
CONCEPTS:
1) REVISION CONTROL
In order to limit a number of documents we need to maintain in server's
memory, we can come with a system where just last known state is remembered
in full version. Together with last known version, we remember also history
of the document for each revision as it was patched by clients.
But server doesn't have to maintain full history of the document, it
maintains just revisions that are known to its clients (that revision is
known by DS for each client out of the box).
2) GARBAGE COLLECTION
Server trivially knows what versions are mantained by client, so it can
get rid of those revisions that are no longer needed.
First, it can cut all the history that is older than the oldest version of
document throughout all its clients.
Secondly, it can accumulate the serious of patches between states so that
it doesn't have to maintain full history, but just revisions that is known
to any of those clients.
----
DIAGRAM:
I've attached a picture for illustration of the revision control / garbage
collection, it does not illustrate algorithm itself (Dan did awesome job
describing DS here [3]).
In the attached diagram, you can see four clients with different revisions:
Client 1: revision X
Client 2: revision X+3
Client 3: revision X+3
Client 4: revision X+4
If any of the clients reaches server, server can reconstruct the document
(shadow and backup) for given client revision and the DS algorithm then can
operate as normally (that's why it is transparent from algorithmic point of
view).
If server comes to garbage collection, it can scan through available
client revisions. As it identifies, that the oldest known revision is X, it
can remove patch for X-1 and less as they are no longer needed.
Later, it can even more optimize, and accumulate patches so that the only
information he knows is how to get to the revision for each participating
client. In the picture, he can compute cumulative patch for getting from
state X to state X+3, as X+1 and X+2 themselves are not needed.
(Patch accumulation is actually something that Google Wave does in its
Operational Transformation implementation, just there it is called
cumulative Operations).
----
Then it comes to caching strategies, you can maintain caches of things
like last recently used revisions (they don't need to be computed each
time). You can store some documents and their revision history to the disk
(fully or partially), etc.
----
THE USE CASE:
1000 employees maintain one document - Contact List - on their smartphones
400 of those employees has mobile data plan, so they want to synchronize
almost immediately as they are notified about changes. The rest of the
devices is connected rather sparely.
If one employee changes data, 600 devices are notified about the change
immediately (some on data plan, some through Wifi, etc.) Those clients all
have version say X+3, because they are synchronized proactively.
These clients reach the server in say <10 seconds after that employee did
the change.
First client reaches server and ask for version X+3 (it probably is still
in the memory, but if it isn't, it is deconstructed and placed into MRU
cache). All of the others reaches the server and re-synchronize themselves
against the one copy of backup/shadow that is in the memory already.
The other clients will reach the server later, as they are connecting to
Wifi, say in 5 minutes to 24 hours. They will have even older versions,
such as X. Those clients will require more computation, but at the end the
server can resolve them and through their revisions out of the window.
At the end, there are clients that didn't connected for days, maybe months
- I suggest we don't actually use DS here and fallback to e.g. slow
synchronization (show me what you have, I will show you mine), because
maintaining full history for longer period of days may be too resource
demanding (configurable?).
Obviously, 1000 is not much, but this can scale to pretty decent numbers
if we use hybrid approach (fallback to other sync strategies if revision is
already forgotten by a server).
----
WORST CASE:
we still have to maintain all the document revisions, but practically it
won't happen :-)
----
ASSUMPTIONS:
1. patches are reversible (we are able to compute reverse patch for each
patch sent by client)
2. patches are cumulative (we are able to compute aggregated patch from
series of patches)
For 1, it seems many of JSON-patch libraries actually implement it (Java,
JavaScript) [1, 2]
For 2, it again seems some libraries implement it and if not, we can
implement it or even use brute-force - compute a patch between two documents
----
It's not the only way how to make it scale, but it does solve the problem
pretty independently of the DS algorithm and still leaves the algorithm
clean and simple.
Cheers,
~ Lukas
[1] https://github.com/fge/json-patch
[2] https://github.com/benjamine/jsondiffpatch
_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev

1:32 p.m.
This does sounds quite interesting, Lukáš. If AeroGear uses Differential Synchronization,
this approach might make it more efficient for the server to implement the behavior.
But I’m still bothered by the thought that AeroGear’s Data Sync feature uses any algorithm
that requires the server to maintain client-specific state.
First of all, servers that maintain no client state across requests will *always* scale
much better than servers that maintain client-specific state across requests. Maintaining
client-specific state requires extra work, consumes more memory, and complicates
clustering, failover, and fault tolerance.
Secondly, if a server is maintaining client-specific state, how long does that client
state have to be maintained before assuming the client is no longer there? What happens
when a client on a mobile device loses its connection for a short period of time and then
reconnects? What if load balancing cause the client to reconnect to a different process in
the cluster? Bottom line is that it adds quite a bit of complexity.
Finally, I completely understand the benefits of using Differential Synchronization where
many clients are collaborating on a single document. That’s the “collaborative editor”
scenario, and surely there are apps that need this functionality. I’m just not convinced
that this is the most common use case. In fact, I think it’s relatively uncommon, and I
don’t think LiveOak will support it in the near term. (BTW, please tell me if the whole
purpose of AeroGear's Data Sync feature is to satisfy this and only this scenario. If
so, then I apologize for being a distraction.)
My understanding of the Data Sync feature, though, is that it is should be applicable to
other scenarios. IMO, the far more common scenario is:
The server manages (many) millions of small entities, each of which is a domain-specific
aggregate JSON document. Examples of different kinds of entities include: customers,
books, insurance claims, catalog items, restaurants, purchases, tasks, etc. A single
customer entity would aggregate most/all the information about the customer, including the
name, phone numbers, addresses, profile information, domain-specific privileges (e.g.,
authorized to log issues or call support), etc. Note that these aggregate entities do not
correspond to the entities in a traditional RDBMS/JPA/Hibernate app, where you’d have much
finer-grained records (separate tables for customer, customer addresses, customer phone
numbers, customer privileges, etc.).
At any point in time there may be 1Ks or 10Ks of clients reading dozens of
documents/entities and sending changes to some of them (likely in batch operations). IOW,
any one document might be concurrently modified by a relatively small number of clients.
I think it’s possible to support Data Sync in this scenario while maintaining no
client-specific state on the server (other than while processing a single request).
The Data Sync functionality of the SDK used in the clients would work with local
persistence and enable the app to function online or offline. This includes making it
possible to edit entities and create new entities while offline, though it does not matter
to Data Sync which subset of entities is persisted locally. If the client goes offline and
then back online, the Data Sync functionality in the SDK would figure out which of the
local entities the client has changed, and request from the server the latest revisions
for each of them. Data Sync then merges the local changes onto the latest revisions
(perhaps asking the user to manually resolve anything that cannot be automatically
resolved), computes the new effective changes, and then sends a single batch request to
the server to apply them. Some, all or none changes are accepted, and likely the
application then has to decide whether to continue the process again, revert to the
server’s versions, etc. (The SDK would also make use of subscriptions/notifications so
that it can be told immediately when entities are changed.)
What the batch operations entail is dependent upon the needs of the client app and
capabilities of the server. If a server supports batch operations that contain the entire
entity, then the server will almost certainly need to put revision identifiers in each
entity sent to the client, so that when the client sends back a modified representation
entity, the server can tell whether that document has since been modified by another
client. If so, the server might rely upon client preferences (see below) to know whether
to merge the changes (using a simple algorithm or more useful application-specific logic),
overwrite, or fail to update the entity.
On the other hand, the server might support batch operations with partial updates, where
the client only sends for each entity only the set of fields that are to be changed or
removed. Conflicts and merging with this approach are easier and less-likely to be
application specific, though client preferences (see below) might still dictate whether or
not to merge based upon revision numbers. It also might make it easier for Data Sync,
since the SDK simply has to record for each modified entity only those modified fields (no
matter how long the client was offline). To keep the SDK simple, a best practice might be
to ensure clients always modify together those fields that must be consistent. For
example, in a contacts application, if a user modifies the first name of a contact, the
app might tell the SDK to modify the first name and last name fields, even though the user
didn’t modify the last name. When synchronized, both the first name and last name fields
would be sent to the server as a single update. This helps ensure that even when multiple
clients are concurrently updating the same set of fields to different values, the result
of applying all of those changes will exactly match the state as set by one of the
clients.
It’s also likely that for batch operations to work well for many different kinds of
applications, the server may support multiple policies that specify for a given batch
operation the atomicity, consistency, and isolation guarantees. One policy might ensure
that the entire batch either completely succeeds only when there are no revision
conflicts, otherwise it completely fails. Another policy might be eventually-consistent in
the sense that the changes in every batch operations will eventually be applied, though
this may require the server to have application-specific conflict resolution logic. And
there are policies that are somewhere in-between. For example, imagine a server that
supports “public” collections whose entities can be read/updated by any user, and
“private” collections that expose only the entities that are readable and editable by that
user. The likelihood of a concurrent update conflict on a private entity is quite small,
since it’s possible only when different changes made on different devices are submitted at
exactly the same time. On the other hand, the likelihood of a concurrent update conflict
on a public entity is much higher. The server may allow updates to both public and private
entities within a single batch operation, and a save policy that might update all private
entities atomically (they all succeed or they all fail) while updates to *each* public
entity is atomic (some might succeed while others might fail).
Any given server will likely support only a few of these policies. But either way, the
server has to report back to the client the outcome of the batch request: which entities
were updated, which were not, and the reason why each of the rejected updates failed
(because other entity changes were rejected, because of a conflict, etc.). The SDK’s Data
Sync functionality would use those results to know how to update the local persisted
representations, and to start trying to resolve any failures.
The kinds of requests needed to support data sync in this scenario are fairly basic, so
the server doesn’t have to be that complicated. Best of all, the server is not required to
maintain any client-specific state.
Thoughts? Am I way off-base?
Best regards,
Randall
On Sep 4, 2014, at 10:38 AM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
Hey guys,
TL;DR: there are ways how to make the memory footprint of Differential Synchronization
(DS) very low; if we assume that JSON patches are reversible and we create cumulative
patches from series of individual patches, we can use (smart, garbage-collactable)
revision control for storage of documents that server need to maintain.
----
I had an idea in my head that for couple of days as I was becoming familiar with how
Differential Synchronization (DS) works and studying Dan's and Luke's impl.
I share the concern that Randall expressed in earlier thread - the DS in its pure version
doesn't scale for huge amount of users when connected to one server.
Sure, the algorithm can be scaled trivially by adding new nodes that uses very same
algorithm as is used for client<->server. But that doesn't mean it is something
that we should do regularly to get more memory available.
Instead, I was thinking about limiting a memory that server needs to maintain in any
point in time.
In pure DS, server have to maintain all copies of documents that clients ever requested.
Even worse, it has to maintain two copies - "shadow" and "backup",
So, in worst case, 2 x N copies of document will be maintained by the server for N
clients.
-----
The DS algorithm doesn't tell us how the "shadow" and "backup"
documents should be stored.
We can transparently plug in a storage that will be clever about how to use
"backups" and "shadow".
-----
CONCEPTS:
1) REVISION CONTROL
In order to limit a number of documents we need to maintain in server's memory, we
can come with a system where just last known state is remembered in full version. Together
with last known version, we remember also history of the document for each revision as it
was patched by clients.
But server doesn't have to maintain full history of the document, it maintains just
revisions that are known to its clients (that revision is known by DS for each client out
of the box).
2) GARBAGE COLLECTION
Server trivially knows what versions are mantained by client, so it can get rid of those
revisions that are no longer needed.
First, it can cut all the history that is older than the oldest version of document
throughout all its clients.
Secondly, it can accumulate the serious of patches between states so that it doesn't
have to maintain full history, but just revisions that is known to any of those clients.
----
DIAGRAM:
I've attached a picture for illustration of the revision control / garbage
collection, it does not illustrate algorithm itself (Dan did awesome job describing DS
here [3]).
In the attached diagram, you can see four clients with different revisions:
Client 1: revision X
Client 2: revision X+3
Client 3: revision X+3
Client 4: revision X+4
If any of the clients reaches server, server can reconstruct the document (shadow and
backup) for given client revision and the DS algorithm then can operate as normally
(that's why it is transparent from algorithmic point of view).
If server comes to garbage collection, it can scan through available client revisions. As
it identifies, that the oldest known revision is X, it can remove patch for X-1 and less
as they are no longer needed.
Later, it can even more optimize, and accumulate patches so that the only information he
knows is how to get to the revision for each participating client. In the picture, he can
compute cumulative patch for getting from state X to state X+3, as X+1 and X+2 themselves
are not needed.
(Patch accumulation is actually something that Google Wave does in its Operational
Transformation implementation, just there it is called cumulative Operations).
----
Then it comes to caching strategies, you can maintain caches of things like last recently
used revisions (they don't need to be computed each time). You can store some
documents and their revision history to the disk (fully or partially), etc.
----
THE USE CASE:
1000 employees maintain one document - Contact List - on their smartphones
400 of those employees has mobile data plan, so they want to synchronize almost
immediately as they are notified about changes. The rest of the devices is connected
rather sparely.
If one employee changes data, 600 devices are notified about the change immediately (some
on data plan, some through Wifi, etc.) Those clients all have version say X+3, because
they are synchronized proactively.
These clients reach the server in say <10 seconds after that employee did the change.
First client reaches server and ask for version X+3 (it probably is still in the memory,
but if it isn't, it is deconstructed and placed into MRU cache). All of the others
reaches the server and re-synchronize themselves against the one copy of backup/shadow
that is in the memory already.
The other clients will reach the server later, as they are connecting to Wifi, say in 5
minutes to 24 hours. They will have even older versions, such as X. Those clients will
require more computation, but at the end the server can resolve them and through their
revisions out of the window.
At the end, there are clients that didn't connected for days, maybe months - I
suggest we don't actually use DS here and fallback to e.g. slow synchronization (show
me what you have, I will show you mine), because maintaining full history for longer
period of days may be too resource demanding (configurable?).
Obviously, 1000 is not much, but this can scale to pretty decent numbers if we use hybrid
approach (fallback to other sync strategies if revision is already forgotten by a
server).
----
WORST CASE:
we still have to maintain all the document revisions, but practically it won't happen
:-)
----
ASSUMPTIONS:
1. patches are reversible (we are able to compute reverse patch for each patch sent by
client)
2. patches are cumulative (we are able to compute aggregated patch from series of
patches)
For 1, it seems many of JSON-patch libraries actually implement it (Java, JavaScript) [1,
2]
For 2, it again seems some libraries implement it and if not, we can implement it or even
use brute-force - compute a patch between two documents
----
It's not the only way how to make it scale, but it does solve the problem pretty
independently of the DS algorithm and still leaves the algorithm clean and simple.
Cheers,
~ Lukas
[1] https://github.com/fge/json-patch
[2] https://github.com/benjamine/jsondiffpatch
<DS-revision-control.png>_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
4:04 a.m.
What happens when a client on a mobile device loses its connection for
a short period of time and then reconnects?
The edits/patches/operations on the
client would be stacked up and
later when an connection is available that stack of
edits/patches/operations would be sent to the server.
What if load balancing cause the client to reconnect to a different
process in the cluster?
If we allow for different types of what we currently call a
DataStore
to be pluggable, then it would be possible for that client to
reconnect to a different instance with the assumption here that the
underlying datastore is distributed.
BTW, please tell me if the whole purpose of AeroGear's Data Sync
feature is to satisfy this and only this scenario. If so, then I apologize for being a
distraction.)
No, it is not the only scenario. We want to satisfy as many scenarios
as possible, but we also have to start somewhere and preferable start
small and build out from there. In the roadmap, we outlined as the
first steps what is called conflict resolution. This is what our
initial focus will be on and it will require minimal server side
changes to existing server application (no server side state for
clients). Our hope is that doing this might gain us some early
adopters. This does not rule out that this could not be evolve into
something like you've described in you email above, more about this
later.
If the client goes offline and then back online, the Data Sync
functionality in the SDK would figure out which of the local entities the client has
changed, and request from the server the latest revisions for each of them. Data Sync then
merges the local changes onto the latest revisions (perhaps asking the user to manually
resolve anything that cannot be automatically resolved), computes the new effective
changes, and then sends a single batch request to the server to apply them. Some, all or
none changes are accepted, and likely the application then has to decide whether to
continue the process again, revert to the server’s versions, etc.
This sounds
simliar to what we have discussed as conflict resolution
in the Data Sync roadmap. It differs somewhat, like we don't specify
anything with regard to batches as the goal it to limit the changes
need for existing server implementations, in that the server only
detects a conflict and does not try to apply any effective
changes/operations/patches but instead works with complete
objects/documents.
The SDK would also make use of subscriptions/notifications so that it
can be told immediately when entities are changed.
This is considered as a later
part of conflict resolution where we
notifications are planned to be used.
The kinds of requests needed to support data sync in this scenario are
fairly basic, so the server doesn’t have to be that complicated. Best of all, the server
is not required to maintain any client-specific state.
This does sound like what we
are trying to do with the conflict
resolution approach. I know that it is even more basic than what you
have described here but we could extend the roadmap to include such
features.
I think there will be use cases for both the conflict resolution and
the data sync approaches and users that might be quite happy with
conflict resolution. I think it would make sense to split the two
roadmaps/specs into separate ones. At the moment it looks, and was the
original idea, that this would involve into the "real-time" datasync
solution. But have these separate would hopefully make this clear that
these are independent and can evolve independently.
Does this sound alright with everyone?
Thanks,
/Dan
On 5 September 2014 20:32, Randall Hauch <rhauch(a)redhat.com> wrote:
This does sounds quite interesting, Lukáš. If AeroGear uses
Differential
Synchronization, this approach might make it more efficient for the server
to implement the behavior.
But I’m still bothered by the thought that AeroGear’s Data Sync feature
uses any algorithm that requires the server to maintain client-specific
state.
First of all, servers that maintain no client state across requests will
*always* scale much better than servers that maintain client-specific state
across requests. Maintaining client-specific state requires extra work,
consumes more memory, and complicates clustering, failover, and fault
tolerance.
Secondly, if a server is maintaining client-specific state, how long does
that client state have to be maintained before assuming the client is no
longer there? What happens when a client on a mobile device loses its
connection for a short period of time and then reconnects? What if load
balancing cause the client to reconnect to a different process in the
cluster? Bottom line is that it adds quite a bit of complexity.
Finally, I completely understand the benefits of using Differential
Synchronization where many clients are collaborating on a single document.
That’s the “collaborative editor” scenario, and surely there are apps that
need this functionality. I’m just not convinced that this is the most
common use case. In fact, I think it’s relatively uncommon, and I don’t
think LiveOak will support it in the near term. (BTW, please tell me if the
whole purpose of AeroGear's Data Sync feature is to satisfy this and only
this scenario. If so, then I apologize for being a distraction.)
My understanding of the Data Sync feature, though, is that it is should be
applicable to other scenarios. IMO, the far more common scenario is:
- The server manages (many) millions of small entities, each of which
is a domain-specific aggregate JSON document. Examples of different kinds
of entities include: customers, books, insurance claims, catalog items,
restaurants, purchases, tasks, etc. A single customer entity would
aggregate most/all the information about the customer, including the name,
phone numbers, addresses, profile information, domain-specific privileges
(e.g., authorized to log issues or call support), etc. Note that these
aggregate entities do not correspond to the entities in a traditional
RDBMS/JPA/Hibernate app, where you’d have much finer-grained records
(separate tables for customer, customer addresses, customer phone numbers,
customer privileges, etc.).
- At any point in time there may be 1Ks or 10Ks of clients reading
dozens of documents/entities and sending changes to some of them (likely in
batch operations). IOW, any one document might be concurrently modified by
a relatively small number of clients.
I think it’s possible to support Data Sync in this scenario while
maintaining no client-specific state on the server (other than while
processing a single request).
The Data Sync functionality of the SDK used in the clients would work with
local persistence and enable the app to function online or offline. This
includes making it possible to edit entities and create new entities while
offline, though it does not matter to Data Sync which subset of entities is
persisted locally. If the client goes offline and then back online, the
Data Sync functionality in the SDK would figure out which of the local
entities the client has changed, and request from the server the latest
revisions for each of them. Data Sync then merges the local changes onto
the latest revisions (perhaps asking the user to manually resolve anything
that cannot be automatically resolved), computes the new effective changes,
and then sends a single batch request to the server to apply them. Some,
all or none changes are accepted, and likely the application then has to
decide whether to continue the process again, revert to the server’s
versions, etc. (The SDK would also make use of subscriptions/notifications
so that it can be told immediately when entities are changed.)
What the batch operations entail is dependent upon the needs of the client
app and capabilities of the server. If a server supports batch operations
that contain the entire entity, then the server will almost certainly need
to put revision identifiers in each entity sent to the client, so that when
the client sends back a modified representation entity, the server can tell
whether that document has since been modified by another client. If so, the
server might rely upon client preferences (see below) to know whether to
merge the changes (using a simple algorithm or more useful
application-specific logic), overwrite, or fail to update the entity.
On the other hand, the server might support batch operations with partial
updates, where the client only sends for each entity only the set of fields
that are to be changed or removed. Conflicts and merging with this approach
are easier and less-likely to be application specific, though client
preferences (see below) might still dictate whether or not to merge based
upon revision numbers. It also might make it easier for Data Sync, since
the SDK simply has to record for each modified entity only those modified
fields (no matter how long the client was offline). To keep the SDK simple,
a best practice might be to ensure clients always modify together those
fields that must be consistent. For example, in a contacts application, if
a user modifies the first name of a contact, the app might tell the SDK to
modify the first name and last name fields, even though the user didn’t
modify the last name. When synchronized, both the first name and last name
fields would be sent to the server as a single update. This helps ensure
that even when multiple clients are concurrently updating the same set of
fields to different values, the result of applying all of those changes
will exactly match the state as set by one of the clients.
It’s also likely that for batch operations to work well for many different
kinds of applications, the server may support multiple policies that
specify for a given batch operation the atomicity, consistency, and
isolation guarantees. One policy might ensure that the entire batch either
completely succeeds only when there are no revision conflicts, otherwise it
completely fails. Another policy might be eventually-consistent in the
sense that the changes in every batch operations will eventually be
applied, though this may require the server to have application-specific
conflict resolution logic. And there are policies that are somewhere
in-between. For example, imagine a server that supports “public”
collections whose entities can be read/updated by any user, and “private”
collections that expose only the entities that are readable and editable by
that user. The likelihood of a concurrent update conflict on a private
entity is quite small, since it’s possible only when different changes made
on different devices are submitted at exactly the same time. On the other
hand, the likelihood of a concurrent update conflict on a public entity is
much higher. The server may allow updates to both public and private
entities within a single batch operation, and a save policy that might
update all private entities atomically (they all succeed or they all fail)
while updates to *each* public entity is atomic (some might succeed while
others might fail).
Any given server will likely support only a few of these policies. But
either way, the server has to report back to the client the outcome of the
batch request: which entities were updated, which were not, and the reason
why each of the rejected updates failed (because other entity changes were
rejected, because of a conflict, etc.). The SDK’s Data Sync functionality
would use those results to know how to update the local persisted
representations, and to start trying to resolve any failures.
The kinds of requests needed to support data sync in this scenario are
fairly basic, so the server doesn’t have to be that complicated. Best of
all, the server is not required to maintain any client-specific state.
Thoughts? Am I way off-base?
Best regards,
Randall
On Sep 4, 2014, at 10:38 AM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
Hey guys,
TL;DR: there are ways how to make the memory footprint of Differential
Synchronization (DS) very low; if we assume that JSON patches are
reversible and we create cumulative patches from series of individual
patches, we can use (smart, garbage-collactable) revision control for
storage of documents that server need to maintain.
----
I had an idea in my head that for couple of days as I was becoming
familiar with how Differential Synchronization (DS) works and studying
Dan's and Luke's impl.
I share the concern that Randall expressed in earlier thread - the DS in
its pure version doesn't scale for huge amount of users when connected to
one server.
Sure, the algorithm can be scaled trivially by adding new nodes that uses
very same algorithm as is used for client<->server. But that doesn't mean
it is something that we should do regularly to get more memory available.
Instead, I was thinking about limiting a memory that server needs to
maintain in any point in time.
In pure DS, server have to maintain all copies of documents that clients
ever requested. Even worse, it has to maintain two copies - "shadow" and
"backup",
So, in worst case, 2 x N copies of document will be maintained by the
server for N clients.
-----
The DS algorithm doesn't tell us how the "shadow" and "backup"
documents
should be stored.
We can transparently plug in a storage that will be clever about how to
use "backups" and "shadow".
-----
CONCEPTS:
1) REVISION CONTROL
In order to limit a number of documents we need to maintain in server's
memory, we can come with a system where just last known state is remembered
in full version. Together with last known version, we remember also history
of the document for each revision as it was patched by clients.
But server doesn't have to maintain full history of the document, it
maintains just revisions that are known to its clients (that revision is
known by DS for each client out of the box).
2) GARBAGE COLLECTION
Server trivially knows what versions are mantained by client, so it can
get rid of those revisions that are no longer needed.
First, it can cut all the history that is older than the oldest version of
document throughout all its clients.
Secondly, it can accumulate the serious of patches between states so that
it doesn't have to maintain full history, but just revisions that is known
to any of those clients.
----
DIAGRAM:
I've attached a picture for illustration of the revision control / garbage
collection, it does not illustrate algorithm itself (Dan did awesome job
describing DS here [3]).
In the attached diagram, you can see four clients with different revisions:
Client 1: revision X
Client 2: revision X+3
Client 3: revision X+3
Client 4: revision X+4
If any of the clients reaches server, server can reconstruct the document
(shadow and backup) for given client revision and the DS algorithm then can
operate as normally (that's why it is transparent from algorithmic point of
view).
If server comes to garbage collection, it can scan through available
client revisions. As it identifies, that the oldest known revision is X, it
can remove patch for X-1 and less as they are no longer needed.
Later, it can even more optimize, and accumulate patches so that the only
information he knows is how to get to the revision for each participating
client. In the picture, he can compute cumulative patch for getting from
state X to state X+3, as X+1 and X+2 themselves are not needed.
(Patch accumulation is actually something that Google Wave does in its
Operational Transformation implementation, just there it is called
cumulative Operations).
----
Then it comes to caching strategies, you can maintain caches of things
like last recently used revisions (they don't need to be computed each
time). You can store some documents and their revision history to the disk
(fully or partially), etc.
----
THE USE CASE:
1000 employees maintain one document - Contact List - on their smartphones
400 of those employees has mobile data plan, so they want to synchronize
almost immediately as they are notified about changes. The rest of the
devices is connected rather sparely.
If one employee changes data, 600 devices are notified about the change
immediately (some on data plan, some through Wifi, etc.) Those clients all
have version say X+3, because they are synchronized proactively.
These clients reach the server in say <10 seconds after that employee did
the change.
First client reaches server and ask for version X+3 (it probably is still
in the memory, but if it isn't, it is deconstructed and placed into MRU
cache). All of the others reaches the server and re-synchronize themselves
against the one copy of backup/shadow that is in the memory already.
The other clients will reach the server later, as they are connecting to
Wifi, say in 5 minutes to 24 hours. They will have even older versions,
such as X. Those clients will require more computation, but at the end the
server can resolve them and through their revisions out of the window.
At the end, there are clients that didn't connected for days, maybe months
- I suggest we don't actually use DS here and fallback to e.g. slow
synchronization (show me what you have, I will show you mine), because
maintaining full history for longer period of days may be too resource
demanding (configurable?).
Obviously, 1000 is not much, but this can scale to pretty decent numbers
if we use hybrid approach (fallback to other sync strategies if revision is
already forgotten by a server).
----
WORST CASE:
we still have to maintain all the document revisions, but practically it
won't happen :-)
----
ASSUMPTIONS:
1. patches are reversible (we are able to compute reverse patch for each
patch sent by client)
2. patches are cumulative (we are able to compute aggregated patch from
series of patches)
For 1, it seems many of JSON-patch libraries actually implement it (Java,
JavaScript) [1, 2]
For 2, it again seems some libraries implement it and if not, we can
implement it or even use brute-force - compute a patch between two documents
----
It's not the only way how to make it scale, but it does solve the problem
pretty independently of the DS algorithm and still leaves the algorithm
clean and simple.
Cheers,
~ Lukas
[1] https://github.com/fge/json-patch
[2] https://github.com/benjamine/jsondiffpatch
<DS-revision-control.png>_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
6:37 a.m.
On Mon, Sep 8, 2014 at 11:04 AM, Daniel Bevenius <daniel.bevenius(a)gmail.com>
wrote:
>What if load balancing cause the client to reconnect to a
different process in the cluster?
If we allow for different types of what we currently call a DataStore to be pluggable,
then it would be possible for that client to reconnect to a different instance with the
assumption here that the underlying datastore is distributed.
Yeah, the problem here will still be that Shadows/Backups themselves aren't
distributed - if failover or load balancing causes the client go to another
node in distributed DiffSync scenario, then we would lose a state.
What we can do?
* Sticky sessions?
* Having revision control distributed (Infinispan?)
At the end, a less effective-strategy (say SlowSync) can always be used as
a fallback!
> If the client goes offline and then back online, the Data Sync functionality in the
SDK would figure out which of the local entities the client has changed, and request from
the server the latest revisions for each of them. Data Sync then merges the local changes
onto the latest revisions (perhaps asking the user to manually resolve anything that
cannot be automatically resolved), computes the new effective changes, and then sends a
single batch request to the server to apply them. Some, all or none changes are accepted,
and likely the application then has to decide whether to continue the process again,
revert to the server’s versions, etc.
This sounds simliar to what we have discussed as conflict resolution in the Data Sync
roadmap. It differs somewhat, like we don't specify anything with regard to batches as
the goal it to limit the changes need for existing server implementations, in that the
server only detects a conflict and does not try to apply any effective
changes/operations/patches but instead works with complete objects/documents.
Right, we need to add batches to the roadmap (batches as a case for
reconnects after longer period of time).
What about second milestone?
I think there will be use cases for both the conflict resolution and the data sync
approaches and users that might be quite happy with conflict resolution. I think it would
make sense to split the two roadmaps/specs into separate ones. At the moment it looks, and
was the original idea, that this would involve into the "real-time" datasync
solution. But have these separate would hopefully make this clear that these are
independent and can evolve independently.
Yes, I agree that Data Sync can be conceptually split into two pieces:
1) Simple Data Sync (persistence (we already have it), conflict detection,
resolution, partial updates, batch updates, notifications)
2) Realtime Data Sync (+ with all the above)
The client APIs for those should be same.
It's likely that part of (1) can be reused in (2) and vice versa.
Does this sound alright with everyone?
Thanks,
/Dan
On 5 September 2014 20:32, Randall Hauch <rhauch(a)redhat.com> wrote:
> This does sounds quite interesting, Lukáš. If AeroGear uses Differential
> Synchronization, this approach might make it more efficient for the server
> to implement the behavior.
>
> But I’m still bothered by the thought that AeroGear’s Data Sync feature
> uses any algorithm that requires the server to maintain client-specific
> state.
>
> First of all, servers that maintain no client state across requests will
> *always* scale much better than servers that maintain client-specific state
> across requests. Maintaining client-specific state requires extra work,
> consumes more memory, and complicates clustering, failover, and fault
> tolerance.
>
> Secondly, if a server is maintaining client-specific state, how long does
> that client state have to be maintained before assuming the client is no
> longer there? What happens when a client on a mobile device loses its
> connection for a short period of time and then reconnects? What if load
> balancing cause the client to reconnect to a different process in the
> cluster? Bottom line is that it adds quite a bit of complexity.
>
> Finally, I completely understand the benefits of using Differential
> Synchronization where many clients are collaborating on a single document.
> That’s the “collaborative editor” scenario, and surely there are apps that
> need this functionality. I’m just not convinced that this is the most
> common use case. In fact, I think it’s relatively uncommon, and I don’t
> think LiveOak will support it in the near term. (BTW, please tell me if the
> whole purpose of AeroGear's Data Sync feature is to satisfy this and only
> this scenario. If so, then I apologize for being a distraction.)
>
> My understanding of the Data Sync feature, though, is that it is should
> be applicable to other scenarios. IMO, the far more common scenario is:
>
>
> - The server manages (many) millions of small entities, each of which
> is a domain-specific aggregate JSON document. Examples of different kinds
> of entities include: customers, books, insurance claims, catalog items,
> restaurants, purchases, tasks, etc. A single customer entity would
> aggregate most/all the information about the customer, including the name,
> phone numbers, addresses, profile information, domain-specific privileges
> (e.g., authorized to log issues or call support), etc. Note that these
> aggregate entities do not correspond to the entities in a traditional
> RDBMS/JPA/Hibernate app, where you’d have much finer-grained records
> (separate tables for customer, customer addresses, customer phone numbers,
> customer privileges, etc.).
> - At any point in time there may be 1Ks or 10Ks of clients reading
> dozens of documents/entities and sending changes to some of them (likely in
> batch operations). IOW, any one document might be concurrently modified by
> a relatively small number of clients.
>
>
> I think it’s possible to support Data Sync in this scenario while
> maintaining no client-specific state on the server (other than while
> processing a single request).
>
> The Data Sync functionality of the SDK used in the clients would work
> with local persistence and enable the app to function online or offline.
> This includes making it possible to edit entities and create new entities
> while offline, though it does not matter to Data Sync which subset of
> entities is persisted locally. If the client goes offline and then back
> online, the Data Sync functionality in the SDK would figure out which of
> the local entities the client has changed, and request from the server the
> latest revisions for each of them. Data Sync then merges the local changes
> onto the latest revisions (perhaps asking the user to manually resolve
> anything that cannot be automatically resolved), computes the new effective
> changes, and then sends a single batch request to the server to apply them.
> Some, all or none changes are accepted, and likely the application then has
> to decide whether to continue the process again, revert to the server’s
> versions, etc. (The SDK would also make use of subscriptions/notifications
> so that it can be told immediately when entities are changed.)
>
> What the batch operations entail is dependent upon the needs of the
> client app and capabilities of the server. If a server supports batch
> operations that contain the entire entity, then the server will almost
> certainly need to put revision identifiers in each entity sent to the
> client, so that when the client sends back a modified representation
> entity, the server can tell whether that document has since been modified
> by another client. If so, the server might rely upon client preferences
> (see below) to know whether to merge the changes (using a simple algorithm
> or more useful application-specific logic), overwrite, or fail to update
> the entity.
>
> On the other hand, the server might support batch operations with partial
> updates, where the client only sends for each entity only the set of fields
> that are to be changed or removed. Conflicts and merging with this approach
> are easier and less-likely to be application specific, though client
> preferences (see below) might still dictate whether or not to merge based
> upon revision numbers. It also might make it easier for Data Sync, since
> the SDK simply has to record for each modified entity only those modified
> fields (no matter how long the client was offline). To keep the SDK simple,
> a best practice might be to ensure clients always modify together those
> fields that must be consistent. For example, in a contacts application, if
> a user modifies the first name of a contact, the app might tell the SDK to
> modify the first name and last name fields, even though the user didn’t
> modify the last name. When synchronized, both the first name and last name
> fields would be sent to the server as a single update. This helps ensure
> that even when multiple clients are concurrently updating the same set of
> fields to different values, the result of applying all of those changes
> will exactly match the state as set by one of the clients.
>
> It’s also likely that for batch operations to work well for many
> different kinds of applications, the server may support multiple policies
> that specify for a given batch operation the atomicity, consistency, and
> isolation guarantees. One policy might ensure that the entire batch either
> completely succeeds only when there are no revision conflicts, otherwise it
> completely fails. Another policy might be eventually-consistent in the
> sense that the changes in every batch operations will eventually be
> applied, though this may require the server to have application-specific
> conflict resolution logic. And there are policies that are somewhere
> in-between. For example, imagine a server that supports “public”
> collections whose entities can be read/updated by any user, and “private”
> collections that expose only the entities that are readable and editable by
> that user. The likelihood of a concurrent update conflict on a private
> entity is quite small, since it’s possible only when different changes made
> on different devices are submitted at exactly the same time. On the other
> hand, the likelihood of a concurrent update conflict on a public entity is
> much higher. The server may allow updates to both public and private
> entities within a single batch operation, and a save policy that might
> update all private entities atomically (they all succeed or they all fail)
> while updates to *each* public entity is atomic (some might succeed while
> others might fail).
>
> Any given server will likely support only a few of these policies. But
> either way, the server has to report back to the client the outcome of the
> batch request: which entities were updated, which were not, and the reason
> why each of the rejected updates failed (because other entity changes were
> rejected, because of a conflict, etc.). The SDK’s Data Sync functionality
> would use those results to know how to update the local persisted
> representations, and to start trying to resolve any failures.
>
> The kinds of requests needed to support data sync in this scenario are
> fairly basic, so the server doesn’t have to be that complicated. Best of
> all, the server is not required to maintain any client-specific state.
>
> Thoughts? Am I way off-base?
>
> Best regards,
>
> Randall
>
>
>
>
> On Sep 4, 2014, at 10:38 AM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
>
> Hey guys,
>
>
> TL;DR: there are ways how to make the memory footprint of Differential
> Synchronization (DS) very low; if we assume that JSON patches are
> reversible and we create cumulative patches from series of individual
> patches, we can use (smart, garbage-collactable) revision control for
> storage of documents that server need to maintain.
>
> ----
>
> I had an idea in my head that for couple of days as I was becoming
> familiar with how Differential Synchronization (DS) works and studying
> Dan's and Luke's impl.
>
> I share the concern that Randall expressed in earlier thread - the DS in
> its pure version doesn't scale for huge amount of users when connected to
> one server.
>
> Sure, the algorithm can be scaled trivially by adding new nodes that uses
> very same algorithm as is used for client<->server. But that doesn't mean
> it is something that we should do regularly to get more memory available.
>
>
> Instead, I was thinking about limiting a memory that server needs to
> maintain in any point in time.
>
>
> In pure DS, server have to maintain all copies of documents that clients
> ever requested. Even worse, it has to maintain two copies - "shadow" and
> "backup",
>
> So, in worst case, 2 x N copies of document will be maintained by the
> server for N clients.
>
> -----
>
> The DS algorithm doesn't tell us how the "shadow" and
"backup" documents
> should be stored.
>
> We can transparently plug in a storage that will be clever about how to
> use "backups" and "shadow".
>
> -----
>
> CONCEPTS:
>
> 1) REVISION CONTROL
>
> In order to limit a number of documents we need to maintain in server's
> memory, we can come with a system where just last known state is remembered
> in full version. Together with last known version, we remember also history
> of the document for each revision as it was patched by clients.
>
> But server doesn't have to maintain full history of the document, it
> maintains just revisions that are known to its clients (that revision is
> known by DS for each client out of the box).
>
> 2) GARBAGE COLLECTION
>
> Server trivially knows what versions are mantained by client, so it can
> get rid of those revisions that are no longer needed.
>
> First, it can cut all the history that is older than the oldest version
> of document throughout all its clients.
>
> Secondly, it can accumulate the serious of patches between states so that
> it doesn't have to maintain full history, but just revisions that is known
> to any of those clients.
>
> ----
>
> DIAGRAM:
>
> I've attached a picture for illustration of the revision control /
> garbage collection, it does not illustrate algorithm itself (Dan did
> awesome job describing DS here [3]).
>
> In the attached diagram, you can see four clients with different
> revisions:
>
> Client 1: revision X
> Client 2: revision X+3
> Client 3: revision X+3
> Client 4: revision X+4
>
> If any of the clients reaches server, server can reconstruct the document
> (shadow and backup) for given client revision and the DS algorithm then can
> operate as normally (that's why it is transparent from algorithmic point of
> view).
>
> If server comes to garbage collection, it can scan through available
> client revisions. As it identifies, that the oldest known revision is X, it
> can remove patch for X-1 and less as they are no longer needed.
>
> Later, it can even more optimize, and accumulate patches so that the only
> information he knows is how to get to the revision for each participating
> client. In the picture, he can compute cumulative patch for getting from
> state X to state X+3, as X+1 and X+2 themselves are not needed.
>
> (Patch accumulation is actually something that Google Wave does in its
> Operational Transformation implementation, just there it is called
> cumulative Operations).
>
> ----
>
> Then it comes to caching strategies, you can maintain caches of things
> like last recently used revisions (they don't need to be computed each
> time). You can store some documents and their revision history to the disk
> (fully or partially), etc.
>
> ----
>
> THE USE CASE:
>
>
> 1000 employees maintain one document - Contact List - on their smartphones
>
> 400 of those employees has mobile data plan, so they want to synchronize
> almost immediately as they are notified about changes. The rest of the
> devices is connected rather sparely.
>
> If one employee changes data, 600 devices are notified about the change
> immediately (some on data plan, some through Wifi, etc.) Those clients all
> have version say X+3, because they are synchronized proactively.
>
> These clients reach the server in say <10 seconds after that employee did
> the change.
>
> First client reaches server and ask for version X+3 (it probably is still
> in the memory, but if it isn't, it is deconstructed and placed into MRU
> cache). All of the others reaches the server and re-synchronize themselves
> against the one copy of backup/shadow that is in the memory already.
>
> The other clients will reach the server later, as they are connecting to
> Wifi, say in 5 minutes to 24 hours. They will have even older versions,
> such as X. Those clients will require more computation, but at the end the
> server can resolve them and through their revisions out of the window.
>
> At the end, there are clients that didn't connected for days, maybe
> months - I suggest we don't actually use DS here and fallback to e.g. slow
> synchronization (show me what you have, I will show you mine), because
> maintaining full history for longer period of days may be too resource
> demanding (configurable?).
>
> Obviously, 1000 is not much, but this can scale to pretty decent numbers
> if we use hybrid approach (fallback to other sync strategies if revision is
> already forgotten by a server).
>
> ----
>
> WORST CASE:
>
> we still have to maintain all the document revisions, but practically it
> won't happen :-)
>
> ----
>
> ASSUMPTIONS:
>
> 1. patches are reversible (we are able to compute reverse patch for each
> patch sent by client)
> 2. patches are cumulative (we are able to compute aggregated patch from
> series of patches)
>
> For 1, it seems many of JSON-patch libraries actually implement it (Java,
> JavaScript) [1, 2]
>
> For 2, it again seems some libraries implement it and if not, we can
> implement it or even use brute-force - compute a patch between two documents
>
>
> ----
>
> It's not the only way how to make it scale, but it does solve the problem
> pretty independently of the DS algorithm and still leaves the algorithm
> clean and simple.
>
>
>
> Cheers,
>
> ~ Lukas
>
>
> [1] https://github.com/fge/json-patch
> [2] https://github.com/benjamine/jsondiffpatch
> <DS-revision-control.png>_______________________________________________
> aerogear-dev mailing list
> aerogear-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/aerogear-dev
>
>
>
> _______________________________________________
> aerogear-dev mailing list
> aerogear-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/aerogear-dev
>
_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
6:49 a.m.
Yeah, the problem here will still be that Shadows/Backups themselves
aren't distributed - if failover or load balancing causes the client go to
another node in distributed DiffSync scenario, then we would lose a state.
If the scenario of the document being stored in a distributed datastore
then so would the Shadow/Backups.
What about second milestone?
We can certainly add a second and
more milestones for additional features.
On 8 September 2014 13:37, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
On Mon, Sep 8, 2014 at 11:04 AM, Daniel Bevenius <
daniel.bevenius(a)gmail.com> wrote:
> >What if load balancing cause the client to reconnect to a different process in
the cluster?
> If we allow for different types of what we currently call a DataStore to be
pluggable, then it would be possible for that client to reconnect to a different instance
with the assumption here that the underlying datastore is distributed.
>
>
Yeah, the problem here will still be that Shadows/Backups themselves
aren't distributed - if failover or load balancing causes the client go to
another node in distributed DiffSync scenario, then we would lose a state.
What we can do?
* Sticky sessions?
* Having revision control distributed (Infinispan?)
At the end, a less effective-strategy (say SlowSync) can always be used as
a fallback!
>
>
> > If the client goes offline and then back online, the Data Sync functionality in
the SDK would figure out which of the local entities the client has changed, and request
from the server the latest revisions for each of them. Data Sync then merges the local
changes onto the latest revisions (perhaps asking the user to manually resolve anything
that cannot be automatically resolved), computes the new effective changes, and then
sends a single batch request to the server to apply them. Some, all or none changes are
accepted, and likely the application then has to decide whether to continue the process
again, revert to the server’s versions, etc.
> This sounds simliar to what we have discussed as conflict resolution in the Data Sync
roadmap. It differs somewhat, like we don't specify anything with regard to batches as
the goal it to limit the changes need for existing server implementations, in that the
server only detects a conflict and does not try to apply any effective
changes/operations/patches but instead works with complete objects/documents.
>
>
Right, we need to add batches to the roadmap (batches as a case for
reconnects after longer period of time).
What about second milestone?
>
> I think there will be use cases for both the conflict resolution and the data sync
approaches and users that might be quite happy with conflict resolution. I think it would
make sense to split the two roadmaps/specs into separate ones. At the moment it looks, and
was the original idea, that this would involve into the "real-time" datasync
solution. But have these separate would hopefully make this clear that these are
independent and can evolve independently.
>
>
Yes, I agree that Data Sync can be conceptually split into two pieces:
1) Simple Data Sync (persistence (we already have it), conflict detection,
resolution, partial updates, batch updates, notifications)
2) Realtime Data Sync (+ with all the above)
The client APIs for those should be same.
It's likely that part of (1) can be reused in (2) and vice versa.
> Does this sound alright with everyone?
>
> Thanks,
>
> /Dan
>
>
>
> On 5 September 2014 20:32, Randall Hauch <rhauch(a)redhat.com> wrote:
>
>> This does sounds quite interesting, Lukáš. If AeroGear uses Differential
>> Synchronization, this approach might make it more efficient for the server
>> to implement the behavior.
>>
>> But I’m still bothered by the thought that AeroGear’s Data Sync feature
>> uses any algorithm that requires the server to maintain client-specific
>> state.
>>
>> First of all, servers that maintain no client state across requests will
>> *always* scale much better than servers that maintain client-specific state
>> across requests. Maintaining client-specific state requires extra work,
>> consumes more memory, and complicates clustering, failover, and fault
>> tolerance.
>>
>> Secondly, if a server is maintaining client-specific state, how long
>> does that client state have to be maintained before assuming the client is
>> no longer there? What happens when a client on a mobile device loses its
>> connection for a short period of time and then reconnects? What if load
>> balancing cause the client to reconnect to a different process in the
>> cluster? Bottom line is that it adds quite a bit of complexity.
>>
>> Finally, I completely understand the benefits of using Differential
>> Synchronization where many clients are collaborating on a single document.
>> That’s the “collaborative editor” scenario, and surely there are apps that
>> need this functionality. I’m just not convinced that this is the most
>> common use case. In fact, I think it’s relatively uncommon, and I don’t
>> think LiveOak will support it in the near term. (BTW, please tell me if the
>> whole purpose of AeroGear's Data Sync feature is to satisfy this and only
>> this scenario. If so, then I apologize for being a distraction.)
>>
>> My understanding of the Data Sync feature, though, is that it is should
>> be applicable to other scenarios. IMO, the far more common scenario is:
>>
>>
>> - The server manages (many) millions of small entities, each of
>> which is a domain-specific aggregate JSON document. Examples of different
>> kinds of entities include: customers, books, insurance claims, catalog
>> items, restaurants, purchases, tasks, etc. A single customer entity would
>> aggregate most/all the information about the customer, including the name,
>> phone numbers, addresses, profile information, domain-specific privileges
>> (e.g., authorized to log issues or call support), etc. Note that these
>> aggregate entities do not correspond to the entities in a traditional
>> RDBMS/JPA/Hibernate app, where you’d have much finer-grained records
>> (separate tables for customer, customer addresses, customer phone numbers,
>> customer privileges, etc.).
>> - At any point in time there may be 1Ks or 10Ks of clients reading
>> dozens of documents/entities and sending changes to some of them (likely in
>> batch operations). IOW, any one document might be concurrently modified by
>> a relatively small number of clients.
>>
>>
>> I think it’s possible to support Data Sync in this scenario while
>> maintaining no client-specific state on the server (other than while
>> processing a single request).
>>
>> The Data Sync functionality of the SDK used in the clients would work
>> with local persistence and enable the app to function online or offline.
>> This includes making it possible to edit entities and create new entities
>> while offline, though it does not matter to Data Sync which subset of
>> entities is persisted locally. If the client goes offline and then back
>> online, the Data Sync functionality in the SDK would figure out which of
>> the local entities the client has changed, and request from the server the
>> latest revisions for each of them. Data Sync then merges the local changes
>> onto the latest revisions (perhaps asking the user to manually resolve
>> anything that cannot be automatically resolved), computes the new effective
>> changes, and then sends a single batch request to the server to apply them.
>> Some, all or none changes are accepted, and likely the application then has
>> to decide whether to continue the process again, revert to the server’s
>> versions, etc. (The SDK would also make use of subscriptions/notifications
>> so that it can be told immediately when entities are changed.)
>>
>> What the batch operations entail is dependent upon the needs of the
>> client app and capabilities of the server. If a server supports batch
>> operations that contain the entire entity, then the server will almost
>> certainly need to put revision identifiers in each entity sent to the
>> client, so that when the client sends back a modified representation
>> entity, the server can tell whether that document has since been modified
>> by another client. If so, the server might rely upon client preferences
>> (see below) to know whether to merge the changes (using a simple algorithm
>> or more useful application-specific logic), overwrite, or fail to update
>> the entity.
>>
>> On the other hand, the server might support batch operations with
>> partial updates, where the client only sends for each entity only the set
>> of fields that are to be changed or removed. Conflicts and merging with
>> this approach are easier and less-likely to be application specific, though
>> client preferences (see below) might still dictate whether or not to merge
>> based upon revision numbers. It also might make it easier for Data Sync,
>> since the SDK simply has to record for each modified entity only those
>> modified fields (no matter how long the client was offline). To keep the
>> SDK simple, a best practice might be to ensure clients always modify
>> together those fields that must be consistent. For example, in a contacts
>> application, if a user modifies the first name of a contact, the app might
>> tell the SDK to modify the first name and last name fields, even though the
>> user didn’t modify the last name. When synchronized, both the first name
>> and last name fields would be sent to the server as a single update. This
>> helps ensure that even when multiple clients are concurrently updating the
>> same set of fields to different values, the result of applying all of those
>> changes will exactly match the state as set by one of the clients.
>>
>> It’s also likely that for batch operations to work well for many
>> different kinds of applications, the server may support multiple policies
>> that specify for a given batch operation the atomicity, consistency, and
>> isolation guarantees. One policy might ensure that the entire batch either
>> completely succeeds only when there are no revision conflicts, otherwise it
>> completely fails. Another policy might be eventually-consistent in the
>> sense that the changes in every batch operations will eventually be
>> applied, though this may require the server to have application-specific
>> conflict resolution logic. And there are policies that are somewhere
>> in-between. For example, imagine a server that supports “public”
>> collections whose entities can be read/updated by any user, and “private”
>> collections that expose only the entities that are readable and editable by
>> that user. The likelihood of a concurrent update conflict on a private
>> entity is quite small, since it’s possible only when different changes made
>> on different devices are submitted at exactly the same time. On the other
>> hand, the likelihood of a concurrent update conflict on a public entity is
>> much higher. The server may allow updates to both public and private
>> entities within a single batch operation, and a save policy that might
>> update all private entities atomically (they all succeed or they all fail)
>> while updates to *each* public entity is atomic (some might succeed while
>> others might fail).
>>
>> Any given server will likely support only a few of these policies. But
>> either way, the server has to report back to the client the outcome of the
>> batch request: which entities were updated, which were not, and the reason
>> why each of the rejected updates failed (because other entity changes were
>> rejected, because of a conflict, etc.). The SDK’s Data Sync functionality
>> would use those results to know how to update the local persisted
>> representations, and to start trying to resolve any failures.
>>
>> The kinds of requests needed to support data sync in this scenario are
>> fairly basic, so the server doesn’t have to be that complicated. Best of
>> all, the server is not required to maintain any client-specific state.
>>
>> Thoughts? Am I way off-base?
>>
>> Best regards,
>>
>> Randall
>>
>>
>>
>>
>> On Sep 4, 2014, at 10:38 AM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
>>
>> Hey guys,
>>
>>
>> TL;DR: there are ways how to make the memory footprint of Differential
>> Synchronization (DS) very low; if we assume that JSON patches are
>> reversible and we create cumulative patches from series of individual
>> patches, we can use (smart, garbage-collactable) revision control for
>> storage of documents that server need to maintain.
>>
>> ----
>>
>> I had an idea in my head that for couple of days as I was becoming
>> familiar with how Differential Synchronization (DS) works and studying
>> Dan's and Luke's impl.
>>
>> I share the concern that Randall expressed in earlier thread - the DS in
>> its pure version doesn't scale for huge amount of users when connected to
>> one server.
>>
>> Sure, the algorithm can be scaled trivially by adding new nodes that
>> uses very same algorithm as is used for client<->server. But that
doesn't
>> mean it is something that we should do regularly to get more memory
>> available.
>>
>>
>> Instead, I was thinking about limiting a memory that server needs to
>> maintain in any point in time.
>>
>>
>> In pure DS, server have to maintain all copies of documents that clients
>> ever requested. Even worse, it has to maintain two copies - "shadow"
and
>> "backup",
>>
>> So, in worst case, 2 x N copies of document will be maintained by the
>> server for N clients.
>>
>> -----
>>
>> The DS algorithm doesn't tell us how the "shadow" and
"backup" documents
>> should be stored.
>>
>> We can transparently plug in a storage that will be clever about how to
>> use "backups" and "shadow".
>>
>> -----
>>
>> CONCEPTS:
>>
>> 1) REVISION CONTROL
>>
>> In order to limit a number of documents we need to maintain in server's
>> memory, we can come with a system where just last known state is remembered
>> in full version. Together with last known version, we remember also history
>> of the document for each revision as it was patched by clients.
>>
>> But server doesn't have to maintain full history of the document, it
>> maintains just revisions that are known to its clients (that revision is
>> known by DS for each client out of the box).
>>
>> 2) GARBAGE COLLECTION
>>
>> Server trivially knows what versions are mantained by client, so it can
>> get rid of those revisions that are no longer needed.
>>
>> First, it can cut all the history that is older than the oldest version
>> of document throughout all its clients.
>>
>> Secondly, it can accumulate the serious of patches between states so
>> that it doesn't have to maintain full history, but just revisions that is
>> known to any of those clients.
>>
>> ----
>>
>> DIAGRAM:
>>
>> I've attached a picture for illustration of the revision control /
>> garbage collection, it does not illustrate algorithm itself (Dan did
>> awesome job describing DS here [3]).
>>
>> In the attached diagram, you can see four clients with different
>> revisions:
>>
>> Client 1: revision X
>> Client 2: revision X+3
>> Client 3: revision X+3
>> Client 4: revision X+4
>>
>> If any of the clients reaches server, server can reconstruct the
>> document (shadow and backup) for given client revision and the DS algorithm
>> then can operate as normally (that's why it is transparent from algorithmic
>> point of view).
>>
>> If server comes to garbage collection, it can scan through available
>> client revisions. As it identifies, that the oldest known revision is X, it
>> can remove patch for X-1 and less as they are no longer needed.
>>
>> Later, it can even more optimize, and accumulate patches so that the
>> only information he knows is how to get to the revision for each
>> participating client. In the picture, he can compute cumulative patch for
>> getting from state X to state X+3, as X+1 and X+2 themselves are not needed.
>>
>> (Patch accumulation is actually something that Google Wave does in its
>> Operational Transformation implementation, just there it is called
>> cumulative Operations).
>>
>> ----
>>
>> Then it comes to caching strategies, you can maintain caches of things
>> like last recently used revisions (they don't need to be computed each
>> time). You can store some documents and their revision history to the disk
>> (fully or partially), etc.
>>
>> ----
>>
>> THE USE CASE:
>>
>>
>> 1000 employees maintain one document - Contact List - on their
>> smartphones
>>
>> 400 of those employees has mobile data plan, so they want to synchronize
>> almost immediately as they are notified about changes. The rest of the
>> devices is connected rather sparely.
>>
>> If one employee changes data, 600 devices are notified about the change
>> immediately (some on data plan, some through Wifi, etc.) Those clients all
>> have version say X+3, because they are synchronized proactively.
>>
>> These clients reach the server in say <10 seconds after that employee
>> did the change.
>>
>> First client reaches server and ask for version X+3 (it probably is
>> still in the memory, but if it isn't, it is deconstructed and placed into
>> MRU cache). All of the others reaches the server and re-synchronize
>> themselves against the one copy of backup/shadow that is in the memory
>> already.
>>
>> The other clients will reach the server later, as they are connecting to
>> Wifi, say in 5 minutes to 24 hours. They will have even older versions,
>> such as X. Those clients will require more computation, but at the end the
>> server can resolve them and through their revisions out of the window.
>>
>> At the end, there are clients that didn't connected for days, maybe
>> months - I suggest we don't actually use DS here and fallback to e.g. slow
>> synchronization (show me what you have, I will show you mine), because
>> maintaining full history for longer period of days may be too resource
>> demanding (configurable?).
>>
>> Obviously, 1000 is not much, but this can scale to pretty decent numbers
>> if we use hybrid approach (fallback to other sync strategies if revision is
>> already forgotten by a server).
>>
>> ----
>>
>> WORST CASE:
>>
>> we still have to maintain all the document revisions, but practically it
>> won't happen :-)
>>
>> ----
>>
>> ASSUMPTIONS:
>>
>> 1. patches are reversible (we are able to compute reverse patch for each
>> patch sent by client)
>> 2. patches are cumulative (we are able to compute aggregated patch from
>> series of patches)
>>
>> For 1, it seems many of JSON-patch libraries actually implement it
>> (Java, JavaScript) [1, 2]
>>
>> For 2, it again seems some libraries implement it and if not, we can
>> implement it or even use brute-force - compute a patch between two documents
>>
>>
>> ----
>>
>> It's not the only way how to make it scale, but it does solve the
>> problem pretty independently of the DS algorithm and still leaves the
>> algorithm clean and simple.
>>
>>
>>
>> Cheers,
>>
>> ~ Lukas
>>
>>
>> [1] https://github.com/fge/json-patch
>> [2] https://github.com/benjamine/jsondiffpatch
>> <DS-revision-control.png>_______________________________________________
>> aerogear-dev mailing list
>> aerogear-dev(a)lists.jboss.org
>> https://lists.jboss.org/mailman/listinfo/aerogear-dev
>>
>>
>>
>> _______________________________________________
>> aerogear-dev mailing list
>> aerogear-dev(a)lists.jboss.org
>> https://lists.jboss.org/mailman/listinfo/aerogear-dev
>>
>
>
> _______________________________________________
> aerogear-dev mailing list
> aerogear-dev(a)lists.jboss.org
> https://lists.jboss.org/mailman/listinfo/aerogear-dev
>
_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
9:14 a.m.
On Sep 8, 2014, at 4:04 AM, Daniel Bevenius <daniel.bevenius(a)gmail.com> wrote:
>What happens when a client on a mobile device loses its
connection for a short period of time and then reconnects?
The edits/patches/operations on the client would be stacked up and later when an
connection is available that stack of edits/patches/operations would be sent to the
server.
I more concerned about what happens in the server when a client on a mobile device loses
its connection. Server-side session management adds complexity and reduces scalability.
>What if load balancing cause the client to reconnect to a
different process in the cluster?
If we allow for different types of what we currently call a DataStore to be pluggable,
then it would be possible for that client to reconnect to a different instance with the
assumption here that the underlying datastore is distributed.
Sure, except doesn’t that presume that the server’s client states are distributed (or
distributable) or persisted? Again, this is more complexity creep.
>BTW, please tell me if the whole purpose of AeroGear's Data
Sync feature is to satisfy this and only this scenario. If so, then I apologize for being
a distraction.)
No, it is not the only scenario. We want to satisfy as many scenarios as possible, but we
also have to start somewhere and preferable start small and build out from there. In the
roadmap, we outlined as the first steps what is called conflict resolution. This is what
our initial focus will be on and it will require minimal server side changes to existing
server application (no server side state for clients). Our hope is that doing this might
gain us some early adopters. This does not rule out that this could not be evolve into
something like you've described in you email above, more about this later.
Yup, the conflict resolution first step is a great approach. It’s lightweight, and I think
Data Sync can do an awful lot with it. My hunch is that if a server supported it, then the
client-side SDK can add a lot of the features I was talking about earlier.
> If the client goes offline and then back online, the Data Sync functionality in the
SDK would figure out which of the local entities the client has changed, and request from
the server the latest revisions for each of them. Data Sync then merges the local changes
onto the latest revisions (perhaps asking the user to manually resolve anything that
cannot be automatically resolved), computes the new effective changes, and then sends a
single batch request to the server to apply them. Some, all or none changes are accepted,
and likely the application then has to decide whether to continue the process again,
revert to the server’s versions, etc.
This sounds simliar to what we have discussed as conflict resolution in the Data Sync
roadmap. It differs somewhat, like we don't specify anything with regard to batches as
the goal it to limit the changes need for existing server implementations, in that the
server only detects a conflict and does not try to apply any effective
changes/operations/patches but instead works with complete objects/documents.
Batches does complicate things, and they’re not needed right from the start. Using a batch
instead of multiple separate requests reduces network costs, and this is always important
in mobile. But it also allows the client to do control consistency and atomicity of their
updates. Without batches, some apps will just be harder to write and will have to have
logic that compensates for when one update request succeeded and a second did not.
>The SDK would also make use of subscriptions/notifications so that it can be told
immediately when entities are changed.
This is considered as a later part of conflict resolution where we notifications are
planned to be used.
Right. I was just trying to point out how it fits in to my scenario.
>The kinds of requests needed to support data sync in this scenario are fairly basic,
so the server doesn’t have to be that complicated. Best of all, the server is not required
to maintain any client-specific state.
This does sound like what we are trying to do with the conflict resolution approach. I
know that it is even more basic than what you have described here but we could extend the
roadmap to include such features.
+1.
I think there will be use cases for both the conflict resolution and
the data sync approaches and users that might be quite happy with conflict resolution. I
think it would make sense to split the two roadmaps/specs into separate ones. At the
moment it looks, and was the original idea, that this would involve into the
"real-time" datasync solution. But have these separate would hopefully make this
clear that these are independent and can evolve independently.
Does this sound alright with everyone?
That sounds good to me. I think they do target slightly different scenarios.
Thanks for the discussion!
5:23 a.m.
Thanks for great feedback, Randall!
*ad) Scalability*
Sure, I'm also worried about DiffSync being an algorithm that implies
statefulness.
But we must consider that only way how to make synchronization process
efficient always involves holding some state on server (be it e.g. revision
control).
*ad) AeroGear Data Sync == Differential Synchronization?*
DiffSync is not only solution we are working on, it is just the most
advanced one.
We have started its prototype early to give it a chance to settle down
(which may also mean figuring out it is totally inappropriate for any use
case we can about and abandoning the idea).
We are considering several approaches as outlined in the Data Sync module
roadmap from Dan [1]:
1. offline storage (we alreave have that) + conflict detection + conflict
resolution
2. realtime updates
3. realtime synchronization
It seems that most of the concerns you've mentioned are covered by (1) and
that you highlight the importance to get the APIs we are working on in (1)
right.
That's right and that's exactly the feedback we need at this stage!
Solution (2) is extension to (1) that makes sure that clients are updated
periodically and so that conflicts happen less often.
Solution (3) is extension to (1) and (2) that allows framework to implement
efficient synchronization and realtime collaboration.
While DiffSync makes conflicts less often, there will always be cases when
API for (1) will matter a lot.
The API for conflict resolution will be a crucial part, especially
considering UI feedback when conflict need to be resolved by an app user
himself.
*ad) Relevance for various use cases*
I completely agree that Differential Synchronization seems a most valid in
a case of collaboration on bigger documents.
(Note: that's exactly how, lets say Firebase works - you have a huge
unstructured document that all of the connected parties can freely modify,
while rest of the clients are notified about changes in realtime)
DiffSync gives us perfect case for studying a JSON patching strategy that
may be base for similar, but better scalable solutions.
We have to balance between several concerns Data Sync is connected with
(not necessarily complete list):
1. efficiency of synchronization
2. statefulness / scalability
3. first sync after longer period of disconnection (aka batches)
4. prioritization of sync after reconnect (aka slow network connection)
5. simplicity of adoption
DiffSync ensures (1) and (3). Slow sync (simple conflict detection +
resolution) ensures (2) out of the box.
The huge variable part here is (5). I'm very interested in (5).
To satisfy all these needs we may build several different, handshake /
data-exchange protocols that will make sure all the use cases are covered,
and it may be a hybrid approach that will make AeroGear Data Sync relevant
in all cases. One protocol can be fallback to another.
Such a hybrid solution depends on the application developer what approach
he will choose to take (it can be even multiple approaches in one app).
We will leave a space for customization by configuration (and plugins).
E.g. let's configure how long the document synced with DiffSync (say JSON
array of company employees) will be held on the server before it will
expire and you fallback to Slow Sync (solution (1) on the roadmap).
Thanks for the feedback!
Cheers,
~ Lukas
[1]
https://github.com/danbev/beta.aerogear.org/blob/data-sync-rebirth-roadma...
On Fri, Sep 5, 2014 at 8:32 PM, Randall Hauch <rhauch(a)redhat.com> wrote:
This does sounds quite interesting, Lukáš. If AeroGear uses
Differential
Synchronization, this approach might make it more efficient for the server
to implement the behavior.
But I’m still bothered by the thought that AeroGear’s Data Sync feature
uses any algorithm that requires the server to maintain client-specific
state.
First of all, servers that maintain no client state across requests will
*always* scale much better than servers that maintain client-specific state
across requests. Maintaining client-specific state requires extra work,
consumes more memory, and complicates clustering, failover, and fault
tolerance.
Secondly, if a server is maintaining client-specific state, how long does
that client state have to be maintained before assuming the client is no
longer there? What happens when a client on a mobile device loses its
connection for a short period of time and then reconnects? What if load
balancing cause the client to reconnect to a different process in the
cluster? Bottom line is that it adds quite a bit of complexity.
Finally, I completely understand the benefits of using Differential
Synchronization where many clients are collaborating on a single document.
That’s the “collaborative editor” scenario, and surely there are apps that
need this functionality. I’m just not convinced that this is the most
common use case. In fact, I think it’s relatively uncommon, and I don’t
think LiveOak will support it in the near term. (BTW, please tell me if the
whole purpose of AeroGear's Data Sync feature is to satisfy this and only
this scenario. If so, then I apologize for being a distraction.)
My understanding of the Data Sync feature, though, is that it is should be
applicable to other scenarios. IMO, the far more common scenario is:
- The server manages (many) millions of small entities, each of which
is a domain-specific aggregate JSON document. Examples of different kinds
of entities include: customers, books, insurance claims, catalog items,
restaurants, purchases, tasks, etc. A single customer entity would
aggregate most/all the information about the customer, including the name,
phone numbers, addresses, profile information, domain-specific privileges
(e.g., authorized to log issues or call support), etc. Note that these
aggregate entities do not correspond to the entities in a traditional
RDBMS/JPA/Hibernate app, where you’d have much finer-grained records
(separate tables for customer, customer addresses, customer phone numbers,
customer privileges, etc.).
- At any point in time there may be 1Ks or 10Ks of clients reading
dozens of documents/entities and sending changes to some of them (likely in
batch operations). IOW, any one document might be concurrently modified by
a relatively small number of clients.
I think it’s possible to support Data Sync in this scenario while
maintaining no client-specific state on the server (other than while
processing a single request).
The Data Sync functionality of the SDK used in the clients would work with
local persistence and enable the app to function online or offline. This
includes making it possible to edit entities and create new entities while
offline, though it does not matter to Data Sync which subset of entities is
persisted locally. If the client goes offline and then back online, the
Data Sync functionality in the SDK would figure out which of the local
entities the client has changed, and request from the server the latest
revisions for each of them. Data Sync then merges the local changes onto
the latest revisions (perhaps asking the user to manually resolve anything
that cannot be automatically resolved), computes the new effective changes,
and then sends a single batch request to the server to apply them. Some,
all or none changes are accepted, and likely the application then has to
decide whether to continue the process again, revert to the server’s
versions, etc. (The SDK would also make use of subscriptions/notifications
so that it can be told immediately when entities are changed.)
What the batch operations entail is dependent upon the needs of the client
app and capabilities of the server. If a server supports batch operations
that contain the entire entity, then the server will almost certainly need
to put revision identifiers in each entity sent to the client, so that when
the client sends back a modified representation entity, the server can tell
whether that document has since been modified by another client. If so, the
server might rely upon client preferences (see below) to know whether to
merge the changes (using a simple algorithm or more useful
application-specific logic), overwrite, or fail to update the entity.
On the other hand, the server might support batch operations with partial
updates, where the client only sends for each entity only the set of fields
that are to be changed or removed. Conflicts and merging with this approach
are easier and less-likely to be application specific, though client
preferences (see below) might still dictate whether or not to merge based
upon revision numbers. It also might make it easier for Data Sync, since
the SDK simply has to record for each modified entity only those modified
fields (no matter how long the client was offline). To keep the SDK simple,
a best practice might be to ensure clients always modify together those
fields that must be consistent. For example, in a contacts application, if
a user modifies the first name of a contact, the app might tell the SDK to
modify the first name and last name fields, even though the user didn’t
modify the last name. When synchronized, both the first name and last name
fields would be sent to the server as a single update. This helps ensure
that even when multiple clients are concurrently updating the same set of
fields to different values, the result of applying all of those changes
will exactly match the state as set by one of the clients.
It’s also likely that for batch operations to work well for many different
kinds of applications, the server may support multiple policies that
specify for a given batch operation the atomicity, consistency, and
isolation guarantees. One policy might ensure that the entire batch either
completely succeeds only when there are no revision conflicts, otherwise it
completely fails. Another policy might be eventually-consistent in the
sense that the changes in every batch operations will eventually be
applied, though this may require the server to have application-specific
conflict resolution logic. And there are policies that are somewhere
in-between. For example, imagine a server that supports “public”
collections whose entities can be read/updated by any user, and “private”
collections that expose only the entities that are readable and editable by
that user. The likelihood of a concurrent update conflict on a private
entity is quite small, since it’s possible only when different changes made
on different devices are submitted at exactly the same time. On the other
hand, the likelihood of a concurrent update conflict on a public entity is
much higher. The server may allow updates to both public and private
entities within a single batch operation, and a save policy that might
update all private entities atomically (they all succeed or they all fail)
while updates to *each* public entity is atomic (some might succeed while
others might fail).
Any given server will likely support only a few of these policies. But
either way, the server has to report back to the client the outcome of the
batch request: which entities were updated, which were not, and the reason
why each of the rejected updates failed (because other entity changes were
rejected, because of a conflict, etc.). The SDK’s Data Sync functionality
would use those results to know how to update the local persisted
representations, and to start trying to resolve any failures.
The kinds of requests needed to support data sync in this scenario are
fairly basic, so the server doesn’t have to be that complicated. Best of
all, the server is not required to maintain any client-specific state.
Thoughts? Am I way off-base?
Best regards,
Randall
On Sep 4, 2014, at 10:38 AM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
Hey guys,
TL;DR: there are ways how to make the memory footprint of Differential
Synchronization (DS) very low; if we assume that JSON patches are
reversible and we create cumulative patches from series of individual
patches, we can use (smart, garbage-collactable) revision control for
storage of documents that server need to maintain.
----
I had an idea in my head that for couple of days as I was becoming
familiar with how Differential Synchronization (DS) works and studying
Dan's and Luke's impl.
I share the concern that Randall expressed in earlier thread - the DS in
its pure version doesn't scale for huge amount of users when connected to
one server.
Sure, the algorithm can be scaled trivially by adding new nodes that uses
very same algorithm as is used for client<->server. But that doesn't mean
it is something that we should do regularly to get more memory available.
Instead, I was thinking about limiting a memory that server needs to
maintain in any point in time.
In pure DS, server have to maintain all copies of documents that clients
ever requested. Even worse, it has to maintain two copies - "shadow" and
"backup",
So, in worst case, 2 x N copies of document will be maintained by the
server for N clients.
-----
The DS algorithm doesn't tell us how the "shadow" and "backup"
documents
should be stored.
We can transparently plug in a storage that will be clever about how to
use "backups" and "shadow".
-----
CONCEPTS:
1) REVISION CONTROL
In order to limit a number of documents we need to maintain in server's
memory, we can come with a system where just last known state is remembered
in full version. Together with last known version, we remember also history
of the document for each revision as it was patched by clients.
But server doesn't have to maintain full history of the document, it
maintains just revisions that are known to its clients (that revision is
known by DS for each client out of the box).
2) GARBAGE COLLECTION
Server trivially knows what versions are mantained by client, so it can
get rid of those revisions that are no longer needed.
First, it can cut all the history that is older than the oldest version of
document throughout all its clients.
Secondly, it can accumulate the serious of patches between states so that
it doesn't have to maintain full history, but just revisions that is known
to any of those clients.
----
DIAGRAM:
I've attached a picture for illustration of the revision control / garbage
collection, it does not illustrate algorithm itself (Dan did awesome job
describing DS here [3]).
In the attached diagram, you can see four clients with different revisions:
Client 1: revision X
Client 2: revision X+3
Client 3: revision X+3
Client 4: revision X+4
If any of the clients reaches server, server can reconstruct the document
(shadow and backup) for given client revision and the DS algorithm then can
operate as normally (that's why it is transparent from algorithmic point of
view).
If server comes to garbage collection, it can scan through available
client revisions. As it identifies, that the oldest known revision is X, it
can remove patch for X-1 and less as they are no longer needed.
Later, it can even more optimize, and accumulate patches so that the only
information he knows is how to get to the revision for each participating
client. In the picture, he can compute cumulative patch for getting from
state X to state X+3, as X+1 and X+2 themselves are not needed.
(Patch accumulation is actually something that Google Wave does in its
Operational Transformation implementation, just there it is called
cumulative Operations).
----
Then it comes to caching strategies, you can maintain caches of things
like last recently used revisions (they don't need to be computed each
time). You can store some documents and their revision history to the disk
(fully or partially), etc.
----
THE USE CASE:
1000 employees maintain one document - Contact List - on their smartphones
400 of those employees has mobile data plan, so they want to synchronize
almost immediately as they are notified about changes. The rest of the
devices is connected rather sparely.
If one employee changes data, 600 devices are notified about the change
immediately (some on data plan, some through Wifi, etc.) Those clients all
have version say X+3, because they are synchronized proactively.
These clients reach the server in say <10 seconds after that employee did
the change.
First client reaches server and ask for version X+3 (it probably is still
in the memory, but if it isn't, it is deconstructed and placed into MRU
cache). All of the others reaches the server and re-synchronize themselves
against the one copy of backup/shadow that is in the memory already.
The other clients will reach the server later, as they are connecting to
Wifi, say in 5 minutes to 24 hours. They will have even older versions,
such as X. Those clients will require more computation, but at the end the
server can resolve them and through their revisions out of the window.
At the end, there are clients that didn't connected for days, maybe months
- I suggest we don't actually use DS here and fallback to e.g. slow
synchronization (show me what you have, I will show you mine), because
maintaining full history for longer period of days may be too resource
demanding (configurable?).
Obviously, 1000 is not much, but this can scale to pretty decent numbers
if we use hybrid approach (fallback to other sync strategies if revision is
already forgotten by a server).
----
WORST CASE:
we still have to maintain all the document revisions, but practically it
won't happen :-)
----
ASSUMPTIONS:
1. patches are reversible (we are able to compute reverse patch for each
patch sent by client)
2. patches are cumulative (we are able to compute aggregated patch from
series of patches)
For 1, it seems many of JSON-patch libraries actually implement it (Java,
JavaScript) [1, 2]
For 2, it again seems some libraries implement it and if not, we can
implement it or even use brute-force - compute a patch between two documents
----
It's not the only way how to make it scale, but it does solve the problem
pretty independently of the DS algorithm and still leaves the algorithm
clean and simple.
Cheers,
~ Lukas
[1] https://github.com/fge/json-patch
[2] https://github.com/benjamine/jsondiffpatch
<DS-revision-control.png>_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
_______________________________________________
aerogear-dev mailing list
aerogear-dev(a)lists.jboss.org
https://lists.jboss.org/mailman/listinfo/aerogear-dev
5:33 a.m.
On Fri, Sep 5, 2014 at 8:32 PM, Randall Hauch <rhauch(a)redhat.com> wrote:
It’s also likely that for batch operations to work well for many different
kinds of applications, the server may support multiple policies that
specify for a given batch operation the atomicity, consistency, and
isolation guarantees. One policy might ensure that the entire batch either
completely succeeds only when there are no revision conflicts, otherwise it
completely fails. Another policy might be eventually-consistent in the
sense that the changes in every batch operations will eventually be
applied, though this may require the server to have application-specific
conflict resolution logic. And there are policies that are somewhere
in-between. For example, imagine a server that supports “public”
collections whose entities can be read/updated by any user, and “private”
collections that expose only the entities that are readable and editable by
that user. The likelihood of a concurrent update conflict on a private
entity is quite small, since it’s possible only when different changes made
on different devices are submitted at exactly the same time. On the other
hand, the likelihood of a concurrent update conflict on a public entity is
much higher. The server may allow updates to both public and private
entities within a single batch operation, and a save policy that might
update all private entities atomically (they all succeed or they all fail)
while updates to *each* public entity is atomic (some might succeed while
others might fail).
I don't believe LiveOak ensure ACID guarantees (at least not on batch
update level; correct me if I'm wrong), and I don't think we should start
with that.
Any given REST call that leads to updating more than one endpoint is not
atomic anymore.
I would rather say that whole Data Sync is eventually consistent solution
(at least in its first versions).
Sure, app/user will know that there is a conflict on one of the updated
entities (and we may provide an API to make the resolution easier), but it
will be up to him to resolve it.
Or am I wrong?
5:35 a.m.
Oh, sorry for two answers, I noticed Dan already answered to some concerns
already. :-)
On Mon, Sep 8, 2014 at 12:33 PM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
On Fri, Sep 5, 2014 at 8:32 PM, Randall Hauch <rhauch(a)redhat.com> wrote:
>
>
> It’s also likely that for batch operations to work well for many
> different kinds of applications, the server may support multiple policies
> that specify for a given batch operation the atomicity, consistency, and
> isolation guarantees. One policy might ensure that the entire batch either
> completely succeeds only when there are no revision conflicts, otherwise it
> completely fails. Another policy might be eventually-consistent in the
> sense that the changes in every batch operations will eventually be
> applied, though this may require the server to have application-specific
> conflict resolution logic. And there are policies that are somewhere
> in-between. For example, imagine a server that supports “public”
> collections whose entities can be read/updated by any user, and “private”
> collections that expose only the entities that are readable and editable by
> that user. The likelihood of a concurrent update conflict on a private
> entity is quite small, since it’s possible only when different changes made
> on different devices are submitted at exactly the same time. On the other
> hand, the likelihood of a concurrent update conflict on a public entity is
> much higher. The server may allow updates to both public and private
> entities within a single batch operation, and a save policy that might
> update all private entities atomically (they all succeed or they all fail)
> while updates to *each* public entity is atomic (some might succeed while
> others might fail).
>
I don't believe LiveOak ensure ACID guarantees (at least not on batch
update level; correct me if I'm wrong), and I don't think we should start
with that.
Any given REST call that leads to updating more than one endpoint is not
atomic anymore.
I would rather say that whole Data Sync is eventually consistent solution
(at least in its first versions).
Sure, app/user will know that there is a conflict on one of the updated
entities (and we may provide an API to make the resolution easier), but it
will be up to him to resolve it.
Or am I wrong?
9:21 a.m.
On Sep 8, 2014, at 5:33 AM, Lukáš Fryč <lukas.fryc(a)gmail.com> wrote:
I don't believe LiveOak ensure ACID guarantees (at least not on
batch update level; correct me if I'm wrong), and I don't think we should start
with that.
Any given REST call that leads to updating more than one endpoint is not atomic anymore.
IIUC, LiveOak’s batches are essentially just a set of operations each performed
atomically.
I am going to start looking at several longer-lead things in LiveOak, including batch
operations with predefined policies that dictate whether the operations in the batch are
consistent, atomic, and isolated.
I would rather say that whole Data Sync is eventually consistent solution (at least in
its first versions).
Sure, app/user will know that there is a conflict on one of the updated entities (and we
may provide an API to make the resolution easier), but it will be up to him to resolve
it.
Or am I wrong?
It sounds like this may be the case early on, with the conflict resolution approach.
Hopefully, support for batches can eventually be added, and if so then apps can rely less
(hopefully far less) on the user for deconflicting data.
4334
days inactive
4338
days old
10 comments
3 participants
participants (3)
-
 Daniel Bevenius
Daniel Bevenius -
 Lukáš Fryč
Lukáš Fryč -
 Randall Hauch
Randall Hauch